Spring Batch Overview
Despite the growing momentum behind SOA and real-time integration, many interfaces are still flat file-based and therefore best processed through a batch mode. Nevertheless, there is no de facto or industry-standard approach to Java-based batch architectures. Batch processing seems to be a critical, missing architectural style and capability in the marketplace.
A Missing Enterprise Capability
Despite the growing momentum behind SOA and real-time integration, many interfaces are still flat file-based and therefore best processed through a batch mode. Nevertheless, there is no de facto or industry-standard approach to Java-based batch architectures. Batch processing seems to be a critical, missing architectural style and capability in the marketplace. Consider that:
- Batch processing is used to process billions of transactions everyday within mission-critical enterprise applications.
- Although batch jobs are part of most IT projects, there is no widely-adopted commercial or open source java framework to provide a robust, enterprise-scale solution.
- Lack of a standard architecture results in the proliferation of expensive one-off, in-house custom architectures.
- Although there is a lack of standard architectures for batch, there is decades-worth of experience in building high-performance batch solutions.
Spring Batch was started with the goal of addressing this missing capability by creating an open source project that can be offered as a hopeful batch processing standard within the Java community.
The Spring Batch Architecture
The Spring Batch architecture is layered to provide a great deal of freedom to application architectures, as well as to provide batch execution environments. This can be illustrated in the following way:
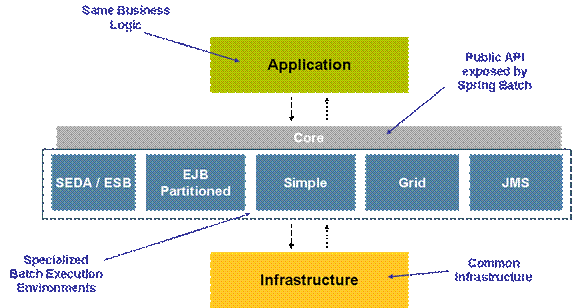
Figure 1 – Specializing execution environments on top of a common infrastructure
The "layers" described are nicely segregated in terms of dependency and each layer only depends (at compile time) on layers below it. These layers are:
- Application -- the business logic written by the application developers (the client of Spring Batch), which only depends on the other Core interfaces for compilation and configuration.
- Core -- the public API of Spring Batch, including the batch domain language of Job, Step, Configuration and Executor interfaces.
- Execution -- the deployment, execution and management concerns. Different execution environments (e.g. SEDA/ESB, EJB Partitioned, Simple, Grid and JMS) are configured differently but can execute the same application business logic.
- Infrastructure -- a set of low level tools that are used to implement the execution and parts of the core layers.
The "execution" layer is fertile ground for collaboration and contributions from the community, and from projects in the field. The vision is for multiple implementations of this interface to provide different architectural patterns and deliver different levels of scalability and robustness, without changing either the business logic or the job configuration.
The Spring Batch infrastructure provides core services for building batch execution environments, illustrated in Figure 1. The Simple Execution Service that ships with the initial 1.0 release of Spring Batch is a single JVM configuration (with multi-threading capabilities). It processes multiple input source formats (e.g. fixed length records, delimited records, xml records, database, etc.) and targets the output to different formats (e.g. other flat files, database, queues, etc).
A Simple Batch Execution Environment Sample
Batch Jobs are generally implemented using the Pipes and Filters pattern. Spring Batch is no different in this regard. This is illustrated in Figure 2.
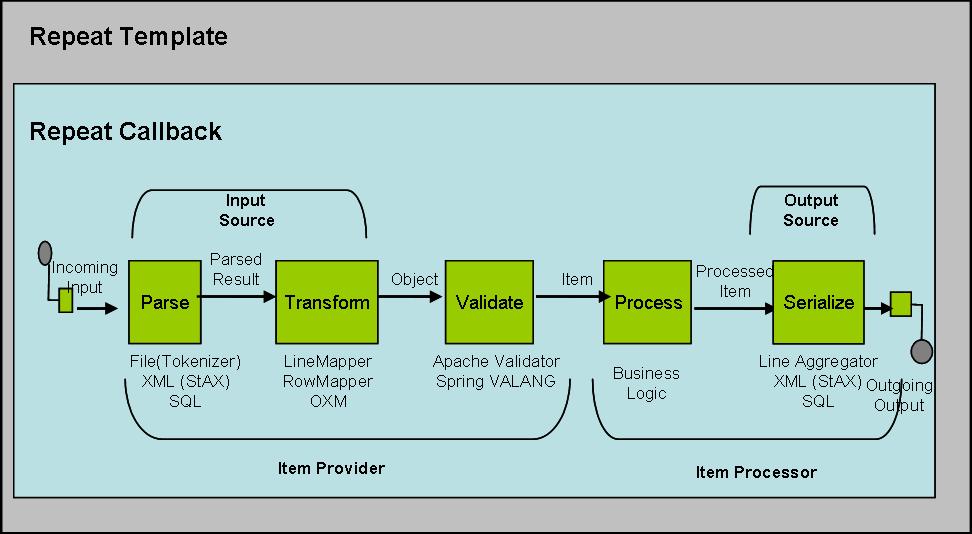
Figure 2 - Spring Batch Pipe & Filters
There are many sample batch jobs that ship with the Spring Batch architecture in the samples module. The use of the Simple Batch Execution Environment and its dependency on Spring Batch can be illustrated through a simple example. Although the sample is contrived, it shows a Job with multiple steps. The Job is a football statistics loading job with the id of “footballjob” in the configuration file.
