Cocoon as a Web Framework
Art of Java Web Development covers several different Model 2 web frameworks. Cocoon is more than one type of framework. Cocoon automatically transforms documents based on the request context. It presents a new kind of application service, leveraging XML technologies to create web sites with unprecedented flexibility.
Introduction
My book Art of Java Web Development covers several different Model 2 web frameworks. One of the frameworks is Cocoon. Cocoon is more than one type of framework. It provides some of the same facilities as the other web frameworks, but Cocoon contains an entire additional personality: that of a publishing framework . Cocoon automatically transforms documents based on the request context. It presents a new kind of application service, leveraging XML technologies to create web sites with unprecedented flexibility. It also embodies another dimension of Model-View-Controller , where the framework handles all the view generation automatically.
Cocoon is also a very complicated framework. It relies on XML technologies such as XSLT (Extensible Stylesheet Transformation Language) and others. Because it does so much, there are myriad configuration and development issues. This article won't delve into the boring minutia of setting up Cocoon. It serves as an introduction to Cocoon in its guises as a web application framework. A working knowledge of XML technologies will help, but shouldn't be necessary.
Background
Stefano Mazzocchi founded the Cocoon project in 1999 as an open source Apache project. It started as a simple servlet for on-the-fly transformations of XML documents using XSL stylesheets. It was based on the memory intensive DOM (Document Object Model ) API, which loaded the entire document in memory to process it. This quickly became a limiting factor. To drive the transformations, the XSL stylesheet was either referenced or embedded inside the XML document. While convenient, it caused maintenance problems for dynamic web sites.
To solve these problems, Cocoon 2 entailed a complete re-write of the framework, incorporating the lessons learned from Cocoon version 1. Cocoon 2 changed from DOM to the much more memory and processing friendly SAX (the Simple API for XML Processing ) technique of parsing the XML documents. It also created the concept of a pipeline to determine the processing stages that a document must traverse, and included numerous performance and caching improvements. Legend has it that the time elapse between the two releases was partially due to the principle developer deciding to go back to college to complete his degree. Only in the open source world can this happen to a state-of-the-art piece of software!
For this article, I'm using Cocoon version 2.0.4. You can download Cocoon at http://xml.apache.org/cocoon/ . This site allows you to download either Cocoon 1 or 2, although Cocoon 1 is only provided for backwards compatibility.
Architecture
Cocoon's two parts, the publishing and web application frameworks, are related at the core level but may not seem so from the surface. It turns out that the web framework is another aspect of the publishing framework. For the purposes of architecture, I'll show them as distinct elements. First, I'll discuss the architecture of the publishing framework, then of the web framework.
Publishing Framework
A publishing framework is a tool that automates part of the generation of client specific documents from a common base. Figure 1 shows this architecture.
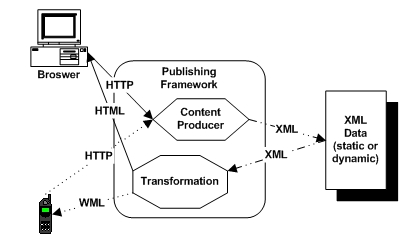
Figure 1 A publishing framework performs automatic transformations depending on the device making the request.
In this diagram, two separate client devices are making a request of the publishing framework, which is running as part of a web application. The browser requests the document. The publishing framework notices the user agent of the request (which is part of the HTTP header information) and the requested resource. Once it starts to return the resource, it applies an XSLT transformation to it and generates an HTML document suitable for the browser. A wireless device (like a cell phone) makes a request for the same resource from the same publishing framework. However, because the user agent is different, a different stylesheet transformation is applied and the cell phone receives a WML document.
The benefits of a publishing framework are twofold. First, for the developers of the content, they no longer have to worry about creating different types of content for different devices. The developers produce XML documents. Stylesheet designers create XSLT stylesheets for the various types of devices the application must support. This step is completely separate from the content generation step. The second benefit is the flexibility of the application. When a new device appears, the content designers don't have to change anything about the application. A new stylesheet is all that is required to support the new device.
