Asynchronous Processes Modeled as Persistent Finite State Machines
The need for a way to execute concurrent tasks within Java has been addressed within JSE by the java.util.concurrent.Executor and in a limited fashion in JEE by the WorkManager specification. Unfortunately, the WorkManager specification is only supported by two application servers – BEA's WebLogic and IBM's WebSphere – and does not address several requirements that commonly exist in concurrent applications.
The need for a way to execute concurrent tasks within Java has been addressed within JSE by the java.util.concurrent.Executor and in a limited fashion in JEE by the WorkManager specification. Unfortunately, the WorkManager specification is only supported by two application servers – BEA's WebLogic and IBM's WebSphere – and does not address several requirements that commonly exist in concurrent applications.
The Executor and WorkManager APIs allow asynchronous execution of a task (the WorkManager specification refers to tasks as Work objects). These tasks are generally disposable jobs that one creates, hands off to an Executor (or WorkManager) and then, possibly, waits for results from. If transactional and stateful behavior are required within a task, then a developer must implement this themselves.
Since the WorkManager specification is only supported by two vendors, users of other application servers must rely on messaging and Message Driven Beans to implement asynchronous behavior within a JEE environment. This immediately requires the use of message queues. In order to add stateful behavior to such a system, the message queue will need to be transactional, which almost immediately dictates that one use global transactions. Such a complicated setup is often overkill for a collocated application with simple requirements for asynchronous, stateful behavior.
This mini-framework attempts to provide a solution for easily defining and creating asynchronous tasks modeled as finite state machines that can be created, executed, stopped, persisted and re-executed. The mini-framework supports pluggable persistence and transaction management mechanisms so that it can be used with an O/R Mapping solution like Hibernate (and its contextual session/transaction system), Spring (for its transaction management), JPA, straight JDBC, etc.
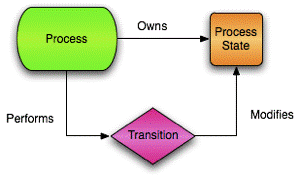
Introducing the Process, ProcessState and Transition types
Within this framework, an asynchronous task built upon a finite state machine and with support for transactions and persistence is referred to as a Process. The abstract Process class allows a user to define custom behavior that will execute in an asynchronous fashion. The Process class implements the Runnable interface which allows instances to be passed to an Executor or to be wrapped within a Work object so that it can be used with a WorkManager.
Each Process is associated with an instance of the ProcessState class. A Process contains business logic that modifies the ProcessState and transitions the finite state machine between its various states. Any business operations that modify the ProcessState object should be executed within a Transition. Referring to common terminology used when describing a finite state machine, the ProcessState class represents a process' persistent state. Conditions for executing transitions are defined using normal Java code within a concrete Process.
Code executed within a Transition will take part within a new transaction, it will automatically load the ProcessState object before running and persist the ProcessState object upon completion. This allows for very powerful behavior to be defined and encapsulated within a Process without the need to couple it to transaction and persistence-related APIs. Additionally, since conditions and transitions are defined within the concrete Process implementation, business logic is encapsulated within a single location rather than distributed across a myriad of classes and XML files. This improves readability and understandability of the process as a whole.
Building a Process with the Process Framework
I'll begin by presenting a process modeled as a sequence of operations without the Process Framework then as a finite state machine that leverages the framework.
Let's design a simple process that fetches a ticket from a database, processes the ticket, then deletes the ticket from the database. It repeats this process indefinitely until stopped.
