Inside db40
db4o, database for objects, is a true object database; it manipulates objects in such a fashion that those objects retain their nature throughout their lifetimes - in or out of the database. Object content, structure, and relationships are preserved, regardless of class complexity.
db4o - database for objects - is a true object database; it manipulates objects in such a fashion that those objects retain their nature throughout their lifetimes - in or out of the database. Object content, structure, and relationships are preserved, regardless of class complexity.
More precisely, db4o is a database engine, available as a single .jar file that you include in your database application's classpath (for Java, at least.) So, db4o runs in the same process space as your application and is called directly; it does not employ drivers in the sense of ODBC or JDBC. Versions of db4o exist for Java, .NET, and Mono; and all are functionally equivalent to one another. (In fact, a db4o created with a .NET language can be accessed by Java, and vice versa.)
db4o is open source. Executable, source, and documentation can be downloaded from www.db4objects.com. Extensive examples, as well as an active user community, can also be found at the website.
One of db4o's most attractive features is its remarkable balance of simplicity and power. On the one hand, its API is so easily mastered and readily grasped that even a neophyte can create a full-fledged database application in a single sitting. On the other hand, that same API provides lower-level calls into the database engine that admit hardcore developers into the engine's plumbing in order to tweak and tune db4o's equipment for optimum performance.
db4o's characteristics are best illustrated -- rather than merely discussed -- so we will take the approach of demonstrating db4o through example. Throughout this article, however, keep in mind that we are showing only a portion of db4o's features. Interested readers will find that time spent investigating the db4o documentation in discovery of this database engine's complete abilities is time well spent.
db4o Fundamentals
Let us begin with db4o as any newcomer would: we have defined classes, and we want to persist objects of those classes. Our hypothetical classes model a system that tracks tests performed for an equally hypothetical QA project. Our system consists of two classes. The first is TestSuite:
public class TestSuite {
private String name; // Test Suite name
private String description;
private String configuration;
private char overallScore;
private ArrayList <TestCase> cases;
private long dateExec;
... <remainder of TestSuite definition> ...
}
A TestSuite is primarily a container for TestCases, (a test case being a single executable test - related test cases are gathered into a suite). A TestSuite carries additional, global data members, and the purpose of each is relatively obvious: configuration records the specifics of the system being tested; overallScore is a summary score ('P' for pass, 'F' for fail, 'B' for blocked, etc.) for the entire suite; and dateExec is a millisecond field that identifies the date and time that the test suite was executed. The cases ArrayList carries the individual cases, modeled by the TestCase class:
public class TestCase {
private String name;
private String comment;
private char status;
private long duration;
private float result;
... <remainder of TestCase definition> ...
}
Each test case has a name, a free-form comment field, a status (pass or fail), a duration, and a result (for associating arbitrary data with the test - throughput in bytes-per-second, for example).
Because our focus is on the use of db4o, we don't want to get bogged down in describing the detailed uses of these classes. Let us simply say that we have executed all the test cases of a particular test suite, stored the results in a TestSuite object (along with the associated TestCases in the cases ArrayList), and we want to persist that object. That is, we want to create a database, open it, store the TestSuite object (which we will name testsuite), and close the database. What could be easier?
// Create the database
new File("testsuites.YAP").delete();
ObjectContainer db = Db4o.openFile("testsuites.YAP");
// Store the TestSuite object
db.set(testsuite);
// Close the database
db.close();
That's it. Dust your hands off; you're done. (Of course, to keep things simple, we left out the details of instantiating the TestSuite object and its component TestCases. )
Stop for a moment and reflect upon what is happening in the above code. In particular, consider what is happening that you don't see - things that db4o did without having to be told.
First, we didn't have to tell db4o anything about the structure of the TestSuite class; db4o discovered it without our help. Using Java's reflection capabilities, db4o determined the class of testsuite, and spidered the class's wiring to deduce the object's members and constituent data.
