Scaling Your Java EE Applications -- Part 2
Java applications can be scaled vertically (on a single system), or horizontally (across multiple systems). But to do either, you have to understand all parts of the system and software. Not doing so could defeat the purpose of adding system resources or more systems. Wang Yu presents some surprising results of Java application scalability based on his experiences in a performance laboratory. The second installment of this series discusses scaling horizontally.
If you cannot satisfy the performance with one server node when concurrent users are increasing dramatically, or you cannot scale your Java applications with one JVM instance due to the limitation of garbage collection, your other choice is to run your systems in multiple JVM instances or in multiple server nodes. We called it horizontal scalability.
Please note we believe that the ability to scale on multiple JVM stances in the same machine is horizontal scalability instead of vertical. The IPC mechanisms among JVM instances are limited. Two JVM instances can't communicate through pipes, shared memory, semaphores or signals. The most effective way to communicate among different JVM processes is by socket. Simply put, if Java EE applications can be scalable on multiple JVM instances, they are also mostly scalable on multiple server nodes.
As computer prices drop and performance continues to increase, low cost commodity systems can be configured in a cluster to obtain aggregate computing power which often exceeds those expensive high end supercomputers. However, larger numbers of computers means increased management complexity, as well as a more complex programming model and issues such as throughput and latency between nodes.
Java EE clustering is a mature technology, about which I have written an article named “Uncover the Hood of J2EE Clustering” on TSS to describe its internal mechanism.
Lessons learned from failed projects
Use share nothing clustering architectures
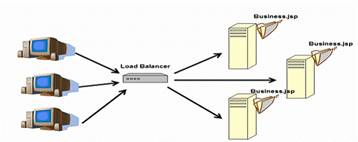
Figure 3: share nothing cluster
The most scalable architectures are sharing-nothing clusters. In such clusters, each node has the same functionalities, and knows nothing about the existence of other nodes. The load balancer will decide how to dispatch the requests to the back end server instances. It is rare that a load balancer will become a bottleneck, because a load balancer only need to do some very simple jobs, such as distributing requests, health checking, and session sticking. By adding more nodes, the computing ability of the cluster is increasing almost lineally, if the back end database or other information systems are powerful enough.
However, almost all popular Java EE vendors implement HTTPSession failover in their cluster products to ensure that all client requests can be processed properly without losing any session state in case of failure of some server nodes. This will break the share nothing principle. The same session data objects will be shared among two or more nodes in order to implement the failover functionality. In my previously-referenced article, I recommended not to use the session failover, unless it is strictly required. The session failover functionality cannot avoid errors completely when failures happen, as my article mentioned, but it will damage the performance and scalability.
Use scalable session replication mechanisms
If you are required to use session failover to give a more friendly experience to users, it is important to choose scalable replication products or mechanisms. Different vendors implement variable replication solutions – some use database persistence, some use centralized state server, while others use memory replications among nodes. The most scalable one is paired node replication, which is implemented by most popular vendors, such as BEA Weblogic, JBoss and IBM Websphere. Sun implemented the paired node replication in Glassfish V2 and above. The least scalable solution is using database as session persistence storage. One of projects tested in our laboratory using database persistence as session replication found that no more than three to four nodes would kill the database if the session objects were updated frequently.
Use collocated deployment instead of distributed one
Java EE technology, especially EJB, was born for distributed computing. Decoupled business functionality and reused remote components make multi-tier applications popular. But for scalability, reducing the distributed layers maybe a good choice.
A government project tested in our laboratory compared two different deployments in the same number of server instances – a distributed structure and a collocated one, show as the following: figures:
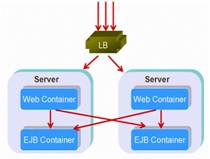
Figure 4: distributed structure |
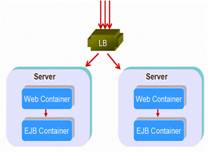 Figure 5: collocated structure |
The result was that the collocated structure scaled much better than the distributed one! Imagine in one method in your application you may be invoking a couple of EJBs. If you load balance on every one of those EJBs, you're going to end up with instances of your application spread out across the multiple server instances. As a result, you're going to have a lot of server-to-server cross talk that's unnecessary. And more, if your method is under a transaction, your transaction boundary will include many server instances which will impact performance heavily.
Shared resources and services
In Java EE clustering systems servicing concurrent requests, scalable performance is limited by the number of operations which must utilize any shared resource that does not exhibit linear scalability. Database servers, JNDI trees, LDAP Servers, and external file systems can be shared by the nodes in the cluster.
