MapReduce Part II
MapReduce is a distributed programming model intended for parallel processing of massive amounts of data. This article describes a MapReduce implementation built with off-the-shelf, open-source software components. It shows you how to write resource-oriented applications for the Mule integration platform as a side effect of its implementation.
MapReduce is a distributed programming model intended for parallel processing of massive amounts of data, as discussed in the previous article of this series: Why Should You Care About MapReduce? This article describes a MapReduce implementation built with off-the-shelf, open-source software components. All the source and configuration files are available for download, while this discussion will focus only on the implementation details. The shopping list is familiar to the average TSS reader:
- Java 5 or Java 6 SE for development¬, and JRE for deployment
- Mule Integration Platform community edition version 1.5
- Webnet77 IpToCountry database
This implementation is intended for illustration purposes only and the examples lack exception handling acceptable for production systems. Beyond showcasing an implementation of the MapReduce concept, this article also shows how to write service-oriented applications for the Mule integration platform as a side effect of the implementation. The mapping and reduction output becomes the "service".
The pundits of dedicated MapReduce and grid computing systems may ask why use POJOs and ESBs instead of a specialized system. The simple answer is... because it’s easy to do.
A Simple but Resource-intensive Problem
This author produced The Sushi Eating HOWTO in 2002, a non-commercial popular page that gets about 500 unique daily views with periodic spikes of up to 120,000 views on a single day when it has been featured in community sites like StumbleUpon, del.icio.us, reddit.com, or Food Site of the Day. The sample problem consists of profiling the percentages of page visitors per country based on their IP addresses. Several TB of Apache logs are available for analysis, growing at an average rate of 10 MB/day each, per server. The logs also contain data pertaining to other pages hosted at the site and initial filtering winnows the requests specific to the Sushi Eating HOWTO page.
The solution to the problem is easy to break down into these discrete steps:
- Extract only the logged file requests for the specific page
- Extract the IP addresses for each request
- Eliminate and aggregate repeated hits
- Identify the country corresponding to each IP address
- Keep a running total of page requests per country
- Calculate the percentage of visitors per country and generate a report
The first step is necessary because the log also contains requests for images, CSS, JavaScript, and other artifacts, as well as other pages hosted on the site.
The first and second steps are trivial to carry out with dedicated text parsing tools like awk when applied to a log entry like the one in sample 1:
67.163.106.42 - - [06/Apr/2008:08:11:36 -0700] "GET /musings/sushi-eating-HOWTO.html HTTP/1.1" 200 78594 "https://www.google.com/search?hl=en&sa=X&oi=spell&resnum=0&ct=result&cd=1&q=Kappamaki+clear+palate&spell=1" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET CLR 2.0.50727; MSN 9.0;MSN 9.1; MSNbVZ02; MSNmen-us; MSNcOTH)"
Example 1
Listing 1 shows the awk program for extracting only the requests for the specific page and keeps a list of the requester's IP address.
#!/usr/bin/awk -f
# logmap1.awk / Listing 1
# Field Contents
# ----- --------
# $7 page to scan for
# $1 requester's IP address
$7 ~ "/musings/sushi-eating-HOWTO" {
nRecordsAnalyzed++;
requester[$1] = "n/a"; # Don't know the country yet
}
END {
for (address in requester)
printf("IP address = %s - country = %sn", address, requester[address]);
printf("Analyzed %d records.n", nRecordsAnalyzed);
Listing 1
This simple awk program could be expanded to implement all the steps describing the solution:
requester[$1] = resolveCountry($1);
The resolveCountry() function could be implemented in awk, or as a call to an external program or function but that would increase the complexity of the script and degrade its performance. Resolving the number of requests per country, the running total, and the percentage of visitors per country implies either further expansion of the script, or chaining scripts through pipes to arrive at the desired result. This sequential processing has these drawbacks:
- The execution time grows linearly as the number or size of the log files increases
- Changes in the requirements imply changes in the code that must be unit and integration tested because they will affect the whole program
- Performance penalties due to process start/stop and piping if the program is split into smaller chunks
- Integration to pipes complicates distributing the processes among multiple machines
These issues would manifest themselves in awk, Perl, Java, Excel/VB, or any other language, since sequential processing and custom heuristics are the real problem.
Fresh MapReduce – Made from Scratch
This is where MapReduce can help. One of the advantages of MapReduce is the ability to run parallel, concurrent versions of the mapping and reduction code to generate the desired result. Such a solution could be implemented in awk if all we wanted was to parse logs. Nothing prevents an end-user from running the code described in the previous section across multiple machines. The value of MapReduce comes from having the support infrastructure to synchronize process execution across multiple threads, processors, or complete systems while divorcing the business logic/heuristics/algorithmic portions of the solution from the ability to parallelize code execution. Programmers familiar with the problem domain can write elegant solutions without worrying about the multi-processing nature of the task. A solution to the problem through MapReduce must arrive to the same results as a sequential processing implementation.
There are commercial and open-source grid products that can be used for implementing MapReduce. Those will be discussed in a future article. For our purposes, let's define the following:
- This MapReduce implementation began life as a proof-of-concept and will evolve into a production grid
- The effort to develop this with tools familiar to the programmers was less than or equal to the effort necessary in learning how to use a third-party (open-source or commercial) MapReduce package
- There are neither time nor resources to train the IT staff on the management of a new software package before the MapReduce application goes to production
- The organization's policy regarding prototype-to-production projects is to release early and often instead of in one massive deployment; this is easier to accomplish if the foundational technology is already in production
- Management is less reluctant to adopt a new processing methodology if it's viewed as a refinement of existing infrastructure or applications
The MapReduce system can be expanded in-house once it is deployed in production if there are compelling reasons for that, such as requirements for custom signaling between applications not supported by the third party products. On the other hand, a successful implementation for a niche project may lead to the organization embracing MapReduce techniques. At that time it may make more sense to roll a third-party platform out and migrate the map/reduction code to it.