public class TicketHandlerTask implements Runnable { private TicketDAO dao; //collaborator injected by IoC private TicketManager ticketManager; //collaborator injected by IoC private TransactionManager txManager; //collaborator injected by IoC private Ticket ticket; private boolean done = true; //...setters public void run(){ while( ! done ){ try{ txManager.beginTransaction(); transition1(); transition2(); transition3(); txManager.commitTransaction(); } catch(Exception e){ txManager.rollbackTransaction(); } } } private void transition1(){ ticket = dao.getFirstTicket(); } private void transition2(){ ticketManager.handleTicket(ticket); } private void transition3(){ dao.deleteTicket(ticket); } public void stop(){ done = true; } }
This simple task does not offer the ability to be stopped in the middle of a cycle, persisted and restarted at a later time. If the system crashes after transition2() has completed but before transition3() has executed, then the task must be re-executed from the beginning and transitions 1 and 2 must be reattempted. This may be acceptable for small, short-lived tasks but is not very practical for long-running, complicated tasks. Additionally, the response time to a stop() request is relatively slow. A request to stop the task is only acknowledged once per iteration. If each transition takes 5 minutes, then the worst-case response time for a stop request would be 15 minutes.
Let's say we want the task to be stateful so that we can stop it then restart it at a later time and have it continue exactly where it left off. In order to do this, we define a finite state machine that looks as follows:
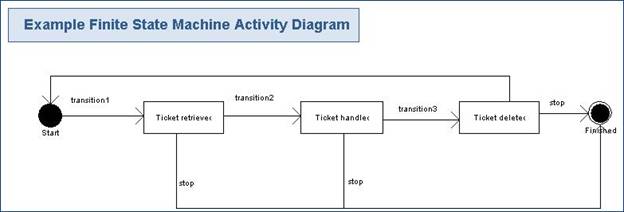
Each of the transitions should occur in an atomic fashion - the state should only be changed if the transition executed successfully. Lets see how the Process and ProcessState classes help us achieve this.
We begin by defining a custom ProcessState that defines properties that will be persisted. The ProcessState class already includes properties that are used for storing the current and previous states of the finite state machine. See the ProcessState class diagram for more details.
public class TicketHandlerProcessState extends ProcessState { //define the various states public static final int INITIAL_STATE = 0 public static final int TICKET_RETRIEVED_STATE = 1; public static final int TICKET_HANDLED_STATE = 2; private Ticket ticket; //a property that will be persisted public TicketHandlerProcessState(){ setState(INITIAL_STATE); //define the default starting state } //getter and setters for the persistent properties public Ticket getTicket(){ return ticket; } public void setTicket(Ticket ticket){ this.ticket = ticket; } }
Now we create a new Process that leverages our custom ProcessState.
public class TicketHandlerProcess extends Process<TicketHandlerProcessState> { private TicketDAO dao; //collaborator injected by IoC private TicketManager ticketManager; //collaborator injected by IoC //...setters public TicketHandlerProcess(){ //one must define a unique identifier for the process. this allows //the state management system to correlate ProcessState instances with their //parent Process. a Process and ProcessState share primary keys (their IDs). //normally the ID will be set by the component instantiating the Process instances setId(new Integer(1)); } public void run(){ while( ! done ){ switch( loadState() ){ //loadState() is a convenience method for automatically loading the //processState from the persistence store and retrieving the state value. //it is a shortcut to calling getProcessState().getState() within //a TransitionWithResult (described below) case TicketHandlerProcessState.INITIAL_STATE : transition1(); break; case TicketHandlerProcessState.TICKET_RETRIEVED : transition2(); break; case TicketHandlerProcessState.TICKET_HANDLED : transition3(); break; } } } private void transition1(){ Ticket ticket = dao.getFirstTicket(); getMyState().setTicket(ticket); setState(TicketHandlerProcessState.TICKET_RETRIEVED); //setState() is a convenience method for calling getProcessState().setState() } private void transition2(){ Ticket ticket = getProcessState().getTicket(); ticketManager.handleTicket(ticket); setState(TicketHandlerProcessState.TICKET_HANDLED); } private void transition3(){ Ticket ticket = getProcessState().getTicket(); dao.deleteTicket(ticket); setState(TicketHandlerProcessState.INITIAL_STATE); } public void stop(){ done = true; } }
The scenario above seems perfect for Aspect Oriented Programming (AOP) to handle the transaction management. Ideally, we would create an Aspect that provides Before/AfterReturning/AfterThrowing advice on all methods that begin with the word "transition". Unfortunately, these private methods are not elligible for Spring's AOP advice since they are self-invoked (see explanation below). The only other alternative would be to use AspectJ directly or to manually start a transaction at the beginning of each transition then commit the transaction after completing the transition. Additionally, one would be responsible for manually loading the ProcessState before beginning any work and to persist the ProcessState object (also within the transaction) after all changes are made.