The problems with this approach are also twofold. First, the transformation process is very resource intensive on the servlet engine. Parsing text and applying transformations in XML takes a great deal of processor resources . Memory management has gotten better with Cocoon moving to SAX instead of DOM, but it is still an issue. The other problem lies with the complexity of the XSLT stylesheets . It is an entirely new language for developers to learn, and it is not very readable or friendly. Currently, few tools do anything to ease the process of creating the stylesheets. For the time being, developers must create the stylesheets by hand. Good stylesheet developers are hard to find, so it limits the practically of wide use of publishing frameworks. However, tool support will come and the process will become much easier.
Pipelines
Cocoon 2 introduced the idea of a pipeline to handle a request. A pipeline is a series of steps for how to process a particular kind of content. Usually, a pipeline consists of several steps that specify the generation, transformation, and serialization of the SAX events that make up the generated content. This is shown in figure 2.
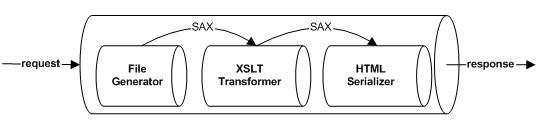
Figure 2 A pipeline is a series of steps that contributed to the transformation of one type of content to another.
As the request is processed, it moves from stage to stage in the pipeline. Each stage is responsible for a part of the generation or transformation of the content. Cocoon allows you to customize exactly what steps a particular type of content incurs. Between each stage of the pipeline, SAX events are fired so that you can further customize the processing of the content. In this example, a file is generated, passed to an XSLT transformation, then passed to a HTML serializer to produce the output file. The result is the automated transformation of an XML document into an HTML document.
Web Framework
As a web framework, Cocoon is also a publishing framework. You can see that you could configure Cocoon on a case by case basis to apply custom stylesheets to your content to produce HTML documents. If this were the extent of the web framework, you would spend most of your time getting the plumbing correct. In addition, you would have to write all the stylesheets yourself. Wouldn't it be better to create a set of stylesheets that always apply to web development content? That is what the designers of Cocoon have done. You can create Model 2 web applications using built-in classes and stylesheets relying on the existing transformers for most work and customizing them for special circumstances. The web framework aspect of Cocoon is shown in figure 3.
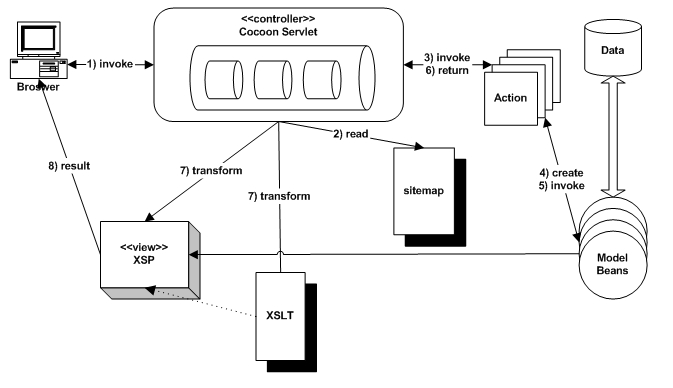
Figure 3 The Cocoon servlet already knows how to handle common Model 2 web application content.
For a Cocoon web application, the user makes a request to the Cocoon servlet . The servlet determines that it is a request for web application content via the sitemap and instantiates a matching action. In this case, the sitemap serves the same purpose as the Struts configuration document . The action references model beans, both boundary and entity, and performs work. The resulting information is packaged into a standard web collection and passed back to the Cocoon servlet. It then selects the appropriate user interface file and transformation from the sitemap and forwards the request to it. The transformation is applied and the response is sent back to the user. Cocoon has created the concept of XSP , or Extensible Server Pages . These pages are similar to JSP s but use a stricter XML syntax and some different constructs on the page themselves.
Key Concepts
To understand the web framework aspect of Cocoon, you must understand some of the publishing framework as well. To the end, I discuss some key concepts of the publishing framework, move to configuration and the sitemap, then cover web actions and XSP. This discussion assumes you know the basics of how XSL and XSLT transformations work.
Sitemap
The sitemap is an XML configuration document included with the web application. This document defines all the pipelines, generators, and other configuration information for a Cocoon application. It also maps URI's to resources. A complete sitemap for even a trivial application is too long to show here. The sitemap that comes with Cocoon that defines its samples is 1482 lines long! It contains a fair number of comments but there is still more content than comments. Even a simple sitemap can easily stretch to hundreds of lines. Fortunately, Cocoon documents the contents of the sitemap well. I will show the pertinent parts of the sitemap for the Schedule application in a later section.