Second, we did not have to advise db4o concerning the cases ArrayList. Not only did we not have to tell db4o about the size of the ArrayList, we didn't have to tell db4o about its contents. Just as db4o discovers all it needs to new about TestSuite objects, it will discover all it needs to know about TestCase objects (within the ArrayList).
The result is that, if we regard testsuite as the 'root' object of an arbitrarily large and complex object tree, db4o found and stored the whole tree without any assistance from us. So, storing the base object testsuite also stored the cases ArrayList. This is, by the way, referred to as 'persistence by reachability', and you can configure how far db4o 'reaches' down the object tree as it determines what is to be persisted. That distance is known in db4o parlance as "update depth," and it's default value is infinite ... which means that db4o's persistence limitation is set by available memory more than anything else. (So, if we had only wanted to store the TestSuite itself, we could have set the update depth to 1.)
Finally, we did not have to request that db4o guard our call to the set() method with a transaction. Any call that modifies an ObjectContainer (the db4o object that models the database) automatically starts a transaction, unless a transaction is already active. Furthermore, the call to close() terminates the transaction, so the above code is equivalent to:
db.startTransaction(); db.set(testsuite); db.commitTransaction(); db.close();
where startTransaction() and commitTransaction() are methods we made up to illustrate our point. db4o does have explicit calls to commit or abort a transaction, but we excluded those from the original code to make the simplicity apparent. db4o's invisible transactions ensure that the database is always in a consistent state; once a commit() has executed, the integrity of the database is guaranteed even should a catastrophic system failure occur.
Querying I - QBE
With objects stored in the database, the next operations we will certainly want to perform are querying and retrieval. db4o provides three querying APIs: one simple, one elegant, and one complex. Each has its strengths and each is applicable to different query situations. From db4o's perspective, which API you chose is irrelevant: all are compatible.
We begin with the simple API: query by example (QBE).
Employing QBE is startlingly easy: you construct a 'template' object of your query target, and pass that to the ObjectContainer's query() method. In essence, you are telling db4o to 'go get all the objects that look like this one.' (This is very similar to the JavaSpaces query API; see below for specifics on handling primitives, which db4o handles differently than JavaSpaces. Also note that JavaSpace Entry objects are supposed to use public fields, where db4o has no such requirement.)
Suppose one of our test suites is named "Network Throughput," and we want to retrieve all executions of this test so that we can determine the percentage of test failures (based on the TestSuite's overallScore). Using QBE, the code for this is as follows:
// Open the database
ObjectContainer db = Db4o.openFile("testsuites.YAP");
// Instantiate the template object, filling in
// only the name field
testTemplate = new TestSuite("Network Throughput");
// Execute the query
ObjectSet result = db.get(testTemplate);
fails = 0.0f;
total = 0.0f;
// Step through results,
while(result.hasNext())
{
testsuite = (TestSuite)result.next();
if(testsuite.getOverallScore()=='F')
fails += 1.0f;
total += 1.0f;
}
if(total == 0.0f)
System.out.println("No tests of that type found.");
else
{
System.out.println("Percent failed: " + (fails/total * 100.0f) + "%");
System.out.println("Total executed: " + total);
}
db.close();
In the above code, testTemplate is the QBE template object. Note that it only its name field holds an actual value; all other object members are either null or zero. Null or zero fields do not participate in QBE queries; hence, the call to db.get() returns all TestSuite objects in the database whose name field matches "Network Throughput". The matching TestSuite objects are returned in the result ObjectSet. The code iterates through result, retrieving the objects and calculating the results to be displayed.
QBE's obvious advantage is its simplicity. There is no separate query language to master. In addition, QBE is typesafe: you cannot create a query analogous to the SQL code
SELECT TestSuite.overallScore FROM TestSuite WHERE TestSuite.name = 200.0
Put another way, since the query is crafted in Java code, the compiler won't let you put a floating-point value into a string field; or vice-versa.