Using straight transaction and persistence demarcation, transition1() would look as follows:
private void transition1(){ transactionManager.beginTransaction(); try{ ProcessState ps = dao.getProcessState(getId()); Ticket ticket = dao.getFirstTicket(); ps.setTicket(ticket); ps.setState(TicketHandlerProcessState.TICKET_RETRIEVED); dao.saveProcessState(ps); transactionManager.commitTransaction(); } catch(Exception e){ transactionManager.rollbackTransaction(); } }
This would need to be repeated for every business operation that results in a state transition.
This has multiple drawbacks. First, business logic gets swamped with transaction and persistence code. Second, the developer must manually begin, commit and rollback the transaction. Third, it couples the client's Process implementation to a transaction API.
Using the Transition callback interface, we can elegantly demarcate each of the state transitions as an atomic operation that occurs within a transaction. Let's see how transition1() would look using the Transition callback:
private void transition1(){ performTransition(new Transition(){ public void doTransition(){ Ticket ticket = dao.getFirstTicket(); getProcessState().setTicket(ticket); setState(TicketHandlerProcessState.TICKET_RETRIEVED); } } }
The method Process.performTransition(Transition transition) delegates to a TransitionManager that ensures the code in the doTransition() method automatically partakes in a transaction which is committed or rolled-back based on its success or failure. Failure is, of course, defined by user code throwing some runtime exception. Before the transition begins, the ProcessState object that corresponds to this particular Process is automatically retrieved from the underlying persistence store and injected into the Process; at the end of a successful transition, the ProcessState is automatically persisted back to the persistence store. This allows us to stop the Process at any time; when the Process is restarted at a later date, its state will represent the last successful transition. This allows a process to automatically jump back to the state where it last left off.
Transition and TransitionWithResult Types
A transition is available in two different formats: Transition and TransitionWithResult. Both of these interfaces define a single method named doTransition() , the only difference being that the Transition interface has a void return type while the TransitionWithResult returns an Object. Generally, the simple Transition interface will suffice to perform most business logic but occasionally it may be useful to return some data from within a transition back out to a process' "non-transitional" code. For example, imagine your process has some listeners and you want the process to inform them of the result of some transition. Ideally, the listener callbacks should be invoked outside of a transition so as to avoid long-running transactions. In such a scenario, you could do something as follows:
Boolean fileProcessedOk = (Boolean)performTransition( new TransitionWithResult(){ public Object doTransition(){ //some logic return new Boolean(true); } }); //do something with boolean result outside transition
TransitionManager and ProcessStatePersister Interfaces
Each Process instance must be injected with a TransitionManager. The TransitionManager is responsible for:
- loading the ProcessState instance for a particular Process from the persistence store (via a ProcessStatePersister)
- creating a ProcessState instance if no record exists in the persistence store for a particular Process
- injecting the Process' ID value into newly created ProcessState instances
- injecting the newly created ProcessState (or one retrieved from the persistence store) into a Process
- executing the Transition object
- saving or updating the ProcessState instance back to the persistence store after a successful transition (via the ProcessStatePersister)
- reattempting failed transitions
In order to accomplish these tasks, the TransitionManager is assisted by a ProcessStatePersister which loads and saves ProcessState instances.
