EJB 3.1 - A Significant Step Towards Maturity
Enterprise Java Beans (EJB) is a server-side component architecture for the Java Enterprise Edition (Java EE) platform, aiming to enable rapid and simplified development for distributed, transactional, secure and portable applications.
Introduction
Enterprise Java Beans (EJB) is a server-side component architecture for the Java Enterprise Edition (Java EE) platform, aiming to enable rapid and simplified development for distributed, transactional, secure and portable applications.
EJB experienced wide adoption in its version 2, reaching a level of maturity which made it capable to embrace the requirements of many enterprise applications. Despite its relative success, there were many critical voices accusing it of being overcomplicated. Lack of a good persistence strategy, long and tedious deployment descriptors, or limited capacity for testing, were some of the many times used arguments, causing a considerable number of developers to look for alternative technologies.
Sun reacted slowly, but it was able to come up with a greatly revised version of the specification, which has considerably enhanced its potential. EJB 3 dealt with most of the existing drawbacks, presenting solutions which got consensual acceptance among the community. EJB became a viable solution again, and many teams which had once put it aside are now using it.
Even though its success, EJB 3 did not go as far as it could. Going back to EJB 2.1, the spec was facing two main challenges: 1) to go through a massive restructuring in order to change existing features, like a powerful persistence framework as a substitute for Entity Beans, support for annotations as a substitute for deployment descriptors, drop of home interfaces, etc; 2) to introduce new solutions for problems not being dealt by the spec like support for Singletons, support for method interception or asynchronous calls to session beans, and to improve existing features like enhancing the Timer Service. Priority was correctly given to the restructuring- "we fist clean and rearrange the house, and only then we bring the new furniture"- even though there were some new features as well, like the support for interceptors. Now that the cleaning is done, it is time to benefit from it and to go one step beyond.
EJB 3.1 introduces a new set of features which intends to leverage the potential of the technology. It is, in my opinion, a release of major importance, which brings capabilities which were most wanted since long ago, making it more able to fulfill the needs of modern enterprise applications, and contributing for an increased adoption.
The EJB 3.1 Proposed Final Draft has been recently released and we are now close to its final version. This article will go through most of the new features, providing a detailed overview about each one of them.
No-Interface View
EJB 3.1 introduces the concept of a no-interface view, consisting of a variation of the Local view, which exposes all public methods of a bean class. Session Beans are not obliged to implement any interface anymore. The EJB container provides an implementation of a reference to a no-interface view, which allows the client to invoke any public method on the bean, and ensuring that transaction, security and interception behave as defined.
All beans' public methods (including the ones defined on the superclasses) are made available through the non-interface view. A client can obtain a reference to this view by dependency injection or by JNDI lookup, just like it happens with local or remote views.
Unlike local and remote views, where the reference consists of the respective local/remote business interface, the reference to a no-interface view is typed as the bean class.
The following code sample demonstrates how a servlet can easily make use of a no-interface view. The client references the no-interface view as a ByeEJB, that is, using the bean class. The EJB does not implement any interface (assume no deployment descriptor is provided). Last but not least, the reference to the EJB is obtained by simple dependency injection.
ByeServlet
(...)
@EJB
private ByeEJB byeEJB;
public String sayBye() {
StringBuilder sb = new StringBuilder();
sb.append("<html><head>");
sb.append("<title>ByeBye</title>");
sb.append("</head><body>");
sb.append("<h1>" + byeEJB.sayBye() + "</h1>");
sb.append("</body></html>");
return sb.toString();
}
(...)
ByeEJB
@Stateless
public class ByeEJB {
public String sayBye() {
return "Bye!";
}
}
The fact that the reference's type is the bean class imposes limitations:
- The client can never use the new operator to acquire the reference.
- An EJBException will be thrown if any method other than the public method is invoked.
- No assumption can be made about the internal implementation of the no-interface view. Even though the reference corresponds to the type of the bean class, there is no correspondence between the reference implementation and the bean implementation.
A reference to this view can be passed as parameter/return value of any local business interface or other no-interface view methods.