QBE's real disadvantage is that it can only execute "equals to" queries. In addition, QBE uses the null value to identify string or object reference members that do not participate in the query, and the value zero to indicate non-participating numeric fields. So, for example, I could not contrive a QBE query to fetch all TestCase objects whose result field equals 0.0f.
A more capable query mechanism is required for more elaborate queries. And db4o has just the thing.
Querying II - Native Queries
db4o's Native Query system is arguably the most flexible query mechanism imaginable. Rather than building queries with a database query language, you construct a Native Queries with "plain old Java." Native Queries wave two wands to accomplish this magic: one a class, Predicate; the other an interface, QueryComparator. The class includes an overrideable callback method that specifies how objects are chosen from the database (the body of the query, if you will). The interface declares a method that designates the sort order of the results.
As an example, suppose we wanted to locate all the test suites that were executed in a given week, that had an overall score of "failed", but for which more than half of the associated test cases were scored as "passed". This is not a simple "equals to" query, so it could not be crafted in QBE.
However, db4o's Native Queries makes the query straightforward. First, we extend db4o's Predicate class:
// Predicate class sub-class for native query example
public class NativeQueryQuery extends Predicate<TestSuite>
{
ObjectContainer db;
private long startdate;
private long enddate;
// Constructor to acquire the ObjectContainer and the
// date range locally
public NativeQueryQuery(ObjectContainer _db,
long _start, long _end)
{
db = _db;
startdate = _start;
enddate = _end;
}
// This is the actual query body
public boolean match(TestSuite testsuite)
{
float passed;
float total;
TestCase testcase;
// See if the testsuite is in date range
if(testsuite.getDateExec()<startdate ||
testsuite.getDateExec()>enddate) return false;
// Reject if no test cases
if(testsuite.getNumberOfCases()==0)
return false;
// Check that more than 50% of the cases pass
passed = 0.0f;
total = 0.0f;
for(int i=0; i<testsuite.getNumberOfCases(); i++)
{
testcase = testsuite.getTestCase(i);
if(testcase.getStatus()=='P')
passed+=1.0f;
total+=1.0f;
}
if((passed/total)<.5) return false;
return true;
}
}
Notice the use of Java's generic syntax in the class definition. This tells db4o to fetch only TestSuite objects. When the query is executed, TestSuite objects are passed to the match() method (the callback method we referred to), which returns true for any object that meets the query criteria, false otherwise.
The code in the match() method first determines if the candidate object is within the 1-week range. If so, the code cycles through the member test case objects, calculating the total number of passed cases. If the result is less than 50%, the suite is rejected. Otherwise, it passes.
We can actually perform the query with the following code:
. . .
TestSuite testsuite;
NativeQueryQuery nqqClass;
Date now;
// Open the database
ObjectContainer db = Db4o.openFile("testsuites.YAP");
// Instantiate a NativeQueryQuery object,
// setting the start and end dates for
// any test in the past week
// 604800000 = milliseconds in a week
now = new Date();
nqqClass = new NativeQueryQuery(db,
now.getTime()-604800000L,
now.getTime());
// Execute the query and display the
// results
System.out.println("Results:");
ObjectSet results = db.query(nqqClass);
if(results.isEmpty())
System.out.println(" NOTHING TO DISPLAY");
while(results.hasNext())
{
testsuite = (TestSuite)(results.next());
System.out.println(testsuite.toString());
}
db.close();
. . .
Think of Native Queries like this: the objects of the target class are pulled one by one from the database, and passed to the match() method. Only those for which match() returns true are placed in the results ObjectSet. It is not too far off the mark to say that if you know how to write Java code, then you know how to write a Native Query.
What about sorting? If we want to arrange the results in ascending date order, we implement the QueryComparator interface as follows:
public class NativeQuerySort implements QueryComparator<TestSuite>{
public int compare(TestSuite t1, TestSuite t2)
{
if (t1.getDateExec() < t2.getDateExec()) return -1;
if (t1.getDateExec() > t2.getDateExec()) return 1;
return 0;
}
}
The function of the compare() method is obvious. Objects that succeed in the query are passed to the compare() method in pairs. The method returns a value less than, equal to, or greater than 0 if the first object is to be sorted before, equal to, or after the second, respectively. To actually impose the sorting on the results, we instantiate the NativeQuerySort object and modify the call to query() like so:
. . .