The TransitionManager interface defines four methods; the most important one being:
void executeTransition(Process<? extends ProcessState> process, Transition transition) throws TransitionException;
A default implementation has been provided named TransitionManagerImpl. This class implements TransitionManager and its various methods have been annotated @Transactional as follows:
@Transactional void executeTransition(Process<? extends ProcessState> process, Transition transition) throws TransitionException;
This means you can simply define a TransitionManagerImpl bean in a Spring application context and have your custom transaction handling mechanism advise the TransitionManagerImpl with Before/AfterReturning/AfterThrowing advice. You can create your own transaction aspect or use a predefined one from a framework such a Spring.
Each Process has a special property named autoManageState which is true by default. When this property is true, the TransitionManager automatically loads a Process' process state from the persistence store and injects it into the Process before the transition is executed. After the transition has been executed, and assuming no errors occurred in the middle of the transition, the process state is automatically persisted back to the persistence store. A Process that does not want to have its state automatically managed may simply set the autoManageState property to false (in its constructor or via dependency injection). When Process.performTransition() is invoked, the underlying implementation will automatically delegate to the TransitionManager's methods that do not auto-manage the process' state. This can be useful if you define a process who's state does not need to be persisted but which still requires the ability to demarcate transactional units of work within the process flow.
The ProcessStatePersister interface defines three methods:
- public ProcessState getProcessState(Class clazz, Integer id) throws PersistenceException;
- public void saveNewInstance(ProcessState processState) throws PersistenceException;
- public void persistChanges(ProcessState processState) throws PersistenceException;
The TransitionManager implementation must be provided with a ProcessStatePersister in order to save, update and load a Process’ ProcessState instance from the persistence store. Implementations may use straight JDBC, Spring’s JDBC template, or an O/R Mapping solution like Hibernate.
Example Hibernate ProcessStatePersister Implementation
Integration with Hibernate is super trivial.
Here is an example of a very basic solution that leverages Hibernate's thread-based contextual Sessions (which maps perfectly to the framework since each Process is executed by a separate thread).
public class HibernateProcessStatePersister implements ProcessStatePersister { private SessionFactory sf; public void setSessionFactory(SessionFactory sf){ this.sf = sf; } public ProcessState getProcessState(Class clazz, Integer id) throws PersistenceException { return (ProcessState)sf.getCurrentSession().get(clazz, id); } public void saveNewInstance(ProcessState processState) throws PersistenceException { sf.getCurrentSession().save(processState); } public void persistChanges(ProcessState processState) throws PersistenceException { sf.getCurrentSession().flush(); } }
Next, you would define a Hibernate mapping for your ProcessState implementation. Remember to persist the three properties in the ProcessState itself: id , state and previousState . If your ProcessState has an additional property lastName:String then your Hibernate mapping document might look like this:
<class name="com.my.BasicProcessState" table="BasicProcessState"> <id name="id"/> <property name="state"/> <property name="previousState"/> <property name="lastName"/> </class>
Of course, persistent collections and other mapped entities are allowed as properties in your ProcessState as well.
Finally, your database table might look like this if you are using MySQL with InnoDB tables:
CREATE TABLE BasicProcessState ( `id` INT PRIMARY KEY, `state` SMALLINT NOT NULL, `previousState` SMALLINT NOT NULL, `lastName` VARCHAR(30) NOT NULL ) ENGINE=InnoDB;
And there you have it. Process state persistence to any database of your liking with Hibernate and zero lines of SQL.
Lazy Loading ProcessState Properties to Improve Efficiency with Large Object Graphs
One of the major advantages of using an O/R Mapping solution like Hibernate for persistence is that it allows one to take advantage of lazy-loading features. If your ProcessState represents large amounts of data or contains particularly complex object graphs, it will be very inefficient to constantly load and persist the whole graph each time a state transition occurs. Hibernate provides the ability to denote particular properties as lazy-loaded, meaning the actual data will only be retrieved from the database when it is needed. In the background, your ProcessState properties are injected with proxy-based, place holders that, when required, actually go out to the database and fetch the relevant data. This happens behind the scenes and your Process need not know if the persistent properties are being lazy-loaded or not. It is possible to accomplish such a thing with a JDBC implementation of the ProcessStatePersister interface but requires a lot more effort on your behalf.