The seduction of applying latest technology is strong (e.g. Google AppEngine, GridGain) but the goal is to have something practical by being on the cutting edge of technology, not something so new that it lacks robustness and puts the organization at the bleeding edge.
The MapReduce Implementation
The MapReduce framework has the Mule Integration Platform at its core. Mule is capable of using POJOs as long as they implement any of these simple method definition patterns:
public Object methodName(Object o); public Object methodName(UMOEventContext context); public void methodName(Object o);
Example 2
The method name and its semantics aren’t important. Just have only one method that matches the signatures per class to prevent shadowing conflicts. Mule instantiates the object as a component unless there are any conflicts, assigns as many instances of it to as many threads as necessary, and provides input and output to the method from in-memory, file, I/O stream, or network protocol transports. For comparison, the Hadoop framework is custom-built as MapReduce infrastructure that provides custom services, job controllers, a cartload of dedicated APIs, and a custom file system. Cool and interesting, but with lots of new things to learn (and chances for the IT administrators to nix it). That’s a far cry from just defining simple POJOs.
Mule will handle jobs for our MapReduce system by consuming the inputs and routing them to the appropriate map or reduce task. The mappers and reducers are task-specific and independent of the launching mechanism. Problem domain experts write the mappers and reducers, unconcerned with Mule, multi-threading, message passing, or other infrastructure issues. Listing 2 shows the POJO that hosts the application logic for the solution’s step 4 discussed in the previous section.
package org.dioscuri;
import java.util.HashMap;
public class IPCountryReducer extends Service {
// *** Private and protected members ***
private HashMap<String, Integer>resolveCountriesIn(HashMap<String, Integer> map) {
HashMap<String, Integer> result = new HashMap<String, Integer>();
Integer count;
String country;
for (String address : map.keySet()) {
country = IPCountryDB.lookUp(address);
count = result.get(country);
if (count != null) result.put(country, count+map.get(address));
else result.put(country, map.get(address));
log.info("IP: "+address+" is in: "+country);
}
return result;
} // resolveCountriesIn
// *** Public methods ***
@SuppressWarnings("unchecked")
public Object resolveIPsByCountry(Object intermediateResults) {
HashMap<String, Integer> map, results = null;
try {
if ((intermediateResults instanceof HashMap) == false)
throw new IllegalArgumentException();
map = (HashMap<String, Integer>) intermediateResults;
results = this.resolveCountriesIn(map);
}
catch (Exception e) {
log.error(e.toString());
log.error("intermediateResults = "+intermediateResults);
log.error("results = "+results);
}
return results;
} // resolveIPsByCountry
} // IPCountryReducer
Listing 2
The implementation logic for this reducer is easy to understand and straightforward.
Each mapping or reducing stage can be defined in terms of a discrete set of components. Mule become a task manager, dispatching data from the buckets to the mappers and reducers using one of the available transports. Figure 1 shows the mapping and reducing processing stages.
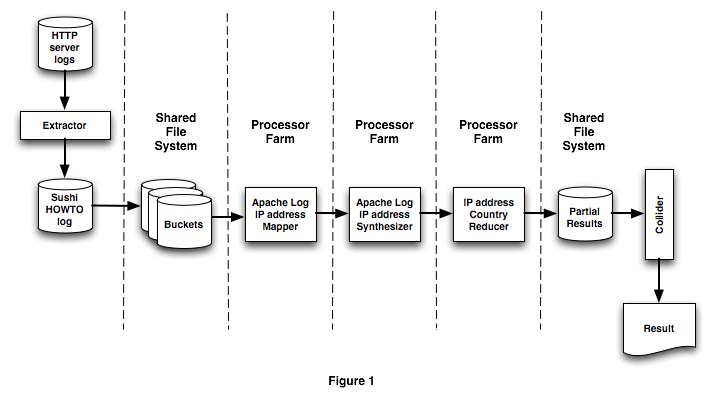
The process begins by extracting log entries that match the specific pattern for the pages of interest. This process can be done by a component in the MapReduce system or by an external process. The MapReduce system takes this log and splits it into buckets. The multi-processing stages begin after this point.
The buckets are written to a shared file system. One or more machines use each bucket as it becomes available and dispatch a thread for processing by a mapping or reduction task. Mule handles all task management and synchronization based on simple rules specified in a configuration file.
The "processor farm" is just a collection of processors or cores available for each stage. The physical mapping of the processor farm depends on the available hardware and the size of the job. For example:
- In-box processor farm: Niagara-based system capable of handling 32 concurrent threads. Mapping and reduction tasks can be performed within a single box for up to 48 buckets. All data transfers between mapping and reduction stages happen in-memory.
- Traditional processor farm: single- or dual-core systems connected over a fast LAN. Mapping and reduction tasks are handled by each system in a 1/processor ratio. Data transfers between mapping and reduction stages occur over the LAN.
- Hybrid processor farm: A physical farm of multi-core systems, connected over a high performance network. Tasks are handled by multiple threads/cores per system, with dynamic job routing based on Mule data filtering rules, processor load, and network topology. Data transfers for related reduction tasks occur in memory (e.g. extracting unique IP addresses and counting them) or across the network (e.g. associating each IP addresses to a country of origin using the database).
Figure 2 shows the basic network topology used for the examples in this article. Each color represents the data paths within the system context.
