Building a Scalable Enterprise Applications Using Asynchronous IO and SEDA Model
This article presents one solution to overcome the scalability issues related to the enterprise applications that must support a mix of fast and long running business processes, or with great or small throughput.
This article presents one solution to overcome the scalability issues related to the enterprise applications that must support a mix of fast and long running business processes, or with great or small throughput.
Let's define a simple, sample scenario that would simulate this situation. We have a front end web application that receives requests through HTTP and routes them to different web service endpoints. One of the platforms that is queried from one of the web service end points responds very slow. As a consequence, we would have an overall low throughput over time. This is happening as the slow responding service keeps a worker thread from the web server thread pool busy, preventing other requests to be served accordingly to agreed SLAs.
There is a solution for this, which, though is not standardized yet, is implemented in a form or another in almost all the servlet containers: Jetty, Apache Jakarta Tomcat, and Weblogic. It is about asynchronous IO.
The key architecture components used in the solution proposed here are:
- asynchronous IO in servlet containers
- Staged event-driven architecture(SEDA) model
Asynchronous IO in Servlet Containers
Servlet containers became a good choice to implement high scalable applications upon the introduction of the java nio library -- which allowed the transition from thread per connection to thread per request.
Shortly this was proved not to be enough and the problems occurred when implementing Reverse Ajax-based applications. There is no mechanism currently present in servlet API that would allow for asynchronous delivery of data to the client. Currently Reverse Ajax is implemented in three modes:
- polling
- piggy back
- Comet
Current Comet-based implementations keep an open channel with the client and send data back based on some events. But this breaks the thread per request model as for every client - at least a worker thread on the server must be allocated.
Two solutions are currently implemented in the servlet containers:
- asynchronous IO (Apache Tomcat, Bea Weblogic) -- which allows a servlet to process data asynchronously.
- continuations (Jetty) -- an interesting feature introduced in Jetty 6, which allows the suspending of the current request and free the worker thread.
All the implementation have advantages and disadvantages, and the best implementation would be a combination from all of these.
My example is based on the implementation of the Apache Jakarta Tomcat, called CometProcessor. This implementation decouples the request and response from the worker thread, thus allowing it to complete the response at a later time.
Staged event-driven architecture (SEDA) model
SEDA model is an architecture style proposed by Matt Welsh, David Culler and Eric Brewer from Berkley University. SEDA architecture is designed to enable high concurrency, load conditioning, and ease engineering for Internet services. SEDA decomposes an application into a network of stages separated by dynamic resource controllers to allow applications to adjust dynamically to changing load.
Below you can see a SEDA based HTTP server.
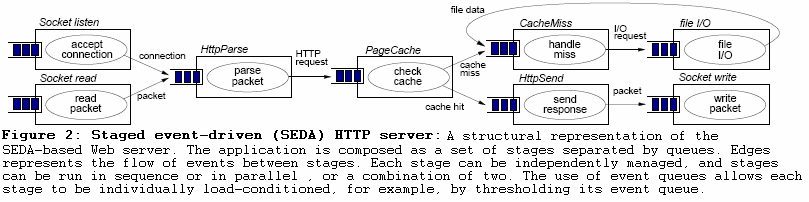
More about this architecture can be found in this paper: SEDA: An Architecture for Well-Conditioned, Scalable Internet Services.
Let's see how our simplified scenario can be mapped on this SEDA architecture.

The SEDA-based application would consist of seven stages. When a request of a specific type arrives, it would be routed to the right queue. Its corresponding stage would process the message and then put the response in the response queue. Finally the data will be sent back to the client. This way we would overcome the scalability problem that occurs when requests that are to be routed to the slow response service would block the other requests from being processed.
Let's see how we can implement this architecture using Mule.
Mule is an open source Enterprise Message Bus (ESB) whose model concept is based on SEDA model. Mule supports other message models as well, but SEDA model is the default. In this mode, Mule is treating each component as a stage, with its own thread pool and work queue.
The key components in the SEDA model - Incoming Event Queue, Admission Controller, Dynamically sized Thread Pool, Event Handler, and Resource Controller - are mapped to Mule service components.
With Mule, the Incoming Event Queue is provided as an inbound router or endpoint, and the Event Handler is the component itself. Thus we're short of an Admission Controller, Resource Controller and a Dynamically sized Thread Pool.