Workflows
A well-designed process is reusable in various contexts - one of those contexts may be as part of a larger workflow. Often times, a group of processes need to be run in a particular order to accomplish a greater task. At the Web Service level, BPEL attempts to address these concerns. This Process Framework can assist in creating workflows for stand-alone applications that execute outside a Process Server. One of the major advantage of the Process class is an instance can be invoked from within another Process. If you want to chain a group of processes together, you can simply create a workflow: a wrapper Process which invokes various subprocesses synchronously. Let's say you have created ProcessA and ProcessB, you want to execute them sequentially and you only want ProcessB to execute if ProcessA completes successfully. Let us assume that both ProcessA and ProcessB are stateful and stoppable as demonstrated in the example above. This behavior can be modeled as a workflow that might look as follows:
public class MyWorkflow extends Process { private ProcessA processA; //injected via IoC private ProcessB processB; //injected via IoC private boolean done; //setters for the two processes public void run(){ if( processA.getState != ProcessAState.FINISHED ) processA.run(); if( processA.getState() == ProcessAState.FINISHED && ! done ) processB.run(); } public void stop(){ done = true; processA.stop(); processB.stop(); } }
In a real scenario, one would want to check the termination codes of each subprocess after either one completes in order to determine control flow and to define the workflow's termination code. For example, after the call to processA.run() , one would check if its termination code was also "normal" before proceeding to execute ProcessB. This is important to avoid invoking ProcessB after ProcessA fails. A simple workflow like the one above does not need to maintain its own state but can still be started, stopped and restarted at a later time because it is built upon stateful processes. Upon re-invocation it need only check the states of its subprocesses in order to determine where to continue execution. When stop() is invoked on the workflow, it simply propagates the stop request to all of its subprocesses which ensures that none of them begin execution and that any currently executing subprocess is stopped. In the above example, the done flag simply improves response time; it is still important to issue the termination request to ProcessB to ensure it does not run due to the race condition that arises between one thread checking the done flag and another thread setting the done flag to true.
Distributed Transactions and non-AOP Transaction Management
Long-running processes may collaborate with various transactional resources - this necessitates the use of global transactions. Since a Process is completely agnostic of the transaction management scheme that is being used to wrap state transitions, it is very easy to plug in a distributed, transaction management strategy. Generally this implies that one will be using JTA. Once again, a pre-fabricated solution such as Spring's JTATransactionManager or Hibernate's JTA transaction support can be used to provide advice to the @Transactional state transitions.
If you prefer not to offer AOP advice, you can subclass TransitionManagerImpl and implement the beforeTransition() , afterTransitionReturns() and afterTransitionThrows() hooks to invoke your own custom transaction handling mechanism directly.
Idempotent Transitions
Some types of state transitions may involve business operations that can fail but which can be simply reattempted at a later time. When a transition fails, the changes made to a process' state are aborted. We can leverage this feature to easily reattempt a failed, idempotent business operation.
In the example above, imagine transition1() may fail because of a temporary database outage. The process framework allows one to easily define the following properties:
- which transitions are idempotent
- how many times an idempotent transition should be reattempted
- the amount of time to wait between failed attempts (in seconds, minutes or hours)
- the types of exceptions that cause a transition to be reattempted
In order to define an idempotent transition, we create an inner class and annotate is as @Idempotent.
@Idempotent(attempts=3, delay="5m", ex={com.my.Exception.class, com.my.OtherException.class}) private class RetrieveTicket implements Transition { public void doTransition(){ Ticket ticket = dao.getFirstTicket(); getProcessState().setTicket(ticket); setState(TicketHandlerProcessState.TICKET_RETRIEVED); } }
Executing the state transition is then as simple as:
performTransition(new RetrieveTicket());
The @Idempotent annotation accepts the following attributes:
- attempts - Defines the number of times the transition will be attempted (including the first execution). If this attribute is not specified, then the default value of 3 attempts is used.