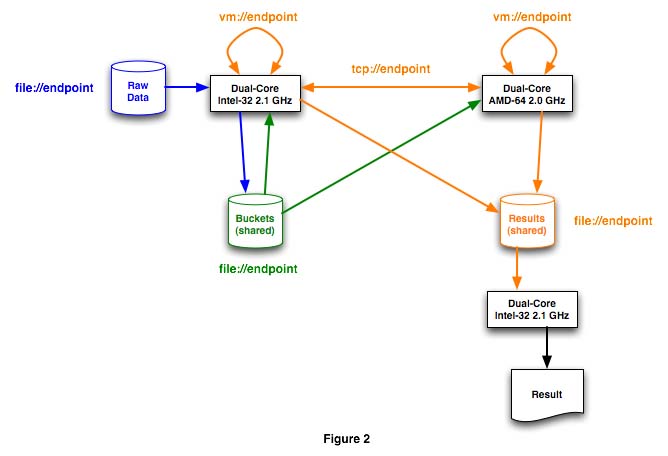
The blue path depicts how the raw data is split into buckets. Each bucket in the green path is assigned to a job, going to either processor, and each bucket is assigned to a job in the green path. The mapping and reduction tasks are divided between the four cores and two systems in the server farm; the orange path shows how some intermediate results are transferred in-memory, some over TCP/IP sockets, and the last stage is going to disk. The server farm was set up in a computer lab with 100 mbit networking, and the shared file systems are mounted over NFS; Samba added too much overhead but could be used if necessary.
Transport independence is one of the biggest advantages of rolling out this under Mule. Mule began life as an ESB but outpaced other service buses by providing complete transport and protocol independence. Remapping the topology like in figure 3 is possible without code changes.
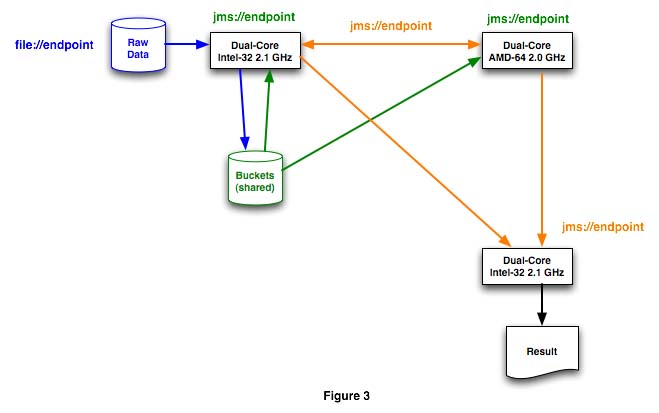
It’s easy to include endpoints in systems across a geographically distributed network or that implement application or context-specific business logic that’s useful for a specific reduction task but that it’s decoupled from the MapReduce system. Virtual addressability of such endpoints, and event-driven logic built using the Mule facilities, can provide the foundation of a resource-oriented architecture that merges distributed computing techniques with SOA at a low cost and with minimal risk for the organization tasked with building the system. An overview of such a system is described in this TheServerSide Java Symposium presentation Son of SOA: Resource Oriented Computing from the 2008 Las Vegas conference.
Environment Configuration and Java Code
Simplicity in coding and deployment is this system’s main objective. Providing the same configuration and executable code across all clustered nodes attained this. All node operations are stateless. Nodes may be reused for different stages as the process progresses. The configuration files and worker POJOs are modularized in such a way that a node can perform only a single mapping or reduction operation, or complete every stage of the process serially, but in parallel with other nodes carrying out the same operations. The size of the buckets, available memory, number of cores per system, and the complexity of the operations drive the application setup.
Figure 4 shows how the code and configuration are assigned in relation to the different processing stages.
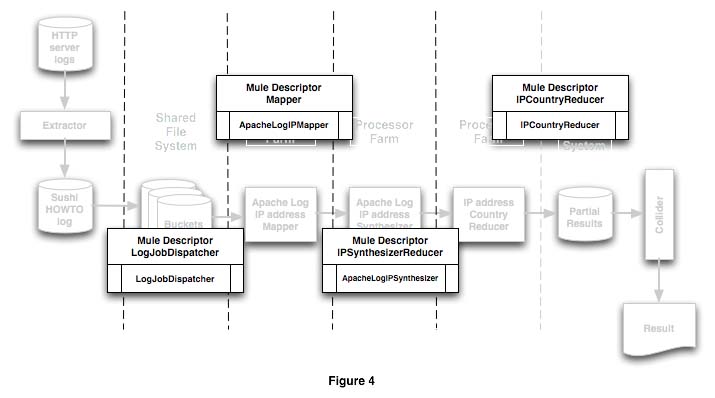
The basics of a Mule configuration file were discussed in the article Mule: A Case Study. A Mule instance loads the configuration from an XML file that describes one or more execution models like SEDA, direct, or other. Each model contains one or more descriptors that define how the POJO, or UMO, is configured and how it interacts with others through inbound and outbound routers that move data from an endpoint to the next. By the way: the Mule documentation talks about "UMO" or "Universal Message Object" or "Service Object". This is just a strange name for "POJO". UMO was coined before the Java community accepted the term POJO but it’s the same thing. Each endpoint is a file, memory, or network transport that moves data between descriptors, following the rules of the model. The full configuration file for the examples in this article is here.
The descriptor names are arbitrary and are only required to be meaningful in the context of the application. The application logic is defined to Mule with a simple class reference. The split boxes in figure 4 show the descriptor name on top and the Java class name at the bottom. Mule uses this class name to instantiate the POJO, and it uses dependency injection to set run-time configuration parameters. The descriptor in listing 3 shows how to configure the component that splits the log file into separate buckets.
<mule-descriptor name="LogJobDispatcher" implementation="org.dioscuri.LogJobDispatcher">
<inbound-router>
<endpoint address="RawDataStorage" connector="FileSystemRepository">
<filter pattern="*.log*" className="org.mule.providers.file.filters.FilenameWildcardFilter" />
</endpoint>
</inbound-router>
<properties>
<property name="jobName" value="Sushi HOWTO Visitor IP Geo Locator" />
<property name="linesPerBucket" value="20000" />
<property name="bucketPrefix" value="sushi-log-bucket" />
</properties>
</mule-descriptor>
Listing 3
Partial listing 4 shows the Java component responsible for splitting the log into buckets. Mule instantiates the object and provides the access methods (set, get) for configuring the object and querying its attributes and state at run-time.
package org.dioscuri;
import java.io.BufferedReader;
import java.io.FileOutputStream;
.