// Instantiate the sort class
nqsClass = new NativeQuerySort();
. . .
ObjectSet results = db.query(nqqClass, nqsClass);
. . .
The rest of the code remains the same.
Skeptical readers might complain that a Native Query is simply a programmatic trick -- that it is no faster than code that simply fetches all the TestSuite objects and excludes those not meeting the criteria.
Well, not quite. Native Queries can be optimized. All you have to do is place a pair of jar files -- db4o-xxx-nqopt.jar (where xxx is the db4o version) and bloat.jar -- in the CLASSPATH. At query execution time, code in these libraries will optimize constructs (in the match() method) such as primitive comparisons, arithmetic and boolean expressions, simple object member access, and more. The list of supported optimizations is constantly lengthening, as db4o engineers extend its range.
Querying III - S.O.D.A.
One of db4o's unique strengths is how its APIs are layered. A developer can choose either to control db4o from a high level -- granting the database engine considerable latitude in how it decides to carry out its operations -- or the developer can access db4o in a more direct fashion. The latter choice places a greater burden on the programmer, who must direct the engine's inner workings more carefully. But the reward is a faster and more capable database.
db4o's S.O.D.A. (Simple Object Data Access) query mechanism is a perfect example of this API layering. S.O.D.A. is actually db4o's internal query system -- QBE and Native Queries are translated into S.O.D.A. However, applications can call S.O.D.A. directly.
Suppose we wanted to locate all of the "Network Throughput" test suites that had at least one test case whose result -- which we will take to be a measurement of bytes per second -- was less than a specified value (say, 100). A S.O.D.A. query for such a request would look like this.
. . .
TestSuite testsuite;
// Open the database
ObjectContainer db = Db4o.openFile("testsuites.YAP");
// Construct the query
Query query = db.query();
query.constrain(TestSuite.class);
Constraint nameConst = query.descend("name").
constrain("Network Throughput");
query.descend("cases").descend("result").
constrain(100.0f).smaller().and(nameConst);
System.out.println("Results:");
// Execute the query
ObjectSet result = query.execute();
if(result.isEmpty())
System.out.println("NOTHING TO DISPLAY");
while(result.hasNext())
{
testsuite = (TestSuite)(result.next());
System.out.println(testsuite.toString());
}
db.close();
. . .
This rather mysterious bit of code becomes less mysterious with the help of the diagram shown in illustration 1. The code builds what amounts to a query graph that guides the underlying engine. The descend() method creates a branch on this graph that steps downward into the object structure. Each descent builds a node in the tree, to which we can attach a constraint (using the constrain() method). In SQL parlance, constraints specify the "WHERE" portion of the query. Multiple constraints can be joined with the assistance of conjunction (and) or disjunction (or) methods. We've used and() in the above query to connect the constraints.
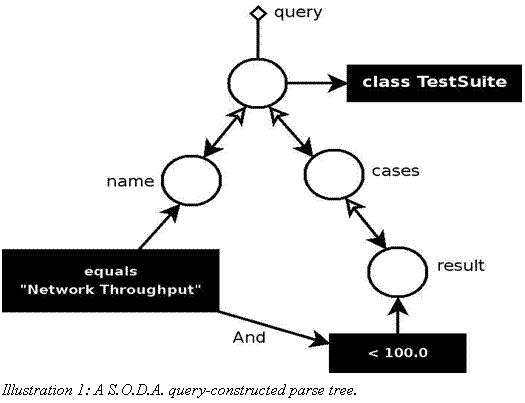
As with the other query methods, the results are returned in an ObjectSet, through which we iterate to retrieve the fetched objects.