- delay - A numerical value followed by either "s", "m", or "h" to represent the number of seconds, minutes or hours to wait between attempts. If this attribute is not specified, then the default value of 5 minutes is used.
- ex - An array of classes (runtime exceptions) that will cause the transition to be reattempted. If this attribute is not specified, then all exceptions cause the operation to be reattempted.
If the user code in the above Transition throws either a com.my.Exception or a com.my.OtherException , then the TransitionManager will wait for 5 minutes, then reattempt to execute the Transition. If, after a total of 3 attempts, an exception is still thrown, the TransitionManager will abort and wrap the exception in a TransitionException then propagate it back to the Process.
Ideally, one could simply create an annotated, anonymous class, or better yet, an annotated closure but alas, this is not yet possible.
ProcessManager Interface
The Process class implements the java.lang.Runnable interface which makes a Process eligible for execution via a java.util.concurrent.Executor . In order to execute a Process asynchronously, simply pass an instance of the Process to the Executor's execute(Runnable runnable) method. To stop a Process, simply invoke the Process' stop() method. The stop() method must be implemented by the Process designer. If you want more control over managing processes, you can use the ProcessManager interface. The ProcessManager interface simply defines a contract for performing managerial operations on groups of processes. The ProcessManager interface also provides some methods that can be of use for managing individual processes such as waitForProcessToTerminate(Process process) . When this method is invoked, the caller blocks until the given Process has completed execution (which will have been previously requested by invoking its stop() method). Finally, the ProcessManager interface provides a method named execute(Process process) which essentially correlates to the Executor's execute(Runnable runnable) method.
A default implementation of the ProcessManager has been provided backed by a java.util.concurrent.ThreadPoolExecutor . The ThreadPoolExecutorProcessManager hooks into the ThreadPoolExecutor's beforeExecute() and afterExecute() methods to add its extra functionality. The ProcessManager method execute(Process process) simply delegates to the Executor's execute(Runnable runnable) method. It is easy to define your own custom ProcessManager that is backed by something else. It is even possible to implement a very exotic implementation that pushes a Process to a Message Driven Bean to be executed, for example; or an implementation backed by a WorkManager.
Of course, usage of the ProcessManager interface is entirely optional.
Asynchronous Notification of Process Termination
An alternative to waiting for a process to end via the ProcessManager is to register a ProcessTerminationListener callback that is asynchronously invoked when your process finishes running. The Process class offers methods to add and remove ProcessTerminationListeners as well as the method notifyProcessTerminationListeners() that notifies all registered listeners. It is the duty of the developer of the Process to invoke this method at the end of the Process' run() method. Ideally the invocation should be placed in a finally block within the run() method. It is also important to note that the ProcessTerminationListeners' callbacks will be invoked by the thread that is executing the Process.
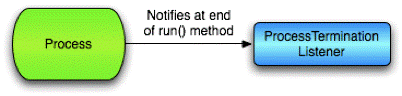
ProgressStatus Listeners
It may be necessary for external components to know the progress of a process. In order to accommodate this, a Process may fire PropertyChangeEvents that contain instances of ProgressStatus. The ProgressStatus class encapsulates a progress value and a message. Within a concrete Process, it would make sense to fire a ProgressStatus property change event whenever some major event takes place in the process. If the Process represents a long-running process with a definite end, you can use the ProgressStatus events to represent completion status, for example, on a scale of 0 - 100.
Example Spring Integration
Below is an example of some beans in a Spring application context when using the Process framework together with Spring and Hibernate. The first two beans must be defined for the Process framework. The third bean, "processManager", is only needed if you are using its extra features, otherwise a simple ThreadPoolExecutor would suffice. The fourth bean, "myProcess", is a user defined process with a "prototype" scope so that a new instance is created whenever it is fetched from the ApplicationContext. The process instance is automatically injected with the required "transitionManager". Finally, the last set of beans are Spring-specific for adding transactional advice to the TransitionManager's @Transactional methods.