.
import org.mule.umo.UMOEventContext;
public class LogJobDispatcher extends Service {
// *** Symbolic constants ***
public static final String OUTPUT_PATH = "./buckets";
public static final String BUCKET_PREFIX = "log-bucket";
// *** Private and protected members ***
private int nLinesPerBucket;
private String jobName,
outputPath = OUTPUT_PATH,
bucketPrefix = BUCKET_PREFIX;
.
.
// *** Public methods ***
public void makeBuckets(UMOEventContext eventContext) {
BufferedReader input = null;
int nLineCount = 0x00;
Object anObject;
String line;
StringBuilder bucket;
try {
anObject = eventContext.getTransformedMessage();
if (anObject != null && anObject instanceof String) {
log.info("Job name: "+jobName);
log.info("Lines per bucket: "+nLinesPerBucket);
input = new BufferedReader(new StringReader(anObject.toString()));
bucket = new StringBuilder();
while ((line = input.readLine()) != null) {
bucket.append(line);
bucket.append('n');
if ((++nLineCount%nLinesPerBucket) == 0x00) {
this.saveToDisk(bucket.toString(), nLineCount/nLinesPerBucket);
bucket = new StringBuilder();
}
}
if ((nLineCount%nLinesPerBucket) != 0x00)
this.saveToDisk(bucket.toString(),
nLineCount/nLinesPerBucket+0x01);
}
}
catch (Exception e) {
log.error(e.toString());
}
finally {
if (input != null) try { input.close(); } catch (Exception f) { }
}
} // makeBuckets
// *** Accessors ***
public void setLinesPerBucket(int nLinesPerBucket) {
this.nLinesPerBucket = nLinesPerBucket;
} // setLinesPerBucket
public int getLinesPerBucket() {
return nLinesPerBucket;
} // getLinesPerBucket
.
.
} // LogJobDispatcher
Listing 4 (partial)
All the component classes in this MapReduce implementation are specializations of the abstract Service class, which the author defined for implementing functionality common to all objects such as the log object, which is just an instance of the current run-time log obtained via log = LogFactory.getLog(this.getClass()). Except for the LogJobScheduler object, which implements a call that uses an UMOEventContext object, none of the other POJOs have any direct dependencies on Mule code. Figure 5 shows the class hierarchy and the main invocation points for each.
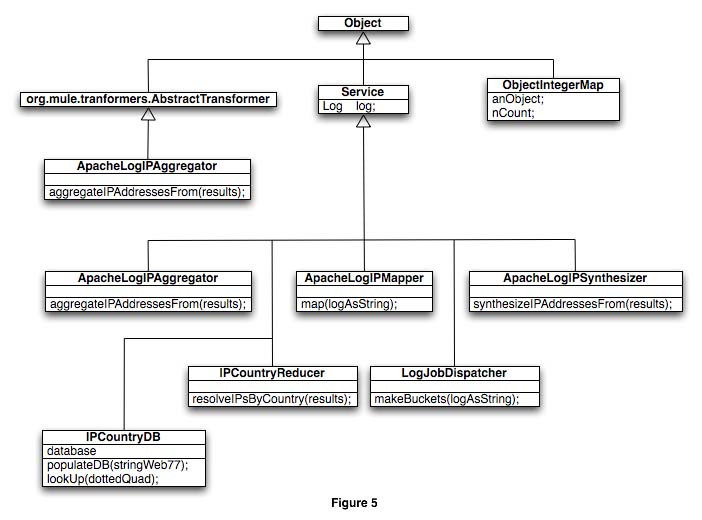
The descriptions of each component’s purpose appears in the same order as they are invoked during a run:
LogJobDispatcher takes an Apache-formatted log file and splits it into buckets of a predefined size.
-
ApacheLogIPMapperextracts the IP address for each log record and creates an ArrayList of objects in the form [String, int], each containing an IP address and the number 1. -
ApacheLogIPSynthesizerreceives an ArrayList of ObjectIntegerMaps and eliminates duplicate entries by adding each IP address to a HashMap and adding the count as the value. This synthesizer helps in expediting the processing time for the next stages, but it’s not strictly required. -
IPCountryReducerprocesses a HashMap of entries and uses the IP addresses (i.e. the keys) to determine which country it came from. The value for each entry in the HashMap is ignored. The component builds another HashMap in which each entry is defined as [country, count] that can the final task uses for taking these intermediate results to calculate the percentage of IP addresses from a given country in relation to the total entries.
The responsibility for identifying the correct type that each of these mapping or reducing components performs was pushed to the implementer. This keeps the code cleaner and simplifies the implementation. The first thing that each of these methods performs is an instanceof check, to verify that the incoming type is something that the component can process. The sacrifice in type checking pays off in time-to-develop. Once the object has been validated through this entry point, the rest of the implementation can be as type-safe as the implementer wishes it to be. Listing 5 shows how this works in the synthesizing component.
public Object synthesizeIPAddressesFrom(Object intermediateResults) {
List list = null;
HashMap<Object, Integer> results = null;
ObjectIntegerMap map;
try {
if (intermediateResults == null) throw new NullPointerException();
if (intermediateResults instanceof List) {
list = (List) intermediateResults;
results = new HashMap<Object, Integer>();
for (Object typelessMap : list) {
if ((typelessMap instanceof ObjectIntegerMap) == false)
throw new IllegalArgumentException();
map = (ObjectIntegerMap) typelessMap;
if (!results.containsKey(map.anObject))
results.put(map.anObject, map.nCount);
}
}
}
catch (Exception e) {
log.error("Received intermediateResults as "+intermediateResults);
log.error(e.toString());
}
this.dump(results);
return results;
} // synthesizeIPAddressesFrom
Listing 5
Objects flowing through Mule don’t need to be in a specific format. Mule message payloads can be in any text or binary format. Unless otherwise specified by a protocol handler, router, or transformer, Mule will try to move objects around as either byte arrays or Strings. Protocol handlers make assumptions about the content type (e.g. text/plain, text/html, or text/xml for HTTP) based on the transports used at an endpoint. Our implementation deals with native Java objects for expediency of implementation and processing. Since Mule can’t readily figure out what an object is, it makes its best guess based on the object’s type, and will usually default to byte array. This makes it impossible to natively pass objects across endpoints and still be able to identify their type for our MapReduce implementation, since it relies in low-level protocols like vm:// (JVM memory pipe) or tcp:// (raw socket) for speed and ease of implementation.