The Admission Controller is associated with the Incoming Event Endpoint of the SEDA stage, or component in Mule lingo. The most straightforward way of implementing this, is as an Inbound Router, which "can be used to control how and which events are received by a component subscribing on a channel".
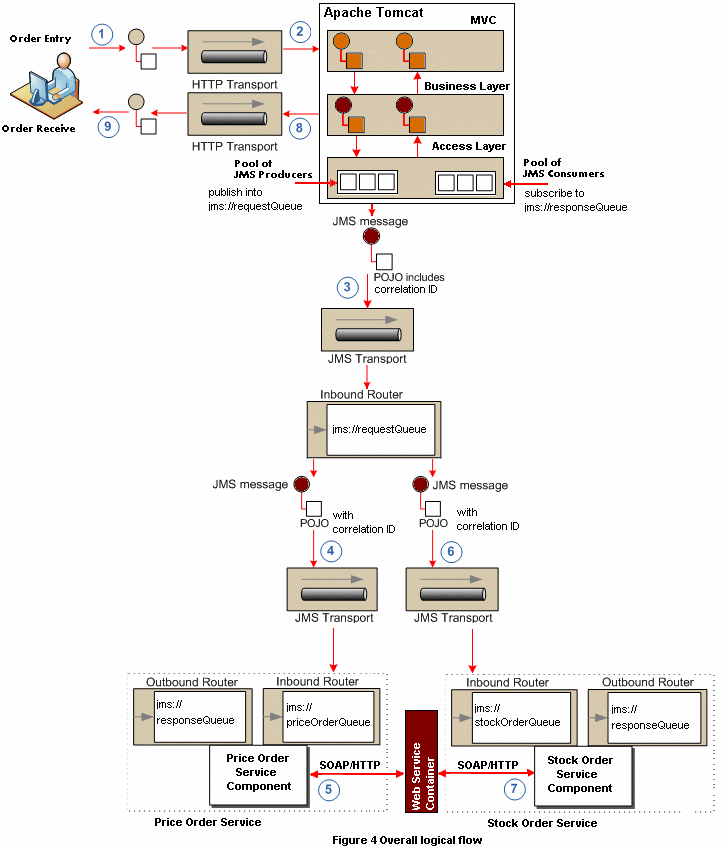
The logical flow for our scenario, mapped to the Mule model is presented in diagram below. The steps illustrated in it are as follows:
- The client places a order by a HTTP request.
-
The request is handled by an HTTP server, in our case Apache Jakarta Tomcat. Based on the parameters provided in the HTTP request, the front-end application assembles a request object. In our scenario we have two object types, PriceOrderRequest and StockOrderRequest. A correlation ID is generated for every request, and is mapped to the http response object associated to the request. We will see later how this will be used to match the response coming from Mule container to the original client request. From now on, the request object will contain this correlation ID and will be propagated through all layers in the front end application and also across the Mule components. The request order, whether it's a PriceOrderRequest or a StockOrderRequest, will be send to the access layer. In the access layer a pool of JMS Producers are ready to be used to enqueue the message in request queue. Now the request order will be handled by Mule components. The worker thread allocated by the web server to serve our HTTP request is now free to serve other requests, it does not have to wait until our business process completes.
-
Our request order is now in the jms queue whose address is jms://requestQueue. Processing moves now into Mule.
-
Based on the object type, the orders will be routed to different queues. In our case we have a PriceOrderRequest, so the message will be routed to the jms://priceOrderQueue.
-
A SOAP request will be made to the web service container using Apache CXF. The response will be send to the jms://responseQueue.
-
The same scenario as in step 4 applies in the case of StockOrderRequest.
-
The same scenario as in step 5 applies.
-
The pool of JMS Consumers listen to the jms://responseQueue. This queue contains response messages of the business requests. This messages contain the correlation ID metadata generated in step 2, that would allow us to identify the originator of the request.
-
Once the http response object is identified, we can now send the response back to the client.
The Mule configuration for this flow is presented below.