Before beginning the batch job, consider two input files that need to be loaded. First is ‘player.csv’, which can be found in the samples project under src/main/resources/data/footballjob/input/. Each line within this file represents a player, with a unique id, the player’s name, position, etc:
AbduKa00,Abdul-Jabbar,Karim,rb,1974,1996 AbduRa00,Abdullah,Rabih,rb,1975,1999 AberWa00,Abercrombie,Walter,rb,1959,1982 AbraDa00,Abramowicz,Danny,wr,1945,1967 AdamBo00,Adams,Bob,te,1946,1969 AdamCh00,Adams,Charlie,wr,1979,2003
One of the first noticeable characteristics of the file is that each data element is separated by a comma, a format most are familiar with known as ‘CSV’. Other separators such as pipes or semicolons can also be used to delimit fields. The flat file input can also have fixed-length records instead of character delimited records. Because both input files in this example are comma delimited, we’ll skip over the fixed-length case for now, except to say that the only difference between the two types is that fixed-length formatting assigns each field a ‘fixed length’ in which to reside, rather than using a character to separate individual elements.
The second file, ‘games.csv,’ is formatted the same as the previous example and resides in the same directory:
AbduKa00,1996,mia,10,nwe,0,0,0,0,0,29,104,,16,2 AbduKa00,1996,mia,11,clt,0,0,0,0,0,18,70,,11,2 AbduKa00,1996,mia,12,oti,0,0,0,0,0,18,59,,0,0 AbduKa00,1996,mia,13,pit,0,0,0,0,0,16,57,,0,0 AbduKa00,1996,mia,14,rai,0,0,0,0,0,18,39,,7,0 AbduKa00,1996,mia,15,nyg,0,0,0,0,0,17,96,,14,0
Each line in the file represents an individual player’s performance in a particular game, containing such statistics as passing yards, receptions, rushes and total touchdowns.
The batch job will load both files into a database, and then combine each to summarize how each player performed for a particular year. Although this example is fairly trivial, it shows multiple types of input and the general style is a fairly common batch scenario. That is, summarizing a very large dataset so that it can be more easily manipulated or viewed by an online web-based application. In an enterprise solution the third step, the reporting step, could be implemented through the use of Eclipse BIRT or one of the many Java Reporting Engines. Given this description, the batch job can easily be divided into three ‘steps’: one to load the player data, one to load the game data and one to produce a summary report.
It’s useful to note a nice feature of Spring is a project called Spring IDE. Spring IDE can be installed when the project is downloaded and the Spring configurations can be added to the IDE project. The visual view into Spring beans is helpful in understanding the structure of a Job Configuration. Spring IDE produces the diagram illustrated in Figure 3:
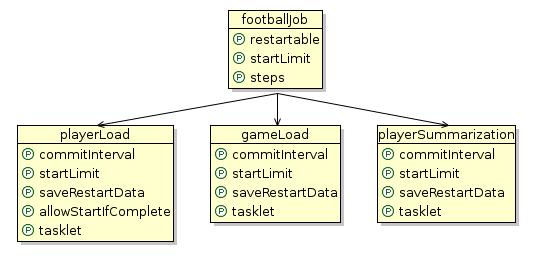
Figure 3 - Spring Bean Job Configuration
This corresponds exactly with the footballJob.xml job configuration file which can be found in the jobs folder under src/main/resources. The footballjob configuration has a list of steps:
<property name="steps">
<list>
<bean id="playerload"> ... </bean>
<bean id="gameLoad"> ... </bean
<bean id="playerSummarization"> ... </bean>
</list>
</property>
Each step is run until there is no more input to process, which in this case would mean that each corresponding file has been completely processed. The first step, playerLoad, begins executing by grabbing one line of input from the file and parsing it into a domain object. That domain object is then passed to a dao, which writes it out to the PLAYERS table. This action is repeated until there are no more lines in the file, causing the playerLoad step to finish. Next, the gameLoad step does the same for the games input file, inserting into the GAMES table. Once finished, the playerSummarization step can begin. Unlike the first two steps, playerSummarization’s input comes from the database, using a Sql statement to combine the GAMES and PLAYERS table. Each returned row is packaged into a domain object and written out to the PLAYER_SUMMARY table.