Note that, while S.O.D.A. is a low-level access method, it is not without intelligent, default behavior. The bit of code that accesses the result field of the cases member is simply
query.descend("cases").descend("result"). ...
We did not have to tell S.O.D.A. that " cases" was a collection. So, when the query executes, it invisibly examines the results field of all items in the cases ArrayList, and correctly returns test suites for which any test case meets the search criteria.
Tuning db4o
We have shown db4o's basic operations (with the exception of delete, which is trivial, and which will be mentioned below). But, as we have repeated throughout this article, db4o exposes a hierarchy of APIs that allow the developer to select the level of control the application has over the database engine. Put another way, if all you want to do is put objects into and retrieve objects from the database, you've seen all you need to know. However, if your application's needs are beyond adding, updating, retrieving, and deleting, it's likely there's a db4o feature to solve your problem.
db4o's ObjectContainer actually exposes two APIs. The first is very simple, consisting of ten methods. These methods handle opening and closing the database; adding, updating, querying, and deleting objects; and committing or aborting transactions. In short, this API gives you virtually all the functionality you need to manipulate the database. However, one method in this API -- ext() -- is a kind of doorway into an "extended" ObjectContainer. The extended ObjectContainer exposes more methods for deeper control of db4o's internals. You can, for example, retrieve and alter the database's configuration context, with which you modify the engine's behavior.
For example, suppose you have fetched a TestSuite object from the database, discovered that the data in the object is erroneous, and determined that the object should be deleted. Furthermore, you conclude that you must delete not only the TestSuite object, but all its associated TestCase objects (in the cases ArrayList).
You could step tediously through the ArrayList, deleting each TestCase object one-by-one, then delete the TestSuite object itself. A better solution, though, would be to enable db4o's "cascaded delete" feature for the TestSuite class. With cascaded delete active, removing an object of the target class also removes all referenced objects. So, assuming that the database has been opened and its ObjectContainer is db, the following code does the trick:
. . .
// Fetch the database's configuration context
Configuration config = db.ext().configure();
// Get the ObjectClass for TestSuite
ObjectClass oc = config.objectClass("testsuites.TestSuite");
// Turn on cascaded delete
oc.cascadeOnDelete(true);
...
...
db.delete(ts1);
. . .
In the above code, we instantiate an ObjectClass, which gives us access to db4o's internal representation of TestSuite objects. We turn on the cascadeOnDelete flag for TestSuite objects, so that when db.delete(ts1) executes, not only is the ts1 object deleted, but all of the TestCase objects referenced by ts1 are deleted too. (Cascaded deletes are, by default, turned off ... for obvious reasons.)
As another example, suppose you want to pre-allocate storage space for the database, so as to minimize head movement on the disk drive. (This is best done immediately after the hard drive has been de-fragmented, and on a newly-created database.) Again, assuming that the database is opened as ObjectContainer db:
// Fetch the database's configuration context Configuration config = db.ext().configure(); // Pre-allocate 200,000 bytes config.reserveStorageSpace(200000000L);
This listing fragment will pre-extend the database file to 200,000,000 bytes (a bit less than 200 megabytes). Assuming that the disk had been defragmented, the allocated sectors will be contiguous, significantly improving database access.
Advanced db4o
Suffice it to say, db4o packs enough into its moderate size (about 500K) that we could consume more bytes with our explanations than db4o does during its execution. Two features, however, are outstanding enough that they warrant mention.
db4o's object replication implements what amounts to an object oriented version of database synchronization. With replication enabled, you can make a copy of an object from one database into another in such a way that the copied object is invisibly tethered to its original. Alterations to either object -- the original or the copy -- are tracked so that, at a later time, the databases can be reunited and any differences between the objects resolved (i.e., the databases can be synchronized).