<bean id="processStatePersister" class="com.my.persistence.hibernate.HibernateProcessStatePersister"> <property name="sessionFactory" ref="sessionFactory"/> </bean> <bean id="transitionManager" class="org.javenue.util.process.TransitionManagerImpl"> <property name="processStatePersister" ref="processStatePersister"/> </bean> <bean id="processManager" class="org.javenue.util.process.ThreadPoolExecutorProcessManager"/> <bean id="myProcess" class="com.my.MyProcess" scope="prototype"> <property name="transitionManager" ref="transitionManager"/> </bean> <tx:advice id="txAdvice" transaction-manager="txManager"/> <aop:config> <aop:pointcut id="transitions" expression="@annotation(org.javenue.util.process.Transactional)"/> <aop:advisor advice-ref="txAdvice" pointcut-ref="transitions"/> </aop:config> <bean id="txManager" class="org.springframework.orm.hibernate.HibernateTransactionManager"> <property name="sessionFactory" ref="sessionFactory" /> </bean>
Executing your process is then as simple as:
ProcessManager pm = (ProcessManager)appContext.getBean("processManager"); MyProcess p = (MyProcess)appContext.getBean("myProcess"); p.setId(1); pm.execute(p); //executes process asynchronously p.stop(); //sends a request to the process to stop executing pm.waitForProcessToTerminate(p); //blocks the calling thread until the process actually finishes
At any time in the future, if you want your process to be restarted, simply fetch a new instance from the ApplicationContext, set the respective ID again (in this case to 1) and execute it; its state will be automatically re-associated with it and the process will begin executing where it previously left off.
Why Spring's AOP Isn't Applicable
In traditional, user-driven, request/response environments, one will define a set of business objects that represent a service layer. Usually, the business operations exposed by the service layer are transactional with transaction demarcation occurring either via AOP or CMT. The Spring Framework offers great support for AOP using a proxy-based approach that, in most scenarios, is perfectly sufficient for a user's requirements. A naive approach to adding cross-cutting behavior to internal operations that result in state changes would be to annotate private operations so that they can be advised using AOP.
Unfortunately, Spring's AOP solution has one major caveat. As is stated in the Spring 2.0 documentation, an advised bean that calls advised operations on itself, "such as this.bar() or this.foo() , are going to be invoked against the this reference, and not the proxy. This has important implications. It means that self-invocation is not going to result in the advice associated with a method invocation getting a chance to execute." Operations executed within an asynchronous Process will often need to manipulate several properties of the ProcessState instance in an atomic fashion. The only other way to cleanly add this cross-cutting behavior is to use AspectJ directly. This, of course, adds complexity and necessitates compile or deploy-time weaving.
UML Design Documents
The following UML design documents are available for download:
- >Process Framework Use Case Diagram
- >Process Framework Class Diagram
- >Process Manager Class Diagram
- >Execute Asynchronous Process Sequence Diagram
- >Execute Transition Sequence Diagram
The UML diagrams were created with the TopCoder UML Tool.
Conclusion
The Process Framework presented here offers one the ability to create asynchronous, long-lived, stoppable processes modeled as finite state machines. The framework allows for "pluggable" transaction management and persistence schemes and plays very nicely with two of the most popular solutions: Spring and Hibernate.
Process business logic is encapsulated within a concrete Process implementation. Operations that alter a process' state are wrapped within transitions that execute in a transactional fashion. Conditional logic used for directing flow control between transitions is easily defined using normal code within the process implementation. Finally, the actual process state is disjoint from the process logic and is automatically managed by the framework.
The main goal of this framework is to provide a mechanism for creating business processes in Java that are more powerful than traditional Java tasks (as provided by the java.util.concurrent package) but less complex than BPEL processes.
Availability
The design is mostly finished and UML documents have been provided above. Implementation is almost complete and I will be providing the source online as soon as it's ready. If you would like to contact me regarding the framework or are interested in using it as quickly as possible, send me an email at [email protected] .