The solution to this issue is simple and elegant. The Mule integration platform ships with several transformers for various protocols and data formats. Data can be compressed, mapped as a hex dump, represented as a string, mapped as a SOAP object, etc. by inserting transformers in the inbound or outbound endpoints. The solution to the format transfer issue appears in figure 6: use the built-in ByteArrayToSerializable and SerializableToByteArray transformers. This adds a bit of overhead as objects travel across endpoints but the performance penalty is negligible when compared against the processing time necessary for a mapping or reduction task.
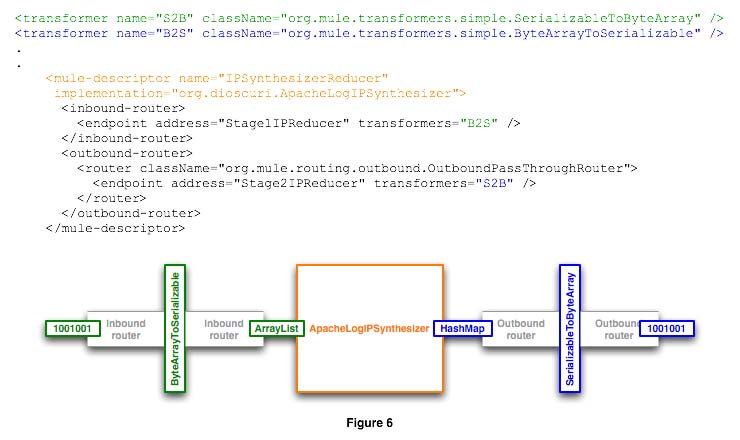
If the requirement existed to lay a grid in which the mappers or reducers can only be accessed through JMS or web services, for example, the configuration files would only change to add the corresponding connector and endpoint reference, and the applicable payload transformers (e.g. Java object to SOAP).
Support Classes
The IpToCountry database is an open-source, GPL’d database that comes in the form of a CSV. It contains ranges of IP addresses and their corresponding country of origin. Example 3 shows a partial listing from it.
# IP FROM IP TO REGISTRY ASSIGNED CTRY CNTRY COUNTRY . . "671088640","687865855","ARIN","672364800","US","USA","UNITED STATES" "687865856","689963007","AFRINIC","1196035200","ZA","ZAF","SOUTH AFRICA" "699400192","699465727","AFRINIC","1183593600","EG","EGY","EGYPT" . .
Example 3
Webnet77 makes the IpToCountry database available free of charge as a gzipped file from their web site. Webnet77 suggests downloading the file once or twice a week. This MapReduce application uses IpToCountry too, exposes look up methods that take an IP address as an argument, and return the country name. As a matter of convenience, the IPCountryDB object was defined and instantiated in Mule, using a file endpoint to consume the IpToCountry.csv database. Figure 7 shows how the void IPCountryDB.populateDB(eventContext context) method processes the file when it becomes available at the endpoint.
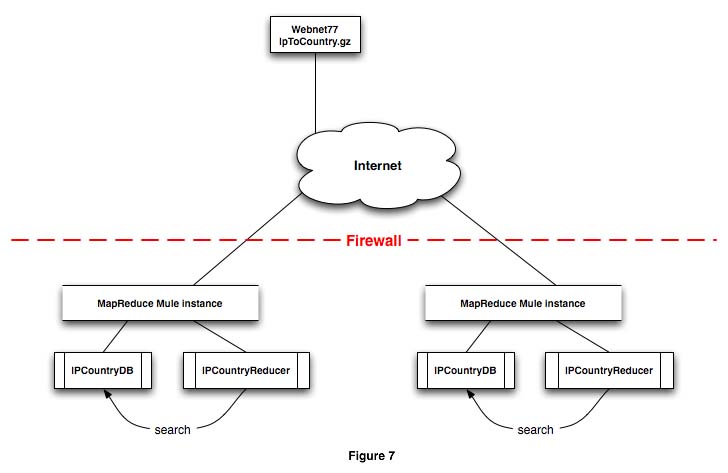
IPCountryDB holds the database in a class variable HashMap. The transformation from octo quads to long integer values for the IP addresses, as well as the search mechanisms, are implemented as class methods as well. If an instance of IPCountryDB exists in the same JVM as the IPCountryReducer component, then queries can run in-memory by direct method invocation. The IpToCountry.gz file is loaded either through a cron job or using an org.mule.providers.http.HttpConnector in the endpoint to poll the Webnet77 site. Once the IpToCountry.gz file is decompressed, beware that it occasionally has a few leading blank lines. This can cause a file endpoint to ignore the contents and the IPCountryDB objects won’t be initialized. Listing 6 shows a simple way to remove these empty lines from the command line or in a cron job.
curl -s http://software77.net/cgi-bin/ip-country/geo-ip.pl?action=download | gunzip -c | awk '!/^$/' > IpToCountry.csv
Listing 6
Using File System Endpoints
The file connectors read full files from the file system endpoints and pass them to the processing components as either one long string or a byte array, depending on the file’s contents. Mule can be configured for returning a file descriptor or for streaming but those discussions are outside the scope of this presentation.
If the initial raw data or the buckets are stored in the file system then ensure that the files are complete before the mappers or reducers begin processing from the file system. Listing 7 shows one of the simplest ways to achieve this is by using a time flag.