<jms:activemq-connector name="jmsConnector" brokerURL="tcp://localhost:61616"/>
<model name="Sample">
<service name="Order Service" >
<inbound>
<jms:inbound-endpoint queue="requestQueue"/>
</inbound>
<component class="org.mule.example.Logger"/>
<outbound>
<filtering-router>
<jms:outbound-endpoint queue="priceOrderQueue" />
<payload-type-filter expectedType="org.mule.model.PriceOrderRequest"/>
</filtering-router>
<filtering-router>
<jms:outbound-endpoint queue="stockOrderQueue" />
<payload-type-filter expectedType="org.mule.model.StockOrderRequest" />
</filtering-router>
</outbound>
</service>
<service name="stockService">
<inbound>
<jms:inbound-endpoint queue="stockOrderQueue" transformer-refs="JMSToObject
StockOrderRequestToServiceRequest" />
</inbound>
<outbound>
<chaining-router>
<cxf:outbound-endpoint
address="http://localhost:8080/axis2/services/getStock"
clientClass="org.axis2.service.stock.GetStock_Service"
wsdlPort="getStockHttpSoap12Endpoint"
wsdlLocation="classpath:/Stock.wsdl"
operation="getStock" />
<jms:outbound-endpoint queue="responseQueue"
transformer-refs="ServiceResponseToStockOrderResponse ObjectToJMS"/>
</chaining-router>
</outbound>
<default-service-exception-strategy>
<jms:outbound-endpoint queue="responseQueue"
transformer-refs="ExceptionToResponse ObjectToJMS"/>
</default-service-exception-strategy>
</service>
<service name="priceService">
<inbound>
<jms:inbound-endpoint queue="priceOrderQueue"
transformer-refs="JMSToObject PriceOrderRequestToServiceRequest"/>
</inbound>
<outbound>
<chaining-router>
<cxf:outbound-endpoint
address="http://localhost:8080/axis2/services/getPrice"
clientClass="org.axis2.service.price.GetPrice_Service"
wsdlPort="getPriceHttpSoap12Endpoint"
wsdlLocation="classpath:/Price.wsdl"
operation="getPrice" />
<jms:outbound-endpoint queue="responseQueue"
transformer-refs="ServiceResponseToPriceOrderResponse ObjectToJMS"/>
</chaining-router>
</outbound>
<default-service-exception-strategy>
A challenging problem with this event driven architecture model is to correlate the request with the response. One a request is made, a business object is created and transported as payload of a jms object message through multiple jms queues in the Mule Space. This message is routed from one queue to another, is used as input to a web service request etc.
The key information that allows us to keep track of a message is the CORRELATION ID from jms specifications. This can be set using message.setJMSCorrelationID. However if you publish a message in a jms queue with this property set, Mule seems to override this information and creates a new CORRELATION ID for messages that will be propagated through the flow. Fortunately there is an internal Mule message property called MULE_CORRELATION_ID. If Mule finds a message with this property set, it will propagate it across all the components in the flow, and also if no CORRELATION ID is set, then it will use the value of MULE_CORRELATION_ID property for the CORRELATION ID as well.
/* set the MULE_CORRELATION_ID property before sending the message to the queue*/
conn=getConnection();
session=conn.createSession(false, Session.AUTO_ACKNOWLEDGE);
producer= session.createProducer(getDestination(Constants.JMS_DESTINATION_REQUEST_QUEUE));
jmsMessage=session.createObjectMessage();
jmsMessage.setObject(request);
jmsMessage.setStringProperty(Constants.PROPS_MULE_CORRELATION_ID, request.getCorrelationID());
producer.send(jmsMessage);
So a unique CORRELATION ID must be generated for every request before the corresponding business objects are sent to the Mule entry point that is a jms queue.
One way this can be done is to generate a UUID that will be used as the CORRELATION ID and also map this UUID to the HttpServletResponse objects wrapped into the CometEvent objects provided in the event(CometEvent event) method of the CometProcessor interface.
/*
* generate the UUID for the CORRELATION ID and map to the HttpServletResponse
*/
public class IdentityCreator extends MethodInterceptorAspect{
protected void beforeInvoke(MethodInvocation method){
Object[] args=method.getArguments();
HttpServletRequest httpRequest=((CometEvent)args[0]).getHttpServletRequest();
String uuid=UuidFactory.getUuid();
httpRequest.setAttribute(Constants.PROPS_MULE_CORRELATION_ID, uuid);
HttpResponseManager.getInstance().saveResponse(uuid, ((CometEvent)args[0]).getHttpServletResponse());
}
protected void afterInvoke(MethodInvocation method){
return;
}
@Override
public void afterExceptionInvoke(MethodInvocation method) throws Throwable {
Object[] args=method.getArguments();
HttpServletRequest httpRequest=((CometEvent)args[0]).getHttpServletRequest();
String uuid=(String)httpRequest.getAttribute(Constants.PROPS_MULE_CORRELATION_ID);
if (uuid!=null) HttpResponseManager.getInstance().removeResponse(uuid);
}
}
When the response message comes back all we have to do is to get the CORRELATION ID value from the jms message properties, find the corresponding HttpServletResponse object and then send the response back to the client.