If the bean does not expose any local or remote views then the container must make a no-interface view available. If the bean exposes at least one local or remote view then the container does not provide a no-interface view unless explicitly requested, using the annotation LocalBean.
All public methods of the bean, and its superclasses, are exposed through the no-interface view. That means any public callback methods will be exposed as well, and therefore caution must be exercised at this level.
This feature will allow to avoid writing interfaces, simplifying development. It might be that the future will bring remote no-interface views.
Singleton
Most of the applications out there have experienced the need of having a singleton bean, that is, to have a bean that is instantiated once per application. A big number of vendors has provided support for such need, allowing the maximum number of a bean's instances to be specified in the deployment descriptor. It goes without saying that these workarounds break the "write once deploy everywhere" principle, and therefore it was up to the spec to standardize the support for such feature. EJB 3.1 is finally introducing singleton session beans.
There are now three types of session beans- stateless, stateful and singleton. Singleton session beans are identified by the Singleton annotation and are instantiated once per application. The existing instance is shared by clients and supports concurrent access.
The life of a singleton bean starts whenever the container performs its instantiation (by instantiation it is meant instantiation, dependency injection and execution of PostConstruct callbacks). By default the container is responsible for deciding whenever a singleton bean is created, but the developer can instruct the container to initialize the bean during application startup, using the Startup annotation. Moreover, the Startup annotation permits defining dependencies on other singleton beans. The container must initialize all startup singletons before starting to deliver any client requests.
The following example provides an overview about how dependencies work. The instantiation of singleton A is decided by the container as it does not contain the Startup annotation and no other singleton depends on it. Singleton B is instantiated during application startup and before singleton D and singleton E (E depends on D which depends on B). Even though singleton B does not have the Startup annotation, there are other singletons which have it and that depend on it. Singleton C is instantiated during application startup, before singleton E, and so does singleton D. Finally, singleton E will be the last one to be instantiated during the application startup.
@Singleton
public class A { (...) }
@Singleton
public class B { (...) }
@Startup
public class C { (...) }
@Startup(DependsOn="B")
@Singleton
public class D { (...) }
@Startup(DependsOn=({"C", "D"})
@Singleton
public class E { (...) }
Note that the order defined on a multiple dependency is not considered at runtime. For example, the fact that E depends on C and D does not mean that C will be instantiated before D. Should that be the case then D must have a dependency on C.
A singleton can define a startup dependency on a singleton that exists on another module.
The container is responsible for destroying all singletons during application shutdown by executing their PreDestroy callbacks. The startup dependencies are considered during this process, that is, if A depends on B then B will still be available whenever A is destroyed.
A singleton bean maintains state between client invocations, but this state does not survive application shutdown or container crashes. In order to deal with concurrent client invocations the developer must define a concurrency strategy. The spec defines two approaches:
- Container-managed concurrency (CMC)- the container manages the access to the bean instance. This is the default strategy.
- Bean-managed concurrency (BMC)- the container takes no intervention in managing concurrency, allowing concurrent access to the bean, and deferring client invocation synchronization to the developer. With BMCs it is legal to use synchronization primitives like synchronized and volatile in order to coordinate multiple threads from different clients.
Most of the times CMC will be the choice. The container manages concurrency using locking metadata. Each method is associated to a read or a write lock. A read lock indicates that the method can be accessed by many concurrent invocations. A write lock indicates that the method can only be invoked by one client at a time.
By default the value of the locking attribute is write. This can be changed by using the Lock annotation, which can be applied to a class, a business interface, or to a method. As usual, the value defined at the class level applies to all relevant methods unless a method has its own annotation.
Whenever a method with write locking has concurrent accesses, the container allows one of them to execute it and holds the other ones until the method becomes available. The clients on hold will wait indefinitely, unless the AccessTimeout annotation is used, which allows to define a maximum time (in milliseconds) that a client will wait, throwing a ConcurrentAccessTimeoutException as soon as the timeout is reached.