<connector name="FileSystemRepository"
className="org.mule.providers.file.FileConnector">
<properties>
<property name="pollingFrequency" value="2000" />
<property name="fileAge" value="2000" />
<map name="serviceOverrides">
<property name="inbound.transformer"
value="org.mule.providers.file.transformers.FileToString" />
</map>
</properties>
</connector>
Listing 7
The LogJobDispatcher and the IPCountryDB components use this FileSystemRepository connector to acquire their data. The files may take a long time to download or copy to the endpoint. The fileAge attribute prevents the components from receiving the file before it’s ready. The connector won’t open a file until it hasn’t changed in 2000 milliseconds or more. Adjust this value depending on system conditions, buffering profile, or other platform-specific run-time attributes. Coders may use the list of all file connector properties for fine-tuning connector and endpoint behavior.
Deploying the MapReducers
The most common method of deploying a Mule application consists of defining its run-time parameters in a configuration file, and deploying any application-related .jar or .class files to the $MULE_HOME/user directory. Mule automagically detects these and loads them into memory as needed. It’s possible to deploy the same set of configuration files, and all the components, to every Mule instance in the processor farm since the inbound endpoints will be unique per machine. A component will not be used unless it receives data from an inbound endpoint. Even if every server has the same configuration file, configuration routing dispatches the intermediate or final results to the appropriate endpoint for processing in the next stage.
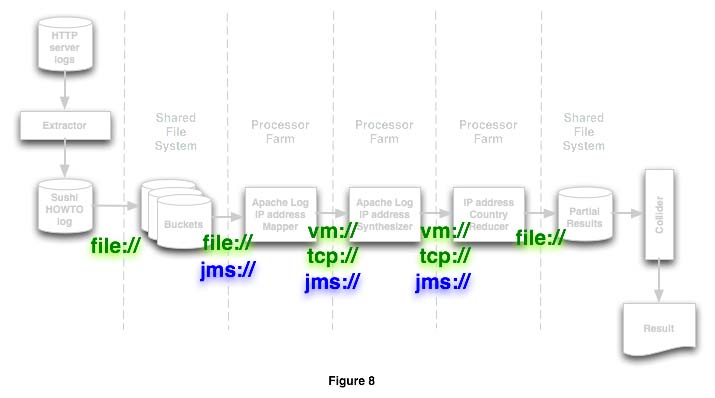
Figure 8 shows how the intermediate results flow betweens stages. All the file:// endpoints exist in a shared file system. The stages showing either vm:// or tcp:// endpoints indicate that the component may receive processing payloads from either type of connection. The testing application defined in figure 2 corresponds to the stages in figure 8. No code changes are necessary to support either, or other transports. Listing 8 shows some configuration alternatives for achieving the same result.
<endpoint-identifier name="Stage1IPReducer" value="vm://s1_ip_reducer" /> <endpoint-identifier name="Stage2IPReducer" value="vm://s2_ip_reducer" /> <!-- <endpoint-identifier name="Stage1IPReducer" value="tcp://localhost:31415" /> <endpoint-identifier name="Stage2IPReducer" value="tcp://localhost:27182" /> <endpoint-identifier name="Stage1IPReducer" value="jms://s1_reducer.queue"/> <endpoint-identifier name="Stage2IPReducer" value="jms://s2_reducer.queue"/> -->
Listing 8
Although the sample configuration file used for this article has hard-coded values, Mule supports both a catchall strategy and filter-based routing. The filters can analyze the payload contents or envelope and route it to the appropriate endpoint dynamically, as shown in Mule: A Case Study.
The sample deployment for the configuration used in this article appears in figure 9. All the endpoints in the processor farm are explicit. This can be cumbersome to manage if there is a large number of processors and endpoints.
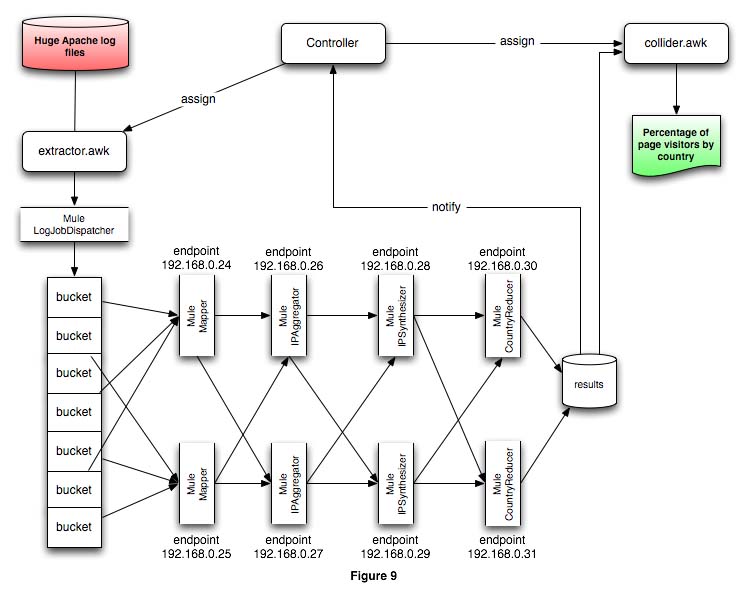
In this scenario, the configuration files for every stage would have to define the explicit IP address or server name for every server in the following processing stage. Such an environment would be unwieldy, and the environment management cost would negate the time and cost benefits of having distributed computing resources. An initial solution to this problem appears in figure 10.