Although not recommended by the Java EE specification, the external I/O operations are used for various purposes. For example, some applications tested in our laboratory used file systems to save uploading files by users, or create dynamic configuration XML files. Within a cluster, the application server nodes need a way of replicating these files across to other instances. But this was proven unscalable. With more nodes added, copying files among server instances will occupy all the network bandwidth and consuming considerable CPU resources. To work in a cluster, the solution is to use the database in place of external files, or choose SAN as the central deposits for files. An alternative way is to use an effective distributed file systems, such as Hadoop DFS (http://wiki.apache.org/hadoop/).
Shared services are common in a clustering environment. Those services are not deployed on every node of the cluster. Instead, they are installed on a dedicated server node, such as distributed logging service or timing service. A distributed lock manager (DLM) provides the applications on the server nodes in a cluster with a means to synchronize their accesses to shared services. A lock manager must operate correctly regardless of network latencies and system failures. For example, an ERP system tested in our laboratory has met such problems. They have written their own DLM system, but finally found their lock system would hold for locks forever, in case of failure of nodes which hold locks.
Distributed cache
Almost every Java EE project I experienced used object caching to improve performance, and all popular application servers provide extra degrees of caching to enable faster applications. But some caches are typically designed for a standalone environment, and can only work within one JVM instance. We need cache because some objects are so heavy that creating a new one will cost a great deal. So we maintain an object pool to reuse the object instances without further creation. We gain performance only if the maintenance of the cache is cheaper than objects creation. In a clustered environment, each JVM instance will maintain its own copy of the cache, which should be synchronized with others to provide inconsistent state in all server instances. Sometimes this kind of sync will bring worse performance than no caching at all. A scalable distributed cache system is very important for the scalability of the whole cluster.
Many open sourced Java products related to distributed cache are very popular. Followings are ones tested in our laboratory:
- 1 project tested on JBoss Cache
- 3 projects tested on Terracotta
- 9 projects tested memcached
Test result showed that Terracotta scaled well on 10 nodes and got a very high performance among no more than 5 nodes, but memcached scaled extremely well on more than 20 server instances.
Memcached
Memcached is a high-performance, distributed memory object caching system, generic in nature, but intended for use in speeding up dynamic web applications by alleviating database load. Memcached's magic lies in its two-stage hash approach. It behaves as though it were a giant hash table, looking up key = value pairs. Give it a key, and set or get some arbitrary data. When doing a memcached lookup, first the client hashes the key against the whole list of servers. Once it has chosen a server, the client then sends its request, and the server does an internal hash key lookup for the actual item data. The big benefit, when dealing with giant systems, is memcached's ability to massively scale out. Since the client does one layer of hashing, it becomes entirely trivial to add dozens of nodes to the cluster. There's no interconnect to overload, or multicast protocol to implode.
Memcached actually is not a Java product, but it has a Java client API. That means if you want to port your Java EE applications to use memcached, an amount of modification is unavoidable to use the API to get and put the values to/from the cache. Using memcached is very simple, but there are still some things you should try to avoid with respect to scalability and performance.
- Don't cache objects who are updated more frequently than read. Memcached is used to reduce your database reads instead of writes. You have to see what the read/write ratio per object will be. If the number of ratio is high, then caching makes a lot of sense.
- Try to avoid paging in the nodes running memcached. Swapping may be a disaster for memcached.
- Try to avoid row based cache. Instead, cache complex object will make memcached more efficient.
- Choose the right hashing algorithms. With default algorithms, adding or removing servers will invalidate all of your cache. Since the list of servers to hash against has changed, most of your keys will likely hash to different servers. Use consistent hashing algorithms (http://weblogs.java.net/blog/tomwhite/archive/2007/11/consistent_hash.html) to add and remove servers, will keep most of your cached objects valid.
Terracotta
Terracotta (http://www.terracottatech.com/) is an enterprise-class, open-source, JVM-level clustering solution. JVM-level clustering simplifies enterprise Java by enabling applications to be deployed on multiple JVMs, yet interact with each other as if they were running on the same JVM. Terracotta extends the Java Memory Model of a single JVM to include a cluster of virtual machines such that threads on one virtual machine can interact with threads on another virtual machine as if they were all on the same virtual machine with an unlimited amount of heap.