Following is presented a number of examples, illustrating the use of CMC singleton beans. Singleton A is explicitly defined as a CMC, even though it is not necessary because that is the default concurrency strategy. Singleton B does not define any concurrency strategy, which means that it is a CMC, and defines that the exposed methods make use of write locks. Like it happens with singleton A, singleton B would not need the use of the Lock annotation because by default all CMCs use a write lock. Singleton C uses read locks for all methods. The same for singleton D, with the difference that the method sayBye will have a write lock. Finally, singleton E makes use of write locks to all relevant methods, and any blocked client will get a ConcurrentAccessTimeoutException after being on hold for 10 seconds.
@Singleton
@ConcurrencyManagement(CONTAINER)
public class A { (...) }
@Singleton
@Lock(WRITE)
public class B { (...) }
@Singleton
@Lock(READ)
public class C { (...) }
@Singleton
@Lock(READ)
public class D {
(...)
@Lock(WRITE)
public String sayBye() { (...) }
(...)
}
@Singleton
@AccessTimeout(10000)
public class E { (...) }
In case of clustering, there will be an instance of the singleton per every JVM where the application gets deployed.
Up to EJB 3, any system exception thrown by an EJB would cause the respective instance to be discarded. That does not apply to singleton beans, because they must remain active until the shutdown of the application. Therefore any system exception thrown on a business method or on a callback does not cause the instance to to be destroyed.
Like it happens with stateless beans, singletons can be exposed as web services.
Asynchronous Invocations
Asynchronous invocations of session beans methods is one of the most important new features. It can be used with all types of session beans and from all bean views. The spec defines that with asynchronous invocations the control must return to the client before the container dispatches the invocation to the bean instance. This takes the use of session beans into a whole new level, permitting the developer to take benefit from the potential of having asynchronous invocations to session beans, allowing a client to trigger parallel processing flows.
An asynchronous method is signaled through the Asynchronous annotation, which can be applied to a method or to a class. The following examples illustrate different use cases of the annotation. Bean A makes all its business methods asynchronous. Singleton B defines the method flushBye as asynchronous. For stateless C all methods invoked by its local interface Clocal are asynchronously invoked, but if invoked through the remote interface then they are synchronously invoked. Therefore the invocation of the same method behaves differently depending on the used interface. Last, for bean D the method flushBye is invoked asynchronously whenever invoked through the bean's local interface.
@Stateless
@Asynchronous
public class A { (...) }
@Singleton
public class B {
(...)
@Asynchronous
public void flushBye() { (...) }
(...)
}
@Stateless
public class C implements CLocal, CRemote {
public void flushBye() { (...) }
}
@Local
@Asynchronous
public interface CLocal {
public void flushBye();
}
@Remote
public interface CRemote {
public void flushBye();
}
@Stateless
public class D implements DLocal { (...) }
@Local
public interface DLocal {
(...)
@Asynchronous
public void flushBye();
(...)
}
The return type of an asynchronous method must be void or Future<V>, being V the result value type. If void is used then the method cannot declare any application exception.
The interface Future was introduced with Java 5 and provides four methods:
- cancel(boolean mayInterruptIfRunning)- attempts to cancel the execution of the asynchronous method. The container will attempt to cancel the invocation if it has not yet been dispatched. Should the cancellation be successful the method returns true, false otherwise.ThemayInterruptIfRunningflagcontrolswhether, inthecasethattheasynchronousinvocation cannotbecanceled, the target bean should have visibility to the client's cancel attempt.
- get- returns the method's result whenever it gets complete. This method has two overloaded versions, one that blocks until the method completes, another which takes a timeout as parameter.
- isCancelled- indicates if the method was cancelled.
- isDone- indicates if the method was completed successfully.
The spec mandates that the container provides the class AsyncResult<V>, consisting of an implementation of the interface Future<V> which takes the result value as constructor's parameter.
@Asynchronous
public Future<String> sayBye() {
String bye = executeLongQuery();
return new AsyncResult<String>(bye);
}
The use of the Future<V> return type has only to be visible from the point of view of the client. So if method m is only defined as asynchronous on an interface then only the method declaration in the interface must return Future<V>, the one in the bean class (and in any other business interface) can define V as return type.