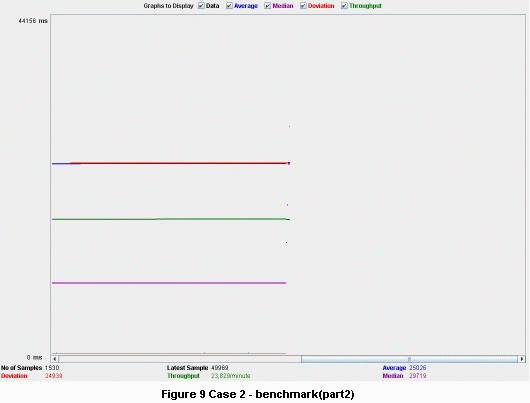
Benchmarks
Some benchmarks would give us a clear view of the advantages of this architecture. Using Apache JMeter, one test for each of the cases was performed, one for the architecture using asynchronous servlet and SEDA model, one for the other architecture without that model. The tests were run for about one hour, with 10 threads/sec, alternating the two types of requests. For these tests we have allocated a total number of six worker threads. For the case without scalability enhancement, all six threads were allocated for the thread pool of the Tomcat.
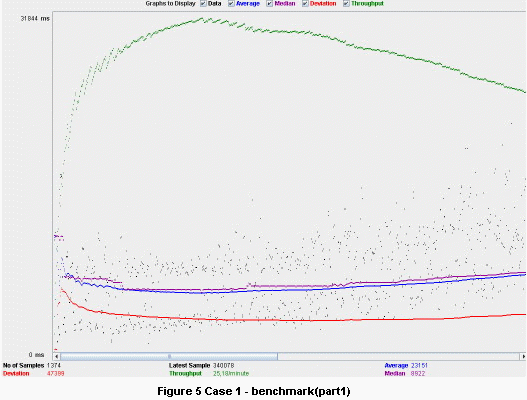
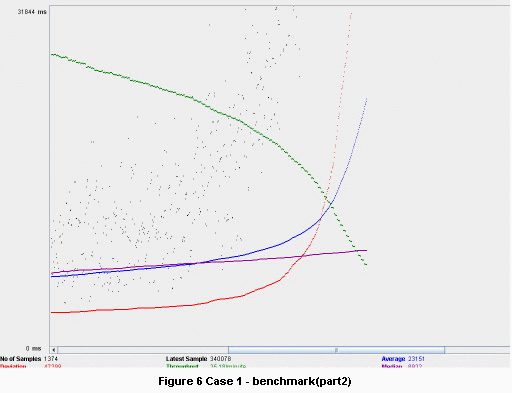
It can be seen very clearly how the throughput (green line) dropped to about 23 requests/minute.
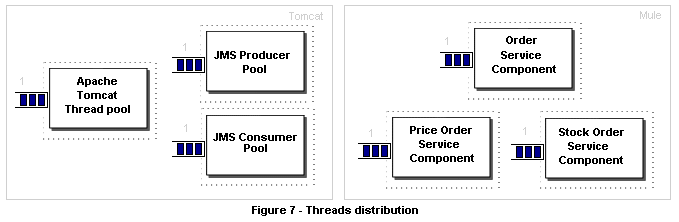
Now let's distribute the six threads among the components in our architecture (fig. 7). Every component was allocated one single thread.
For Jakarta Tomcat the lines below are required to be changed in the server.xml configuration file:
<Executor name="tomcatThreadPool" namePrefix="catalina-exec-"
maxThreads="1" minSpareThreads="0"/>
In case of Mule, for every service component the following line should be added in the service tag of the mule configuration file:
<component-threading-profile maxThreadsActive="1" maxThreadsIdle="0" poolExhaustedAction="RUN" maxBufferSize="20" threadWaitTimeout="300"/>
The benchmarks for the asynchronous and SEDA model architecture can be seen below. The throughput remain constant at a value of ~23 requests/minute.
If we have run the performance tests for more than 1 hour the throughput in the first case would continue to drop, but in the second case it would remain at the same value.