The sitemap consists of two parts: components and pipelines, and pipelines are made up of components. The first part of the sitemap contains the component definitions, broken down into component types. The following sections highlight some important portions of the sitemap but are not an exhaustive treatment. The sitemap included with the samples is well documented as to the nature of each section in the sitemap.
Generator Configuration
Generators are components , thus they are defined within the sitemap. All pipeline s consist of at least two components: a generator, which produces the content, and a serializer, which is responsible for persisting the document and delivering it to the requesting client. Within a sitemap, each generator must have a unique name, and one generator is declared as the default, which acts if no specific generator is associated with a pipeline. A small portion of the components section in a sitemap appears in listing 1.
Listing 1. The components section of the sitemap defines components that are used in pipelines.
<map:generators default="file">
<map:generator label="content,data"
logger="sitemap.generator.file"
name="file"
pool-grow="4"
pool-max="32"
pool-min="8"
src="org.apache.cocoon.generation.FileGenerator"/>
<map:generator label="content,data"
logger="sitemap.generator.serverpages"
name="serverpages"
pool-grow="2"
pool-max="32"
pool-min="4"
src="org.apache.cocoon.generation.ServerPagesGenerator"/> In listing 1, #1 The 'label' attribute is optional (it relates to one of the later categories in the sitemap). The 'logger' attribute allows you to specify a different logging mechanism for each component. If the component doesn't specify a logger, it uses the default for the application. The 'pool' attributes are used by the component manager part of the framework to specify resource allocation. The 'src' attribute is poorly named ' it is not the source code but rather the fully qualified class name of the generator class.
Transformers
Transformers also appear in the component section. They sit in the pipeline between the generator and the serializer, and each pipeline can have as many transformers as needed. Some of the transformers have custom configuration information associated with them as child attributes. These custom components are declared in another file, Cocoon.xconf , which is the configuration file format for the Avalon meta-framework on which Cocoon is based. This file defines the components and specifies additional information (like configuration parameters) for them. Listing 2 shows a couple of transformer declarations in the sitemap file.
<map:transformers default="xslt">
<map:transformer logger="sitemap.transformer.xslt"
name="xslt"
pool-grow="2"
pool-max="32"
pool-min="8"
src="org.apache.cocoon.transformation.TraxTransformer">
<use-request-parameters>false</use-request-parameters>
<use-browser-capabilities-db>
false
</use-browser-capabilities-db>
<use-deli>false</use-deli>
</map:transformer>
<map:transformer logger="sitemap.transformer.log"
name="log"
pool-grow="2"
pool-max="16"
pool-min="2"
src="org.apache.cocoon.transformation.LogTransformer"/>Actions
Actions are executed during pipeline setup. Their purpose is to execute code necessary for the pipeline to execute. For example, the action might pull information from a database to populate the document consumed by the generator. Their execution may succeed or fail. If the action fails, the pipeline segment defined inside the action will not execute. Actions are the prime execution context in Cocoon. They are used in web application development much like the actions in Struts. Defining a pipeline with embedded actions provides most of the programmability for the way the pipeline execution proceeds. A couple of example action declarations appear in listing 3.
<map:action name="sunRise-login"
src="org.apache.cocoon.sunshine.sunrise.acting.LoginAction"/>
<map:action name="sunRise-logout"
src="org.apache.cocoon.sunshine.sunrise.acting.LogoutAction"/>Pipelines
The second part of the sitemap consists of the pipeline definitions. Pipelines specify how the processing of content is done. In most cases, pipelines consist of a generator, zero or more transformers, and a serializer. The invocation of a pipeline depends on a URI mapping either of a single document or by extension or wildcard, if you want a particular pipeline to apply to a variety of content. An example of several pipeline definitions appear in listing 4.
<map:match pattern="sample-*">
<map:generate src="docs/samples/sample-{1}.xml"/>
<map:transform src="stylesheets/simple-samples2html.xsl"/>
<map:serialize/>
</map:match>
<map:match pattern="news/slashdot.xml">
<map:generate src="https://slashdot.org/slashdot.xml"/>
<map:transform src="stylesheets/news/slashdot.xsl"/>
<map:serialize/>
</map:match>In listing 4, the pipeline matches the URI 'sample-*', meaning any URI that starts with 'sample-' followed by anything matches this pipeline. The generator is a document located at 'docs/samples/sample-{1}.xml'. The '{1}' token matches the part of the URI handled by the asterisk. For example, if the user requested the URI http://localhost:8080/cocoon/sample-foo', the pipeline generator would use the document 'docs/samples/sample-foo.xml' as the source for the pipeline. The transformation is the standard transformation for sample documents to HTML. Finally, the serializer is the default serializer (which generates the output of the transformation directly).