@Stateless
public class ByeEJB implements ByeLocal, ByeRemote {
public String sayBye() { (...) }
}
@Local
@Asynchronous
public interface sayBye {
public Future<String> flushBye();
}
@Remote
public interface ByeRemote {
public String sayBye();
}
The SessionContext interface has been enhanced with the method wasCancelCalled, which returns true if the method Future.cancel was invoked by the client, setting the parameter mayInterruptIfRunning as true.
@Resource
SessionContext ctx;
@Asynchronous
public Future<String> sayBye() {
String bye = executeFirstLongQuery();
if (!ctx.wasCancelCalled()){
bye += executeSecondLongQuery();
}
return new AsyncResult<String>(bye);
}
Note that the method get of the interface Future declares ExecutionException in its throws clause. If the asynchronous method throws an application exception then this exception will get propagated to the client via an ExecutionException. The original exception is available by invoking the method getCause.
@Stateless
public class ByeEJB implements ByeLocal {
public String sayBye() throws MyException {
throw new MyException();
}
}
@Local
@Asynchronous
public interface ByeLocal {
public Future<String> sayBye();
}
//Client
@Stateless
public class ClientEJB {
@EJB
ByeLocal byeEjb;
public void invokeSayBye() {
try {
Future<String> futStr = byeEjb.sayBye();
} catch(ExecutionException ee) {
String originalMsg = ee.getCause().getMessage();
System.out.println("Original error message:" + originalMsg);
}
}
}
The client transaction context does not get propagated into the asynchronous method execution. Therefore one can conclude that whenever an asynchronous method m gets invoked:
- If m is defined with REQUIRED as transaction attribute then it will always work as REQUIRES_NEW.
- If m is defined with MANDATORY as transaction attribute then it will always throw a TransactionRequiredException.
- If m is defined with SUPPORTS as transaction attribute then it will never run with a transaction context.
In terms of security the propagation of the principal takes place in the same exact way than it does for synchronous methods.
Global JNDI names
This feature was long waited, and has finally seen the light of the day with EJB 3.1. The assignment of global JNDI names to EJBs was always implemented in a vendor-specific way, being source of many issues. The same application deployed in containers from different vendors is likely to get its session beans assigned with different JNDI names, causing problems on the client side. Additionally, with the support for EJB 3 some vendors made business local interfaces available on the global JNDI tree, while others have filtered them out, causing problems as well.
The spec now defines global JNDI names, by which session beans are required to be registered . In other words, we finally have portable JNDI names.
Each portable global JNDI name has the following syntax:
java:global[/<app-name>]/<module-name>/<bean-name>[!<fully-qualified-interface-name>]
The following table describes the different components:
Component |
Description |
Mandatory |
app-name |
Name of the application where the bean gets packaged. Defaults to the name of the ear (without extension) unless specified in the file application.xml |
N |
module-name |
Name of the module where the bean gets packaged. Defaults to the name of the bundle file (without extension) unless specified in the file ejb-jar.xml |
Y |
bean-name |
Name of the bean. Defaults to the unqualified name of the session bean class, unless specified on the name attribute of the annotation Stateless/Stateful/Singleton or in the deployment descriptor. |
Y |
Fully-qualified-interface-name |
Qualified name for the exposed interface. In case of a no-interface view it consists of the fully qualified name of the bean class. |
Y |
If a bean exposes just one client view then the container must make that view available not only on the JNDI name presented before but also on the following location:
java:global[/<app-name>]/<module-name>/<bean-name>
The container is also required to make the JNDI names available on the java;app and java:module namespaces, in order to simplify the access from clients in the same module and/or application:
java:app[/<module-name>]/<bean-name>[!<fully-qualified-interface-name>]
java:module/<bean-name>[!<fully-qualified-interface-name>]
java:app is used by clients executing in the same application than the target bean. The module name is optional for standalone modules. java:module is used by clients execution in the same module than the target bean.