It works like this. Enable replication for a database, and any object created in that database is tagged with a unique universal identifier (UUID) as well as a transaction counter. When you 'replicate' an object from that original database into another database, the replicated object carries the same UUID and transaction counter as its originating object. The replicated database can now be carried away from the original. Changing the replicated object's contents will cause the object's transaction counter to be modified. So, when the databases are re-connected, db4o's built-in synchronization handling can unerringly match object to object (using UUIDs), and determine whether one or the other has been altered. db4o will even track the time of each object's last alteration, so that user-written conflict-resolution code can determine which object is the most up-to-date.
In operation, db4o's replication handling is quite similar to Native Queries. Recall that, when we implemented a Native Query class, we defined a match() method whose code determined which objects met (or failed) the search criteria. With replication, we define a ReplicationProcess object, to which we pass our conflict handling object. The Java code looks like this:
. . .
ReplicationProcess replication = db1.ext().
replicationBegin(db2, new ReplicationConflictHandler()
{ public Object resolveConflict(
ReplicationProcess rprocess, Object a, Object b)
{
. . .
...
return winning_object;
}
}
);
In the above code. Object a is the object from database db1, and Object b is from database db2. By default, replication is bi-directional. The replication process ensures that the winning object (returned by the resolveConflict() method) is stored in both databases. So, when replication is complete, the replicated objects in both databases are synchronized.
Finally, one of db4o's most powerful features is its near effortless toleration of class schema evolution. Suppose that, after adding several hundred TestSuite objects to our database, we determined that the class had to be modified. Let's say that we have been told that our system must track which QA engineer executed each TestSuite, so we have to add the field:
private int engineerID; to our definition of the TestSuite class.
We are now faced with two related problems. The first is not so bad: the TestSuite objects already in the database represent tests for which we did not record an engineer's ID, so we'll have to assign a dummy value to those objects' engineerID field; a value which indicates "no engineer's ID recorded." The second problem is tougher: we have to somehow migrate existing TestSuite objects to the "new" class structure. We have to add an engineerID field to all those TestSuite objects already in the database. Short of copying the old database into an intermediate file, then recreating the database, what can we do?
Happily, with db4o, we really don't have to do much of anything. If we simply add the engineerID field to the TestSuite class (in our application code), make the required changes to the business logic to manipulate the new engineerID, we don't have to touch any of the db4o API calls. When db4o reads an "old" TestSuite object using the "new" TestSuite class schema, db4o will see that the engineerID field is missing, and politely set it to 0. If we recognize 0 as our "no engineer's ID recorded" value, we're all done with the migration. New TestSuite objects written to the database will include the new field. (In fact, rewriting an old TestSuite object on top of itself will cause db4o to invisibly add the new field.) So, by deploying an updated application that includes the new TestSuite definition, we can actually migrate from old to new TestSuite objects invisibly ... as the application runs.
A Database for All Seasons
Properly applied, db4o can become something akin to a database "Swiss Army knife". Its memory footprint is modest enough that its inclusion in a project does not consume vast resources. Also, the fact that a database occupies a single file on disk gives db4o applications a versatility that might, at first glance, not be recognized. Moving a database from place to place is simply a file copy; you needn't worry about the location of separate index files, data files, schema files, and so on. For quick deployment and zero-administration database applications, it's hard to beat.
In addition, as we've stated several times, db4o strikes the proper balance between simplicity and elegance. db4o's QBE is simultaneously so easy and so versatile, that it is often the only query API we've needed for a surprising array of applications. QBE is particularly attractive if you access database objects primarily through pointer navigation rather than querying. In such cases, QBE is usually sufficient to fetch the root object of an object network. You can then use db4o's activation capability to navigate down object references, much as you would do if the objects were entirely in memory.
But for those times when QBE is insufficient, Native Queries and S.O.D.A. are available, and they are accompanied by a host of features and low-level APIs. We have not shown db4o's encryption capabilities, its pluggable file I/O (which allows you to, for example, add read-after-write verification), its semaphores, its client/server modules, and other capabilities too numerous to list. Our concluding suggestion is simply this: when your next Java application needs a database, pay a visit to www.db4objects.com before you begin final coding. The visit will be worth it.