The second pipeline example utilizes a feature of the SlashDot web site, which returns the current front page news as an XML document. Cocoon uses a stylesheet defined in its examples to perform a transformation on the content to produce the page shown in figure 4.
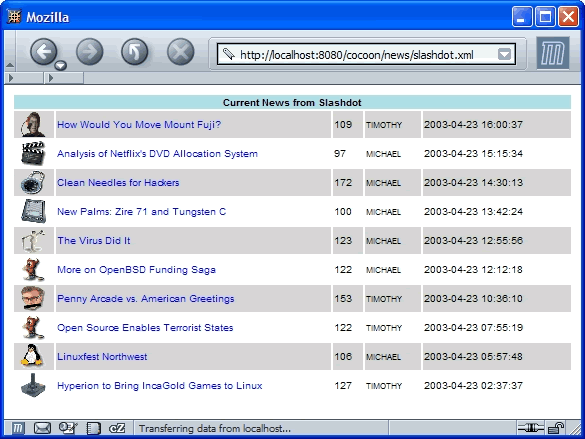
Figure 4 The Cocoon pipeline defines the Slashdot news site as an XML generator and applies a stylesheet to create an alternate view of the new.
Web Framework
The web framework in Cocoon is one aspect of the publishing framework. It encompasses two areas suited for web development. The first, actions, apply to any pipeline. The second, XSP, is particularly for web development.
Actions
Cocoon uses the concept of an action as an execution context, which is similar to Struts' actions. A pipeline invokes an action to perform some processing before the rest of the pipeline takes over. Actions are used as the active elements for pipelines in the publishing framework. They have use in the web framework side of Cocoon as controller proxies to perform work before forwarding to a view component. Actions are executed during pipeline setup . Therefore, the action itself has no effect on the pipeline once the processing has started. The action is used to set up conditions suitable for the pipeline to work, passing dynamic content over to the generator to process.
Actions are based on the Cocoon Action interface , which defines a single act() method. Cocoon also includes an AbstractAction class, which implements the interface and extends the AbstractLoggable class. This class provides access to the logger defined for this component via the getLogger() method. Actions return a java.util.Map object. The contents of this map are used in the pipeline as replaceable variables (like the ones shown in the pipeline example in listing 4). Any name/value pairs returned by the action become parameters. If a particular action does not need to supply any values, it should return an empty Hashmap (the AbstractAction has a constant defined for this purpose). If the action needs to indicate failure, it should return null.
XSP
XSP stands for eXtensible Server Pages . It is a Cocoon technology built on the ideas behind JSP. XSP is very similar to JSP with two exceptions. First, the pages are all XML pages, not necessarily HTML. Therefore, they can undergo the same kind of transformations as XML documents in the Cocoon publishing framework. Second, XSP pages are not tied to Java as the underlying language. An implementation exists in Cocoon for a JavaScript version of XSP. Listing 5 shows an example of a simple XSP page.
<xsp:page language="java">
<page>
<log:logger filename="xsp-sample.log" name="xsp-sample"/>
<log:debug>Processing the beginning of the page</log:debug>
<title>A Simple XSP Page</title>
<content>
<para>Hi there! I'm a simple dynamic page generated by XSP
(eXtensible Server Pages).</para>
<para>I was requested as the URI:
<b><xsp-request:get-uri as="xml"/></b></para>
<para>The following list was dynamically generated:</para>
<ul>
<xsp:logic>
<![CDATA[
for (int i=0; i<3; i++) {]]><![CDATA[
]]>
<li>
Item <xsp:expr>i</xsp:expr>
</li>
<![CDATA[
} ]]><![CDATA[
]]>
</xsp:logic>
</ul>
<xsp:element>
<xsp:param name="name">
<xsp:expr>"P".toLowerCase()</xsp:expr>
</xsp:param>
<xsp:attribute name="align">left</xsp:attribute>
<i>
This paragraph was dynamically generated by logic
embedded in the page
</i>
</xsp:element>
<para>
Request parameter "name" as XML:
<xsp-request:get-parameter as="xml"
default="Not provided" name="name"/>
</para>
<para>
Request parameter "name" as String:
<xsp-request:get-parameter
default="Not provided" name="name"/>
</para>
</page>
</xsp:page>While similar to a JSP, there are notable differences. First, notice that the tags used to delimit the paragraphs and other elements are not HTML, they are instead defined as XSP. Second, embedded code in XSP appears in a 'logic' tag. An unfortunate side effect of XSP pages adhering strictly to the XML standards is that the normal operators in Java for 'less than' and 'greater than' are illegal within tags. To use them (as in a 'for' loop), you must either escape them within a 'CDATA' block or use the XML friendly equivalent (for '<', use '<').