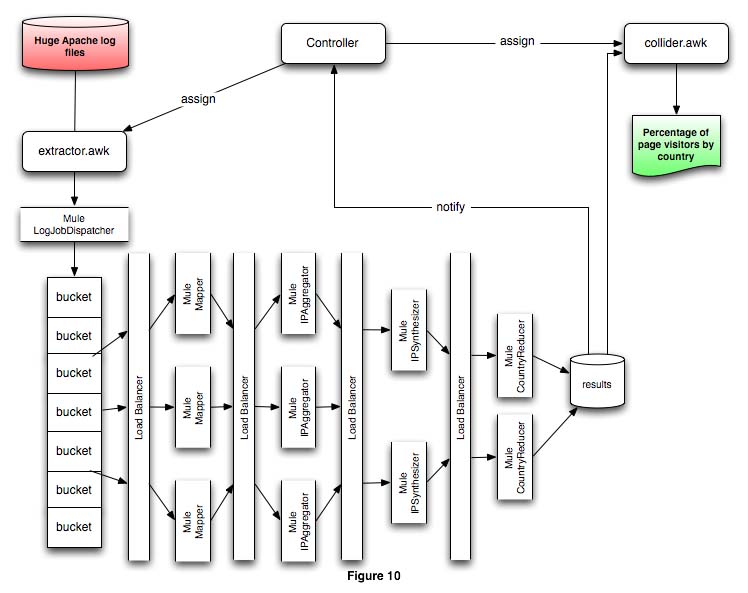
This setup alleviates the configuration management issue by defining a single endpoint for each processing stage. Any number of processing nodes may exist behind each stage’s load balancer.
The section Environment Configuration and Java Code discussed how the same code and configuration files could live across all nodes in the processor farm. Figure 11 shows an even better topology than the previous configurations in this section.
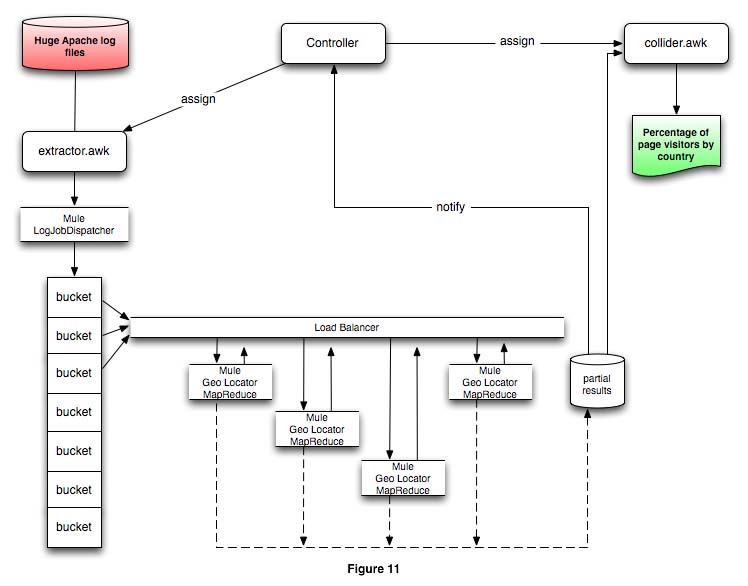
The configuration in figure 11 is possible because this MapReduce implementation is stateless. All data flows go back to the load balancer that re-distributes the payloads among the systems in the processor farm. Routing rules in both the load balancer and each processing node direct payloads to either vm:// in-memory endpoints for multi-core systems, or to tcp:// (or other network protocol) endpoints through the load balancer.
The initial log data extraction and the final processing of all partial results were done in awk for conveniency. Right tool, right job. They could be implemented in any other language or as a Mule component. Example 9 shows the format for the partial results in each dynamically-generated output file stored at the shared file://./results endpoint.
. . UKRAINE=2 UNITED KINGDOM=20 UNITED STATES=365 URUGUAY=1 VIET NAM=2 ZZ=224
Example 9
This MapReduce system’s output is one or more files, up to the number of buckets fed into the system in the first stage, written to the shared file system. Each file has a unique name based on the FileConnector’s outputPattern configuration as seen in example 10.
results in: . . -rw-r--r-- 228 Apr 23 eeb87a47-11ab-11dd-888f-b90970388435.dat -rw-r--r-- 228 Apr 23 eebb125f-11ab-11dd-888f-b90970388435.dat -rw-r--r-- 1197 Apr 23 ff559aa6-11ac-11dd-9639-e94d1d1eac96.dat . .
Example 10
These partial result sets are fed to collider.awk, the program shown in listing 9.
#!/usr/bin/awk -f
# collider.awk
BEGIN {
nTotal = 0;
FS = "=" # Field separator
} # BEGIN
# *** General purpose functions ***
function printResultsForHumans() {
for (country in countryList)
printf("%s has %d unique visitors, %2.2f%%n",
country, countryList[country], 100.0*(countryList[country]/nTotal));
} # printResultsForHumans
function printTabDelimitedResults() {
print("CountrytCounttPercentage");
for (country in countryList)
printf("%st%dt%0.4fn",
country, countryList[country], (countryList[country]/nTotal));
} # printTabDelimitedResults
# *** Main program ***
{
# Field Contents
# ----- --------
# $1 country name
# $2 number of IPs seen from country
countryList[$1] += $2;
nTotal += $2;
} # main loop
END {
# printResultsForHumans();
printTabDelimitedResults();
} # END
Listing 9
collider.awk collates all these files arrive at the final product in response to signal a from the controller or by periodically polling the partial results sets.
Results and Sample Output
The MapReduce setup was tested with a log sample of 287,722 lines. This sample is large enough to give significant results, yet small enough to run in less than minute even in a single-core system. Table 1 shows the performance of the MapReduce framework under various processor farm configurations and transports.
No. Cores |
Connection type |
Bucket size (lines) |
Time (in seconds) |
1 |
vm:// |
287,722 |
36.4 |
2 |
vm:// |
20,000 |
23.7 |
1 |
tcp:// |
287,722 |
38.6 |
2 |
tcp:// |
20,000 |
24.7 |
4 |
tcp:// |
20,000 |
14.7 |
Table 1
The mappers and reducers spent a lot of time writing informational messages to stdout, which added significant overhead but is useful for testing. Network connections also caused overhead, in the order of an additional 270 milliseconds per thread/bucket using the tcp:// endpoint. If the bucket sizes were bigger, however, the connection overhead would remain constant and take less time in relation to the tasks. Shared file system access was constant for all tests.
Figure 12 shows the output from collider.awk after post-processing in a spreadsheet.