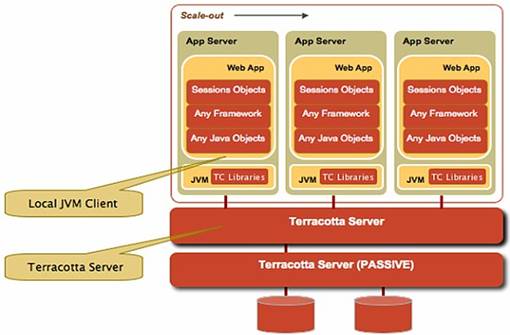
Figure 6: Terracotta JVM clustering
The programming model of applications clustered using Terracotta is the same or similar to that of an application written for a single application. There is no developer API specific to Terracotta. Terracotta uses bytecode manipulation—a technique used by many Aspect-Oriented software development frameworks such as AspectJ and AspectWerkz—to inject clustered meaning to existing Java language features.
Among the Terracotta server and client JVM instances, there I presume that must be some interconnect or multicast protocol to communicate among them. That may be the reason that the Terracotta failed to scale very well on more than 20 nodes for the projects tested in my laboratory. (Note: The test result is only reflected on the projects in our laboratory; your results may vary.)
Paralleled processing
As I mentioned earlier, a single thread of tasks will be the scalability bottleneck of the system. However, some single-thread jobs, such as processing or generating huge data sets, not only need to be paralleled to multithreaded or multiprocessed, but also have the requirement of scaling to multiple server nodes. For example, a Java EE project tested in our laboratory has a scenario to analyze the URL access patterns in their website from the logging files. The logging files would be accumulated more than 120 GB every week. Analyzing these logging files required four hours when using a single thread of Java application. This customer resolved this problem by using Hadoop Map-Reduce to scale it horizontally. Now, this URL access patterns analyzing program can not only be run in a multiprocessed mode, but also parallelized to more than 10 nodes, and it only spends 7 minutes to finish all the work.
There are a lot of frameworks and tools to help Java EE developers to scale their applications horizontally. In addition to the Hadoop, a lot of Java implementation of MPI can also help to parallel single thread of tasks to scale to many nodes.
MapReduce
MapReduce is a distributed programming model intended for processing massive amounts of data in large clusters, developed by Jeffrey Dean and Sanjay Ghemawat at Google. MapReduce is implemented as two functions – Map, which applies a function to all the members of a collection and returns a list of results based on that processing, and Reduce, which collates and resolves the results from two or more Maps executed in parallel by multiple threads, processors, or stand-alone systems. Both Map() and Reduce() may run in parallel, though not necessarily in the same system at the same time.
Hadoop is an open-source, end-to-end, general-purpose Java implementation of MapReduce. It is a Lucene-derived framework for deploying distributed applications running on large clusters of commodity computers, and being built and used by a community of contributors from all over the world. Yahoo's Search Webmap, Amazon EC2/S3 services and Sun's grid engine can all be run on Hadoop.
To simply put, by using “Hadoop Map-Reduce”, the “URL access patterns analyzing” program first divides the logging files into 128MB splits and the framework assigns one split to each Map function. The Map function will analyze the split assigned to it and generate a temporary result. All the temporary results from Map functions are sorted and assign to each Reduce function. The Reduce function will combine all the temporary results to get the final result. Those Map and reduce functions can be run paralleled on all the nodes comprising the cluster, and controlled by the Hadoop framework.
MapReduce is useful in a wide range of applications, including distributed grep, distributed sort, web link-graph reversal, term-vector per host, web access log stats, inverted index construction, document clustering, machine learning, statistical machine translation and other areas.
MPI
MPI is a language-independent communications protocol used to program parallel computers . Many Java versions of the MPI standard have been developed. mpiJava and MPJ are typical. mpiJava is implemented as a thin Java native interface (JNI) wrapper on top of a native MPI library. MPJ is a 100 percent Java implementation of the MPI standard. Both mpiJava and MPJ adhere closely to MPI’s Fortran and C oriented API; for example, each provides a Comm class with the same method names and arguments as MPI’s message passing subroutines.
CCJ is a Java library of MPI-like collective communication operations. CCJ provides the barrier, broadcast, scatter, gather, all-gather, reduce, and all-reduce operations (but not point-to-point communication operations like send, receive, and send-receive). Rather than implementing its own low-level communication protocol, CCJ is implemented on top of Java remote method invocation (RMI). This allows CCJ to transfer arbitrary serializable objects, not just primitive data types as in MPI. Furthermore, CCJ can scatter and gather portions of arbitrary collection objects among a group of parallel processes, as long as the collections implement CCJ’s DividableDataObject interface.