XSP pages have a transformer pre-defined by Cocoon. To create a web application in Cocoon, the developer defines a pipeline that includes one or more actions that place items in a standard web collection . Then, the pipeline forwards to an XSP document, which is picked up by the XSPGenerator and passed to the XSP-to-HTML transformer , which generates the output for the user. This sequence occurs in the Scheduling application in the next section.
Scheduling in Cocoon
In my book, Art of Java Web Development, I compare 6 different web application frameworks by creating the same application in each. This allows for an "apples-to-apples" comparison of sometimes wildly different frameworks.The application I create is a simple scheduling application. The first page of the application, as written in Cocoon, appears here. It takes advantage of two classes that do not appears here: Schedule, which is a simple entity representing a schedule record and ScheduleDb, a boundary class that reads and writes Schedule entites to the database.
The Scheduling application in Cocoon takes advantage of the web application framework. However, as you have seen, you can't use that framework without also using the publishing framework. For this example, I'm using pipelines, actions, and XSP pages. This project consists of sitemap definitions, the action class, and the XSP. The running Cocoon Scheduling application appears in figure 5.
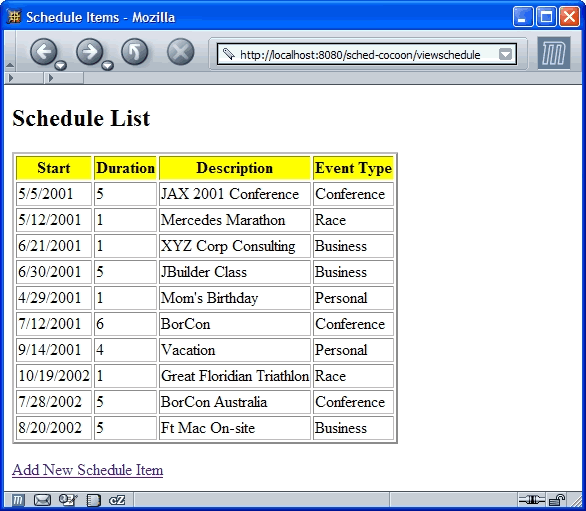
Figure 5 The Cocoon scheduling application uses custom actions and an XSP for generating the user interface.
Sitemap
The first step in a Cocoon project is the creation of the sitemap . More accurately, the first step is the modification of an existing sitemap (complex XML documents like this are never created from scratch, they are always 'borrowed' and modified). For this application, I register an action component and define the pipeline for the application. These declarations appear in separate sections of the sitemap but I've compressed them here to fit into a single listing. The sitemap elements required for this application appear in listing 6.
<map:actions>
<map:action name="view-schedule"
src="com.nealford.art.schedcocoon.action.ViewSchedule" />
</map:actions>
<!-- sections of sitemap omitted -->
<map:pipeline>
<map:match pattern="">
<map:redirect-to uri="home.html" />
</map:match>
<map:match pattern="viewschedule">
<map:act type="view-schedule">
<map:generate type="serverpages"
src="viewschedule.xsp" />
</map:act>
<map:serialize/>
</map:match>
<map:handle-errors>
<map:transform src="stylesheets/system/error2html.xsl"/>
<map:serialize status-code="500" />
</map:handle-errors>
</map:pipeline>In listing 6, the action definition registers the action in the next section as a component. Next, the pipeline creates three patterns to match (the "map:match" and "map:handle-errors" elements). The first pattern, which redirects to a home page, is a stop-gap for any unrecognized content to map to a 'home' page. The second pattern is the important one for this application. Any URI that maps to 'viewschedule' will go through this pipeline. It creates an instance of the custom action. If the action succeeds, it uses the XSP generator to point to the XSP for this page. The last mapping handles error conditions, taking the default XML error message from Cocoon and generating an HTML document. It is a good idea to include this mapping in every project because it makes the error messages while debugging much more readable.