Example1:
Packaged in mybeans.jar within myapp.ear without deployment descriptors
package com.pt.xyz;
@Singleton
public class BeanA { (...) }
BeanA has a no-interface view available with the following JNDI names:
- java:global/myapp/mybeans/BeanA
- java:global/myapp/mybeans/BeanA!com.pt.xyz.BeanA
- java:app/mybeans/BeanA
- java:app/mybeans/BeanA!com.pt.xyz.BeanA
- java:module/BeanA
- java:module/BeanA!com.pt.xyz.BeanA
Example2:
Packaged in mybeans.jar without deployment descriptors
package com.pt.xyz;
@Stateless(name="MyBeanB")
public class BeanB implements BLocal, BRemote { (...) }
package com.pt.xyz;
@Local
public interface BLocal { (...) }
package com.pt.abc;
@Remote
public interface BRemote { (...) }
BLocal will be available with the following JNDI names:
- java:global/mybeans/MyBeanB!com.pt.xyz.BLocal
- java:app/MyBeanB!com.pt.xyz.BLocal
- java:module/MyBeanB!com.pt.xyz.BLocal
BRemote will be available with the following JNDI names:
- java:global/mybeans/MyBeanB!com.pt.abc.BRemote
- java:app/MyBeanB!com.pt.abc.BRemote
- java:module/MyBeanB!com.pt.abc.BRemote
Timer-Service
A significant number of enterprise applications have some sort of time-driven requirements. For a long time the spec has ignored such needs, forcing developers to find non-standard solutions like Quartz or Flux. EJB 2.1 introduced the Timer Service, consisting of a service provided by the container that allows EJBs to have timer callbacks being invoked at specified times. Moreover, such invocations can be done in a transactional context.
Even though the Timer Service was able to bridge some of the necessities, there were considerable limitations, like for example:
- All timers have to be created programatically.
- Lack of flexibility in the scheduling of timers.
- Missing support for the use of timers in environments with multiple JVMs like clustering.
With EJB 3.1 there are two ways to create timers:
-
Programatically, using the already existing TimerService interfaces. This interface has been greatly enhanced in order to provide more flexibility while creating timers.
- Declaratively, using annotations or the deployment descriptor. This way a timer can be statically defined so it is automatically created during application startup.
The annotation Schedule is used to automatically create a timer, taking as parameter the corresponding timeout schedule. It is applied to a method which will be used as timeout callback. While with programatically created timers the timeout method is the same for all timers belonging to the same bean (ejbTimeout if the bean implements the TimedObject interface, method annotated with Timeout otherwise), for declaratively created timers the timeout method is the one where the Schedule annotation is applied to. In the following example two timers are defined, one which expires every Monday at midnight and another one which expires every last day of the month. The first annotates the method itIsMonday, which is the method that will get executed at the timer's expiration time. The second one annotates the method itIsEndOfMonth, which works as timeout callback for that timer.
@Stateless
public class TimerEJB {
@Schedule(dayOfWeek="Mon")
public void itIsMonday(Timer timer) { (...) }
@Schedule(dayOfMonth="Last")
public void itIsEndOfMonth(Timer timer) { (...) }
}
A method can be annotated with more than one timer, like shown below, where two timers are defined for the method mealTime, one which will expire every day at 1pm and another expiring at 8pm.
@Stateless
public class MealEJB {
@Schedules(
{ @Schedule(hour="13"),
@Schedule(hour="20")
}
public void mealTime(Timer timer) { (...) }
}
Both automatic or programatically created timers can now be persistent (default) or non-persistent. Non-persistent timers do not survive an application shutdown or container crashes. They can be defined using the attribute persistent of the annotation, or the class TimerConfig passed as parameter to the method createTimer in the TimerService interface. The interface Timer has been enhanced in order to include the method isPersistent.