Using unorthodox approach to achieve high scalability
There are a lot of books and articles to teach us how to design the systems in an Object Oriented way to get a flexible structure, how to make your services transparent to the clients to get a maintainable systems, and how to design your database schema with normalized model to make your data more integrated. But sometimes, in order to get high scalability, unorthodox ways may be chosen.
Google designs its highly scalable distributed file system(GFS) without implementation of the POSIX API, and GFS is not transparent to the users at all. To use the GFS, you must use the GFS API library. Google also designs a highly scalable distributed database system (Bigtable) without complying with the ANSI SQL standard. The whole concept and structure are totally different with traditional relational database. But the most important thing is both GFS and Bigtable are extremely scalable to successfully meet Google's storage needs and are widely deployed within Google as the storage platform.
Traditionally, we scale databases by using bigger, faster and more expensive server machines, or we may use enterprise cluster database such as Oracle RAC to scale our database to more server nodes. But a social networking website tested in our laboratory chooses the unorthodox way. This web based social networking application allows users to create personal profiles, blogs in the website and share photos and music with friends. This application is Java EE based, and built upon Tomcat and MySQL. Unlike other applications tested in our laboratory, it only wants to be tested on more than 20 inexpensive PC servers. Their data model is shown below:
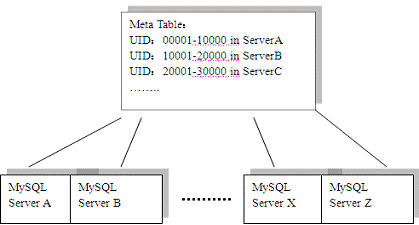
Figure 7: Users data partitions
The special part of this lies in that different users' data (such as profile and blog) may be stored on different database server instances. For example, user 00001 is stored on server A, while user 20001 is stored on server C. A meta table in a dedicated database server describes the partition rules. When the Java EE application deployed in Tomcat wants to access (or update) the user information, it will first connect to the “meta table” to find the database node to serve the user, then connect to that server to operate the query or update actions.
The partition of user data and two steps access approach have following advantages:
- Scalable write bandwidth: In this kind of applications, blogging, ranking and BBS will make the write bandwidth the major bottleneck for social networking websites. Distributed Cache system will help little on the performance for the database write actions. With data partitions, you can write in parallel which increases your write throughput. To support more registered users just add more database nodes, modify the meta table to reflect the new servers.
- High availability: If one database server goes down, only some users are impacted, while others still operate.
The disadvantages are:
- Since database nodes can be added very dynamically, it is hard for Java EE applications in Tomcat to use the database connection pools.
- Since user data access involve two steps actions, it is hard to use ORMapping tools for developers.
- To create a complex search or joining data, you usually must pull together lots of different data from different database servers.
“We know well about these disadvantages, and have prepared for it”, the architect said about their system. “We even prepared for the extreme situation that the meta table server becomes the bottleneck. Then we will depart from the meta table, and create a top level meta table to point to many second level meta table server instances.”
References
- Scalability definition in wikipedia: https://en.wikipedia.org/wiki/Main_Page
/Scalability - Javadoc of atomic APIs: http://java.sun.com/j2se/1.5.0
/docs/api/java/util/concurrent /atomic/package-summary.html - Alan Kaminsky. Parallel Java: A unified API for shared memory and cluster parallel programming in 100% Java: http://www.cs.rit.edu/~ark
/20070326/pj.pdf - OMP-an OpenMP-like interface for Java: http://portal.acm.org/citation
.cfm?id=337466 - Google MapReduce white paper: http://labs.google.com/papers
/mapreduce-osdi04.pdf - Google Bigtable white paper: http://labs.google.com/papers
/bigtable-osdi06.pdf - Hadoop MapReduce tutorial: https://hadoop.apache.org/core
/docs/r0.17.0/mapred_tutorial .html - Memcached FAQ: http://www.socialtext.net
/memcached/index.cgi?faq - Terracotta: http://www.terracotta.org/
About the Author
Wang Yu presently works for ISVE group of Sun Microsystems as a Java technology engineer and technology architecture consultant. His duties include supporting local ISVs, evangelizing and consulting on important Java technologies such as Java EE, EJB, JSP/Servlet, JMS, Web services technologies. He can be reached at [email protected].