Now that we’ve discussed the entire flow of the batch job, we can dive deeper into the first step: playerLoad:
<bean id="playerload" class="org.springframework.batch...SimpleStepConfiguration"> <property name="commitInterval" value="100" /> <property name="tasklet"> <bean class="org.springframework...RestartableItemProviderTasklet"> <property name="itemProvider">...</property> <property name="itemProcessor">...</property> </bean> </property> </bean>
The root bean in this case is a StepConfiguration, which can be considered a ‘blueprint’ that tells the execution environment basic details about how the batch job should be executed. It contains two properties (others have been removed for greater clarity): Tasklet and commitInterval. The Tasklet is the main abstraction representing the developer’s business logic within the batch job. After performing all necessary startup, the framework will periodically delegate to the Tasklet. In this way, the developer can remain solely concerned with their business logic. In this case, which is quite typical, the Tasklet has been split into two classes:
- Item Provider – the source of the information pipe. At the most basic level, input is read in from an input source, parsed into a domain object and returned. In this way, the good batch architecture practice of ensuring all data has been read before beginning processing can be enforced, along with providing a possible avenue for reuse.
- Item Processor – the business logic. At a high level, the ItemProcessor takes the item returned from the ItemProvider and ‘processes’ it. In our case it’s a data access object that is simply responsible for inserting a record into the PLAYERS table.
Clearly, the developer does very little. There is a job configuration with a configured number of steps, an Item Provider associated to some type of input source and Item Processor associated to some type of output source, as well as a little mapping of data from flat records to objects.
The other property to the StepConfiguration, commitInterval, gives the framework vital information about how to control transactions during the batch run. Due to the large amount of data involved in batch processing, it is advantageous to ‘batch’ together multiple Logical Units of Work into one transaction, since starting and committing a transaction is expensive. For example, in the playerLoad step, the framework calls the execute() method on the Tasklet, which then calls next() on the ItemProvider. The ItemProvider reads one record from the file, and then returns a domain object representation, which is passed to the processor. The processor then writes the one record to the database. It can then be said that one operation = one call to Tasklet.execute() = one line of the file. Therefore, setting the commitInterval to 5 would result in the framework committing a transaction after 5 lines have been read from the file, with 5 resultant entries in the PLAYERS table.
Following the general flow of the batch job, the next step is to describe how each line of the file will be parsed from its string representation into a domain object. The first thing the provider will need is an InputSource, which is provided as part of the Spring Batch infrastructure. Because the input is flat-file based, a FlatFileInputSource is used:
<bean id="playerFileInputSource"
class="org.springframework.batch.io.file.support.DefaultFlatFileInputSource">
<property name="resource">
<bean class="org.springframework.core.io.ClassPathResource">
<constructor-arg value="data/footballjob/input/player.csv" />
</bean>
</property>
<property name="tokenizer">
<bean class = "org.springframework.batch.io.file.support.transform.DelimitedLineTokenizer">
<property name="names"
value="ID,lastName,firstName,position,birthYear,debutYear" />
</bean>
</property>
</bean>
There are two required dependencies of the input source. The first dependency is a resource from which to read (the file to be processed), and the second is a LineTokenizer. The interface for a LineTokenizer is very simple, given a string; it will return a FieldSet that wraps the results from splitting the provided string. A FieldSet is Spring Batch’s abstraction for flat file data. It allows developers to work with file input in much the same way as they would work with database input. All the developer needs to provide is a FieldSetMapper (similar to a Spring RowMapper) that will map the provided FieldSet into an Object. By simply providing the names of each token to the LineTokenizer, the ItemProvider can pass the FieldSet into the PlayerMapper, which implements the FieldSetMapper interface. There is a single method, mapLine(), which maps FieldSets the same way that developers are comfortable mapping SQL ResultSets into Java Objects, either by index or fieldname. This behavior is by intention and design similar to the RowMapper passed into a JdbcTemplate. See this example below:
public class PlayerMapper implements FieldSetMapper {
public Object mapLine(FieldSet fs) {
if(fs == null){
return null;
}
Player player = new Player();
player.setID(fs.readString("ID"));
player.setLastName(fs.readString("lastName"));
player.setFirstName(fs.readString("firstName"));
player.setPosition(fs.readString("position"));
player.setDebutYear(fs.readInt("debutYear"));
player.setBirthYear(fs.readInt("birthYear"));
return player;
}
}
In this case, the flow of the ItemProvider starts with a call to readFieldSet on the InputSource. The next line in the file is read in as a String and passed into the provided LineTokenizer. The LineTokenizer splits the line at every comma, and creates a FieldSet using the created String array and the array of names passed in. Note that it is only necessary to provide the names if you need to access the field by name, rather than by index.