Each Schedule annotation for persistent timers corresponds to a single timer, regardless the number of JVMs across which the application is distributed. This has a tremendous impact on the way timers are used in clustered environments. Lets assume that an application needs to keep an active timer pointing to the next active event. This timer gets updated as soon as new events are submitted. Before EJB 3.1 this would be quite easy to achieve by using the Timer Service, unless the application got deployed in a container distributed in more that one JVM. In that case, whenever a timer got created in one JVM it would not visible in the remaining JVMs. That means that it must have been adopted a strategy which allows the existing timers to be visible in all JVMs. The code becomes aware of the environment where it gets deployed, which leads to bad practices. With EJB 3.1 the developer does not have to care if the application being developed is going to be deployed across multiple JVMs, such task is left up to the container.
An automatically created non-persistent timer gets a new timer created for each JVM across which the container is deployed.
The signature of the timeout callback method can be one of two options- void <METHOD> (Timer timer) or void <METHOD> ().
In terms of timer scheduling there were major improvements. The callback schedule can be expressed using a calendar-based syntax modeled after the UNIX cron. There are eight attributes which can be used in such expressions:
Attribute |
Allowable Values |
Example |
second |
[0, 59] |
second = "10" |
minute |
[0, 59] |
minute = "30" |
hour |
[0, 23] |
hour = "10" |
dayOfMonth |
- [1, 31] - day of the month - Last - last day of the month - -[1, 7] - number of days before end of month - {"1st", "2nd", "3rd", "4th", "5th", ..., "Last"} {"Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"}- identifies a single occurrence of a day of the month |
dayOfMonth = "3" dayOfMonth = "Last" dayOfMonth = "-5" dayOfMonth = "1st Tue" |
month |
- [1, 12] - month of the year - {"Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"}- month name |
month = "7" month = "Jan" |
dayOfWeek |
- [0, 7]- day of the week where both 0 and 7 refer to Sunday - {"Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"}- day's name |
dayOfWeek = "5"
dayOfWeek = "Wed" |
year |
Four digit calendar year |
year = "1978" |
timezone |
Id of the related timezone |
timezone = "America/New_York" |
The values provided for each attribute can be expressed in different forms:
Expression Type |
Description |
Example |
Single Value |
Constraints the attribute to just one value |
dayOfWeek = "Wed" |
Wild Card |
Represents all possible values for a given attribute |
month = "*" |
List |
Constraints the attribute to two or more allowable values, separated by a comma |
DayOfMonth = "3,10,23" dayOfWeek = "Wed,Sun" |
Range |
Constraints the attribute to an inclusive range of values |
year = "1978-1984" |
Increments |
Defines an expression x/y where the attribute is constrained to every yth value within the set of allowable values, beginning at time x. |
second = "*/10" - every 10 seconds hour = "12/2"- every second hour starting at noon |
Every Tuesday at 7.30am @Schedule(hour = "7", minute = "30", dayOfWeek = "Tue") From Monday to Friday, at 7, 15 and 20 @Schedule(hour = "7, 15, 20", dayOfWeek = "Mon-Fri") Every hour on Sundays @Schedule(hour = "*", dayOfWeek = "0") Last Friday of December, at 12 @Schedule(hour = "12", dayOfMonth = "Last Fri", month="Dec") Three days before the last day of the month, for every month of 2009, at 8pm @Schedule(hour = "20", dayOfMonth = "-3", year="2009") Every 5 minutes of every hour, starting at 3pm @Schedule(minute = "*/5", hour = "15/1")
The TimerService interface has been enhanced in order to allow programatically created timers to make use of cron alike expressions. Such expressions can be represented by an instance of the class ScheduleExpression, which can be passed as parameter during the timer creation.
EJB Lite
An EJB container which is compliant with the specification must make available a set of APIs. This set is now divided in two categories- minimum and complete. The minimum set is designated as EJB 3.1 Lite, and provides a subset of features which can be used by applications (EJB 3.1 Lite applications) which do not need the full range of APIs provided by the spec. This brings several advantages:
- Increases the performance. By reducing the number of APIs the container becomes lighter and therefore can provide its services in a more performant way.