Action
The action is similar to intent to an action in Struts or any other web framework that uses the command design pattern . The ViewSchedule action appears in listing 7.
package com.nealford.art.schedcocoon.action;
import java.util.HashMap;
import java.util.Map;
import com.nealford.art.schedcocoon.boundary.ScheduleDb;
import org.apache.avalon.framework.parameters.Parameters;
import org.apache.cocoon.acting.AbstractAction;
import org.apache.cocoon.environment.ObjectModelHelper;
import org.apache.cocoon.environment.Redirector;
import org.apache.cocoon.environment.Request;
import org.apache.cocoon.environment.SourceResolver;
public class ViewSchedule extends AbstractAction {
public Map act(Redirector redirector, SourceResolver resolver,
Map objectModel, String source, Parameters par)
throws java.lang.Exception {
ScheduleDb scheduleDb = new ScheduleDb();
scheduleDb.populate();
Request request = ObjectModelHelper.getRequest(objectModel);
request.setAttribute("scheduleItemList",
scheduleDb.getList());
request.setAttribute("columnHeaders",
generateDisplayColumns(scheduleDb));
return EMPTY_MAP;
}
private String[] generateDisplayColumns(ScheduleDb scheduleDb) {
int numDisplayHeaders =
scheduleDb.getDisplayColumnHeaders().length;
String[] displayColumns = new String[numDisplayHeaders - 1];
System.arraycopy(scheduleDb.getDisplayColumnHeaders(), 1,
displayColumns, 0, numDisplayHeaders - 1);
return displayColumns;
}
}The ViewSchedule class extends the Cocoon AbstractAction class and overrides the lone abstract method, act() . This method builds a new boundary object and populates it. To pass information to the XSP, the action must have access to one of the standard collections. The ObjectModelHelper class is a Cocoon class that returns an instance of the Cocoon request object. This is not an HttpServletRequest object but rather one defined by Cocoon, though it does have the same collection semantics.
Once I have the request, I can add the two pieces of information to it (namely, the list of items and the column headers to display) and return. This action does not need to supply any parameter values to the pipeline, so I return an empty map, using the predefined protected field from the parent class.
View
The View of the schedule application is an XSP page. It appears in listing 8
<xsp:page
xmlns:xsp="http://apache.org/xsp"
xmlns:xsp-request="http://apache.org/xsp/request/2.0">
<xsp:structure>
<xsp:include>java.util.Iterator</xsp:include>
<xsp:include>
com.nealford.art.schedcocoon.entity.ScheduleItem
</xsp:include>
</xsp:structure>
<page>
<html>
<head>
<title>
Schedule Items
</title>
</head>
<body>
<p><h2>Schedule List</h2></p>
<table border="2">
<tr bgcolor="yellow">
<xsp:logic>{
String[] headers = (String [])
<xsp-request:get-attribute name="columnHeaders"/>;
for (int i = 0; i < headers.length; i++) {
<th><xsp:expr>headers[i]</xsp:expr></th> |
}
}</xsp:logic>
</tr>
<xsp:logic>{
List itemList = (List)
<xsp-request:get-attribute name="scheduleItemList"/>;
Iterator it = itemList.iterator();
while (it.hasNext()) {
ScheduleItem item = (ScheduleItem) it.next();
<tr>
<td><xsp:expr>item.getStart()</xsp:expr></td>
<td><xsp:expr>item.getDuration()</xsp:expr></td>
<td><xsp:expr>item.getText()</xsp:expr></td>
<td><xsp:expr>item.getEventType()</xsp:expr></td>
</tr>
}
}</xsp:logic>
</table>
<p/>
<a href="scheduleentry">Add New Schedule Item</a>
</body>
</html>
</page>
</xsp:page>As you can see at the top of listing 8, XSP has tags defined to perform imports (which XSP calls 'include') within a 'structure' tag. The dynamic parts of this page resemble the same parts from a JSP. I chose in this example to escape the '<' sign within the 'for' loop for the column headers to avoid the equally ugly 'CDATA ' section. One benefit of the nature of XML and the logic tag is that you can freely mix presentation and markup within the logic tag. This makes the blocks less scattered than in JSP.