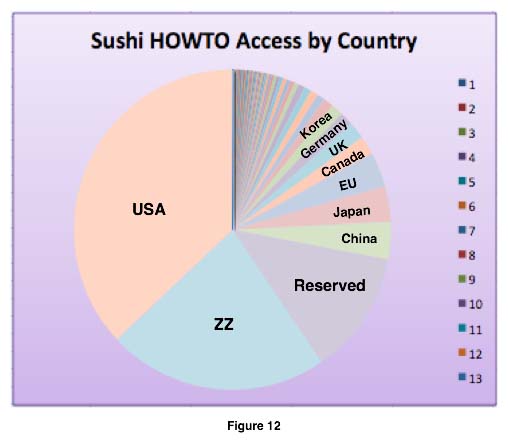
This process could also be automated by adding endpoints that provide JOpenChart and iText components that generate PDF files in real-time, or any other reporting or indexing function.
A Sun T5220 server, capable of running 64 concurrent threads was evaluated as an in-box processor farm, as shown on figure 13, and compared against solving the same task on a dual-core x86 processor, using the default 10 thread configuration. Mule was set for a maximum of either 10 or 64 threads for the tests, with varying bucket sizes.
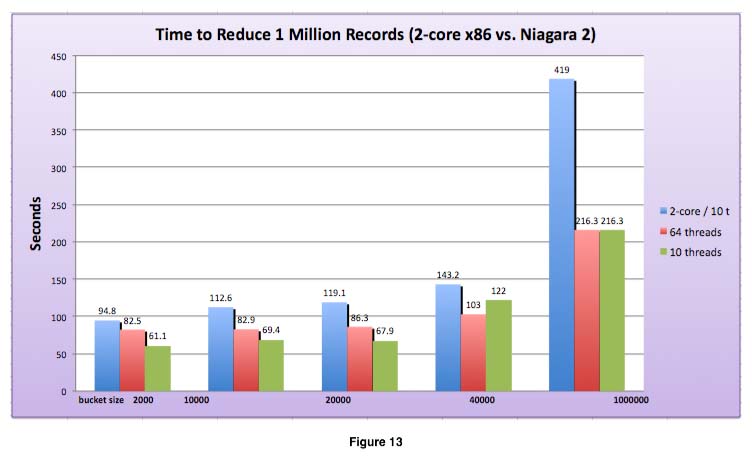
Disk I/O appears to be the cause of poor performance; the bigger the buckets and the partial result sets, the longer it takes to complete. It’s not surprising that Google and Hadoop came up with custom file systems. The system spends a lot of time reading the buckets and writing the results. Data manipulation can be entirely done in-memory, since individual buckets can be optimized for maximum memory size on the processor where they are executed, for improving throughput.
The MapReduce system uses the standard logs for progress and exception messaging, and the event triggers and intermediate results reside in the file system. Here is a list of examples of each of these:
- Output from a small sample run showing all processing stages through the mappers and reducers
- Directory listing showing the intermediate results files before collider.awk generates the final product
- All intermediate result files from every IPCountryReducer task
- The final product file with the page view percentages per country in human-readable form
What’s Next?
The technology described in this article represents the start of a production-ready MapReduce system. It leverages a company’s investment in Java and system integration technology, and opens the door to near-future expansion.
All the code, configuration files, and log samples used for producing this article are available at the Dioscuri Project. This code is only the foundation of a more robust MapReduce system, poised to evolve toward solving mission-critical problems. What comes next? Perhaps...
- Define a simple class hierarchy for components running in Dioscuri, with a focus on simplicity of design
- Have the ability to send classes across the network, and to download those without having to re-start Mule
- The inclusion of Dioscuri among the MuleForge development projects
- Support for the Mule 2.0 integration platform
- Integration with mainstream grid computing platforms like Terracotta for collating the intermediate results for the final product
The current effort in Dioscuri is focused on development of the dynamic component loading across Mule instances. The basics are simple: make a component’s class or .jar available for deployment, send the bundle across the network to the Mule instances, and have a dedicated component that dynamically loads the new component and its run-time configuration into memory. This would reduce downtime and reconfiguration issues in a Dioscuri processor farm. The basic configuration file, connectors, and endpoints already exist in the configuration file for this article. Later versions of Mule will support OSGi bundles, greatly simplifying how Dioscuri applications could be deployed.
This article is based on Mule 1.5.1 but upgrading components and configurations to Mule 2.0 is a simple undertaking. The 1.x version of the map-reduce-client-geolocator.xml has a Mule 2.x compatible equivalent also available for download. Mule 1.5.1 was preferred to meet the design goal of leveraging production-ready components. Mule 2.0 Enterprise Edition, with the kind of support required for a mission-critical environment, isn't available at the time this was implemented.
About the Author
Eugene Ciurana is an open-source software evangelist, the Director of Systems Infrastructure at LeapFrog Enterprises, a frequent speaker at several Java technology and SOA gatherings worldwide, an open-source evangelist, and a contributing editor to TheServerSide.com. He can be reached in the IRC universe (##java, #awk, #esb, #iphone) under the /nick pr3d4t0r. This article benefitted from the suggestions and technical reviews provided by these Java professionals: Karl Avedal, Benoit Chaffanjon, Nick Heudecker, Gene Ladd, Justin Lee (##java), Ross Mason, David R. McIver (#scala), Joseph Ottinger, Dave Rosenberg, Jason Whaley, Nick Yakoubovsky, and Ari Zilka. Special thanks to Sun Microsystems for facilitating some of the equipment used for this article.
Dig Deeper on Core Java APIs and programming techniques
-
![]()
Certified Professional AWS Solutions Architect Exam Braindumps
By: Cameron McKenzie
-
![]()
AWS Solutions Architect Associate Exam Questions
By: Cameron McKenzie
-
![]()
AWS Solutions Architect Practice Test on all Exam Topics
By: Cameron McKenzie
-
![]()
KnowBe4 catches North Korean hacker posing as IT employee
By: Arielle Waldman