- Facilitates the learning curve. Learning how to be an EJB developer is not a simple task, forcing developers to learn an extensive number of matters. In order to develop EJB Lite applications, developers will now have to deal with a smaller and easier learning curve, increasing their productivity.
- Reduces licensing cost. A complain that is often heard is the fact that the container's license price is the same regardless the number of APIs the application uses. An application having few simple stateless beans runs on the same container than an application making full use of all EJB APIs, and therefore gets charged with similar licensing fees. By having EJB Complete and EJB Lite versions, vendors can introduce different licensing prices. An application can now pay for what it really uses.
EJB 3.1 Lite includes the following features:
- Stateless, stateful and singleton session beans. Only local and no-interface views and only synchronous invocations.
- Container-Managed Transactions and Bean-Managed Transactions.
- Declarative and programmatic security.
- Interceptors.
- Deployment descriptors.
Simplified EJB Packaging
An ejb-jar file is a module intended to package enterprise beans. Before EJB 3.1 all beans had to be packaged in such file. Since a considerable part of all Java EE applications is composed by a web front-end and a EJB back-end it means that the ear containing the application will have to be composed by two modules, a war and an ejb-jar. This is a good practice in the sense that structures the separation between front-end and back-end. But it is too much for simple applications.
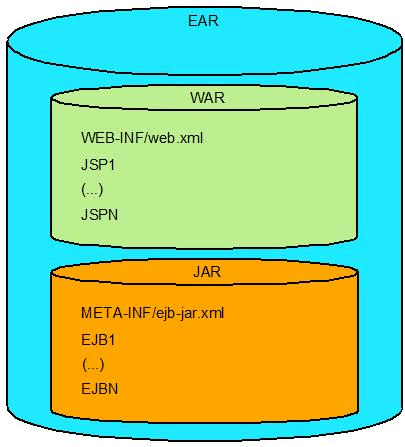
EJB 3.1 allows enterprise beans to be packaged in a war file. The classes can be included in the WEB-INF/classes directory or in a jar file within WEB-INF/lib. A war can contain at most one ejb-jar.xml, which can be located in WEB-INF/ejb.jar.xml or in META-INF/ejb-jar.xml in a WEB-INF/lib jar file.
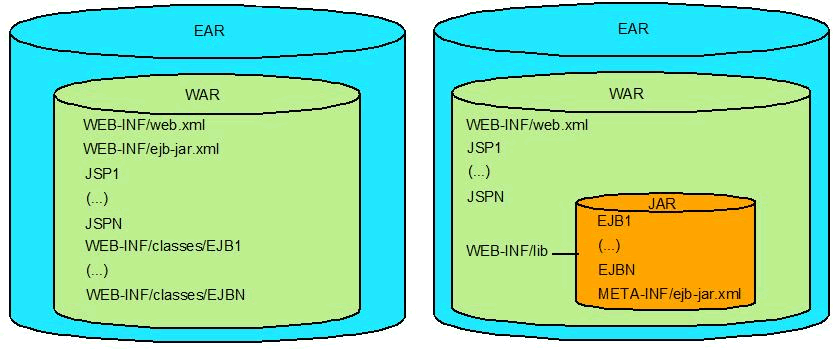
It must be stressed that this simplified packaging should only be utilized in simple applications. Otherwise it should still be used the traditional approach with war and ejb-jar files.
Embeddable EJB Containers
EJBs are traditionally associated to heavy Java EE containers, making it difficult to use them in certain contexts:
- It is hard to unit test beans.
- A simple standalone batch process cannot benefit from the use of EJBs unless there is a Java EE container providing the necessary services.
- Complicates the use of EJBs in desktop applications.
One of the EJB 3.1 most significant features consists of the support for embeddable containers. A Java SE client can now instantiate an EJB container that runs within its own JVM and classloader. The embeddable container provides a set of basic services which allows the client to benefit from the use of EJBs without requiring a Java EE container.
The embeddable container scans the classpath in order to find EJB modules. There are two ways to qualify as an EJB module:
- An ejb-jar file.