This simple application should provide a feel for what web development looks like in Cocoon. Once you understand how to setup pipelines and the interaction of the publishing framework with the web framework, the web coding is straightforward.
Evaluating Cocoon
Cocoon is a very complex framework. Of course, it is more than just a web application framework, which is almost an afterthought. However, I use the same the criteria used to evaluate Cocoon as I used for the other frameworks. I consider the documentation and samples, the source code, and debugging Cocoon applications.
Documentation and Samples
The documentation for Cocoon is rather scattered. It isn't well organized at all (ironic for a publishing framework). I frequently had the experience of remembering that I saw a topic covered but not remembering where it was or how I got to it. The documentation is separated into categories, but some of them are incomplete. The phrase 'Here will soon appear an overview of '' appears in numerous places. The documentation proceeds in a narrative fashion that is useful as a tutorial but frustrating for reference material. I could not find a comprehensive index for all the topics anywhere. The table of contents page includes numerous side panel topics. The side panel topics include hyperlinks to other topics, which also have side panel topics, which have hyperlinks to other topics, etc. The best documentation for the sitemap is in the sample sitemap file itself as comments. It features a good overview of each section and embedded comments when something out of the ordinary pops up.
The samples are good but not voluminous enough for my taste. I like numerous samples, which is particularly important for a complex framework like Cocoon. One of the problems with the samples that are present is the way they are packaged. All the samples reside in a single web application (which also contains all the documentation). Configuring Cocoon is no simple manner, and it makes it difficult to look at the configuration for the samples because they are all in one place. I would have liked to see a few simple sample applications that stood alone from the large archive.
Source Code
Like any open source project, the source code is downloadable as well. When evaluating a framework, the only time I mention the source code explicitly is when I see frightening things. In several places as I was debugging in Cocoon, I saw large areas of code commented out. This appeared in a release version, not in a beta. While this isn't a crime, it is usually a sign of undisciplined developers. Every project this size uses version control, so it is never necessary to leave commented code lying around. If you need to get back to it, get it out of version control.
1) The top level elements are executed in order of appearance until one signals success. These top level elements are usually matchers. AFAIK other components are not supported for this.
The 'AFAIK' comment frightens me a little (in case you don't know, it is an acronym for 'As Far As I Know'). If the commenter of the sample sitemap file doesn't know, I'm afraid to ask who does. This is in the pipelines section, which is not a trivial section, of this critical file. I don't dispute the information ' it is probably the case that this is a rare or never seen situation. However, it is still disconcerting because it indicates that there may be other sections in the code like this.
Debugging
Debugging a Cocoon application is nice because the error messages are very informative. The errors come back as XML, and they are transformed to HTML for debugging web applications. It is certainly a good idea to include the 'handle-errors' mapping in your pipeline:
<map:handle-errors>
<map:transform src="stylesheets/system/error2html.xsl"/>
<map:serialize status-code="500" />
</map:handle-errors>This will make sure that all the errors appear as nicely formatted HTML instead of the raw XML error output.
Summary
Cocoon is a very powerful idea. It takes the concept of separation of content and presentation to a completely new level. It is also very complex. In its current incarnation, it is more suited for certain web applications more than others. If your web application already has the need to generate different output based on requests (in other words, has a need for a publishing framework), Cocoon is the obvious choice. In the very near future, it won't be an option any more ' every web application will need to handle this kind of functionality.
The main problem hampering Cocoon now is the complexity of the underlying open standards it is built upon. XSLT is a complex transformation language and not much expertise or tools exist to mitigate that. It adds a significant layer of complexity to your web application to add transformations to your content generation. Of course, you don't have to do this ' you can use the web framework as it is, using XSP as a substitute for JSP or some other presentation technology. If you do that, you aren't taking advantage of the strengths of Cocoon.
About the Author
Neal Ford is the Chief Technology Officer at The DSW Group, Ltd. He is also the designer and developer of applications, instructional materials, magazine articles, courseware, video presentations, and author of the books Developing with Delphi: Object-Oriented Techniques, JBuilder 3 Unleashed, and Art of Java Web Development. His primary consulting focus is the building of large-scale enterprise applications. He is also an internationally acclaimed speaker, having spoken at numerous developers' conferences worldwide.