Once the domain representation of the data has been returned by the provider (i.e. a Player object), it is passed to the ItemProcessor, which is a Dao that uses a Spring JdbcTemplate to insert a new row in the PLAYERS table.
The next step, gameLoad, works almost exactly the same as the playerLoad step except the games file is used.
The final step, playerSummarization, is much like the previous two steps. It is split into a provider that reads from an InputSource and returns a domain object to the processor. However, in this case, the input source is the database, not a file:
<property name="dataSource" ref="dataSource" /> <property name="mapper"> <bean class="sample.mapping.PlayerSummaryMapper" /> </property> <property name="sql"> <value> SELECT games.player_id, games.year, SUM(COMPLETES), SUM(ATTEMPTS), SUM(PASSING_YARDS), SUM(PASSING_TD), SUM(INTERCEPTIONS), SUM(RUSHES), SUM(RUSH_YARDS), SUM(RECEPTIONS), SUM(RECEPTIONS_YARDS), SUM(TOTAL_TD) from games, players where players.player_id = games.player_id group by games.player_id, games.year </value> </property> </bean>
The SqlCursorInputSource has three dependences:
- A DataSource
- The SqlRowMapper to use for each row.
- The Sql statement used to create the Cursor.
When the step is first started, a query will be run against the database to open a cursor and each call to inputSource.read() will move the ‘cursor’ to the next row, using the provided RowMapper to return the correct object. As with the previous two steps, each record returned by the provider will be written out to the database in the PLAYER_SUMMARY table.
Finally, to run this sample application, execute the JUnit test “FootballJobFunctionalTests”, to see an output showing each of the records as they are processed. The ItemProcessors (through an AoP interceptor) output each record as it is processed to the logger; this will impact performance, but it is only for demonstration purposes.
Summary
Spring Batch is a new implementation of some very old ideas. It brings one of the oldest programming models in IT organizations into the mainstream through the use of Spring, a popular open source framework. It enables a batch project to enjoy the same clean architecture and lightweight programming model as any Spring project, supported by industry-proven patterns, operations, templates, callbacks and other idioms. Spring Batch is an exciting initiative that offers the potential of standardizing Batch Architectures within the growing Spring Community and beyond.
Please share your experiences in using Spring Batch by visiting the sites listed below.
Additional Key Resources
[1] Spring Batch Home Page: http://www.springframework.org/spring-batch
[2] Spring Batch Source Code (Subversion repository): https://springframework.svn.sourceforge.net/svnroot/springframework/spring-batch/trunk/
[3] Spring Batch Forum: http://forum.springframework.org/forumdisplay.php?f=41
[4] Spring Batch Jira Page: http://opensource.atlassian.com/projects/spring/browse/BATCH.
[5] Spring Batch Mailing List: http://lists.interface21.com/listmanager/listinfo/spring-batch-announce
Biographies
Dr David Syer is an experienced, delivery-focused architect and development manager at Interface21. He has designed and built successful enterprise software solutions using Spring, and implemented them in major financial institutions worldwide. David is known for his clear and informative training style and has deep knowledge and experience with all aspects of real-life usage of the Spring framework. He enjoys creating business value from the application of simple principles to enterprise architecture. David joined Interface21 from a leading risk management software vendor where he worked closely with Interface21 on a number of projects. Recent publications have appeared in Balance Sheet, Operational Risk and Derivatives Technology.
Lucas Ward is a Java Architect focused on batch architectures within the Innovation and Architecture practice within Accenture. He has been working over the past two years on Accenture's methodology and architecture best practices, in particular regarding the use of open source. Lucas is co-leading the development of Spring Batch, utilizing experiences from multiple batch architecture implementations throughout Accenture.