- A directory containing a META-INF/ejb-jar.xml file or at least one class annotated as an enterprise bean.
The environment where a bean gets executed is totally transparent, that is, the same bean runs the same exact way on an embeddable container or in a Java EE standalone container, no change in the code is required.
An embeddable container ought to support the EJB 3.1 Lite subset of APIs. Vendors are free to extend such support and to include all EJB 3.1 APIs.
The class EJBContainer plays a central role in the use of embeddable containers. Provides a static method createEJBContainer which allows to instantiate a new container. Provides the method close which triggers the shutdown of the container, causing all PreDestroy callbacks to be executed. Last but not least, it provides the method getContext which returns a naming context that allows the client to lookup references to session beans deployed in the embeddable container.
@Singleton
@Startup
public class ByeEJB {
private Logger log;
@PostConstruct
public void initByeEJB() {
log.info("ByeEJB is being initialized...");
(...)
}
public String sayBye() {
log.info("ByeEJB is saying bye...");
return "Bye!";
}
@PreDestroy
public void destroyByeEJB() {
log.info("ByeEJB is being destroyed...");
(...)
}
}
public class Client {
private Logger log;
public static void main(String args[]) {
log.info("Starting client...");
EJBContainer ec = EJBContainer.createEJBContainer();
log.info("Container created...");
Context ctx = ec.getContext();
//Gets the no-interface view
ByeEJB byeEjb = ctx.lookup("java:global/bye/ByeEJB");
String msg = byeEjb.sayBye();
log.info("Got the following message: " + msg);
ec.close();
log.info("Finishing client...");
}
}
Log output
Starting client...
ByeEJB is being initialized...
Container created...
ByeEJB is saying bye...
Got the following message: Bye!
ByeEJB is being destroyed...
Finishing client...
Best of the Rest
Besides the big new features, there are few minor improvements which simplify or leverage existing functionalities. From those, the following are the most relevant:
- A stateful can now use the annotations AfterBegin, BeforeCompletion and AfterCompletion instead of implementing the SessionSynchronization interface.
- It can now be specified a timeout for a stateful bean, which consists of the amount of time a stateful bean can remain idle before being removed by the container. The StatefulTimeout annotation was created for such effect.
- A container is required to serialize invocations to stateless and stateful beans. By default, it is allowed to have concurrent calls to stateful beans, and it is up to the container to serialize them. The developer can now use the ConcurrencyManagement(CONCURRENCY_NOT_ALLOWED) annotation in order to indicate that a stateful bean does not support concurrent requests. In that case, whenever a stateful bean is processing a client invocation, and a second one arrives (from the same client or from a different one), the second invocation will get a ConcurrentAccessException.
- The annotation AroundTimeout can be used to define interceptor methods for timer's timeout methods.
Conclusions
Java EE 6 is now about to be finalized, and most of the technologies which exist in its universe are getting close to their final versions, and fulfilling almost all expectations. 2009 will definitely be a strong year for Java EE.
Few of the most exciting new features are coming with EJB 3.1. EJB 3.1 provides architects and developers with a rich set of new functionalities, allowing to extend the number of design and implementation challenges that can be covered by the technology. This release is very mature and complete, and will make the position of Java on the server side more solid than ever.
Since the technology is getting more and more complete, it is getting harder to come with missing features. Here are few ideas which can be used in next releases:
- Support for specifying the minimum and maximum number of instances for a certain bean.
- Support for application life cycle classes which handle events like pre-start, post-start, pre-stop and post-stop.
- Enhance JMS in order to support features which are popular among messaging systems like message grouping and message ordering.
- Support for JAX-RS.
We ought to congratulate the team working on this spec, which has put a tremendous effort, achieving a high quality result.
About the Author
Paulo Moreira is a Portuguese freelance Software Engineer, currently working for Clearstream, in Luxembourg. Graduated from University of Minho with a Master Degree in Computer Science and Systems Engineering, he has been working with Java on the server side since 2001, in the telecom, retail, software and financial markets.




