Introduction to the Spring Framework 2.5
The Spring Framework has continued to grow in popularity, and has become the de facto standard for enterprise Java development. In this article, I'll try to explain what Spring sets out to achieve, and how I believe it can help you to develop enterprise Java applications.
Check out these updated Tutorials for Spring 3 and Hibernate 3.x
Since I last revised this article in May, 2005, the Spring Framework has continued to grow in popularity, and has become the de facto standard for enterprise Java development. It has progressed from version 1.2 to the present 2.5, and has been adopted in an even wider range of industries and projects. In this article, I'll try to explain what Spring sets out to achieve, and how I believe it can help you to develop enterprise Java applications.
Why Spring?
I believe that Spring is unique, for several reasons:
- It addresses important areas that other popular frameworks don't. Spring focuses around providing a way to manage your business objects.
- Spring is comprehensive and modular. Spring has a layered architecture, meaning that you can choose to use just about any part of it in isolation, yet its architecture is internally consistent. So you get maximum value from your learning curve. You might choose to use Spring only to simplify use of JDBC, for example, or you might choose to use Spring to manage all your business objects. And it's easy to introduce Spring incrementally into existing projects.
- Spring is designed from the ground up to help you write code that's easy to test. Spring is an ideal framework for test driven projects.
- Spring is an increasingly important integration technology, its role recognized by vendors large and small.
- The Spring Framework is the core of the Spring Portfolio , an increasingly complete solution for enterprise Java development, exhibiting the same consistency of approach developed in the Spring Framework itself.
Spring addresses most infrastructure concerns of typical applications. It also goes places other frameworks don't.
An open source project since February 2003, Spring has a long heritage. The open source project started from infrastructure code published with my book, Expert One-on-One J2EE Design and Development, in late 2002. Expert One-on-One J2EE laid out the basic architectural thinking behind Spring. However, the core architectural concepts go back to early 2000, and reflect my experience in developing infrastructure for a series of successful commercial projects.
There are now almost 40 developers, with the leading contributors devoted full-time to Spring development and support at Interface21. The flourishing open source community has helped it evolve into far more than could have been achieved by any individual.
Architectural benefits of Spring
Before we get down to specifics, let's look at some of the benefits Spring can bring to a project:
- Spring can effectively organize your middle tier objects. Spring takes care of plumbing that would be left up to you if you use only Struts or other frameworks geared to particular J2EE APIs. And Spring's configuration management services can be used in any architectural layer, in whatever runtime environment.
- Spring can eliminate the proliferation of Singletons seen on many projects. In my experience, this is a major problem, reducing testability and object orientation.
- Spring eliminates the need to use a variety of custom properties file formats, by handling configuration in a consistent way throughout applications and projects. Ever wondered what magic property keys or system properties a particular class looks for, and had to read the Javadoc or even source code? With Spring you simply look at the class's JavaBean properties or constructor arguments. The use of Inversion of Control and Dependency Injection (discussed below) helps achieve this simplification.
- Spring facilitates good programming practice by reducing the cost of programming to interfaces, rather than classes, almost to zero.
- Spring is designed so that applications built with it depend on as few of its APIs as possible. Most business objects in Spring applications have no dependency on Spring.
- Applications built using Spring are very easy to test. For certain unit testing scenarios, the Spring Framework provides mock objects and testing support classes. Spring also provides unique “integration testing” functionality in the form of the Spring TestContext Framework and legacy JUnit 3.8 support classes that enable you to test your code quickly and easily, even while accessing a staging database.
- Spring helps you solve problems with the most lightweight possible infrastructure. Spring provides an alternative to EJB that's appropriate for many applications. For example, Spring can use AOP to deliver declarative transaction management without using an EJB container; even without a JTA implementation, if you only need to work with a single database, or want to avoid two phase commit.
- Spring provides a consistent framework for data access, whether using JDBC or an O/R mapping product such as TopLink, Hibernate or a JPA or JDO implementation.
- Spring provides a consistent, simple programming model in many areas, making it ideal architectural "glue." You can see this consistency in the Spring approach to JDBC, JMS, JavaMail, JNDI and many other important APIs.
Spring is essentially a technology dedicated to enabling you to build applications using Plain Old Java Objects (POJOs). It enables you to develop components as POJOs containing only your business logic, while the framework takes care of the many value adds you need to build enterprise applications — even in areas that you may not have considered when initially authoring the application. This goal requires a sophisticated framework, which conceals much complexity from the developer. Because your business logic is abstracted from infrastructure concerns, it’s also likely to enjoy a longer life, improving the return on investment of writing it. Business logic should change at the pace of your business; only if it is abstracted from infrastructure concerns can the impact on your code base of inevitable infrastructure change (such as choice of application server) be minimized.
Thus Spring can enable you to implement the simplest possible solution to your problems. And that's worth a lot.
What does Spring do?
Spring provides a lot of functionality. So I'll quickly review each major area in turn.
Mission statement
Spring's main aim is to make enterprise Java easier to use and promote good programming practice. It does this by enabling a POJO-based programming model that is applicable in a wide range of environments. We believe that Spring provides the ultimate programming model for modern enterprise Java.
Spring does not reinvent the wheel. Thus you'll find no logging packages in Spring, no connection pools, no distributed transaction coordinator. All these things are provided by open source projects (such as Commons Logging, which we use for all our log output, or Commons DBCP), or by your application server or web container. For the same reason, we don't provide an O/R mapping layer. There are good solutions to this problem such as TopLink, Hibernate, JPA and JDO.
Spring does aim to make existing technologies easier to use and does aim to provide a unified, simple yet powerful programming model. For example, although we are not in the business of low-level transaction coordination, we provide an abstraction layer over JTA or any other transaction strategy that is more portable, easier to use and makes code easier to test.
Spring benefits from internal consistency. All the developers are singing from the same hymn sheet, whose fundamental ideas remain faithful to those of Expert One-on-One J2EE Design and Development. And we've been able to use some central concepts, such as Inversion of Control, across multiple areas.
Spring is portable between application servers and web containers. (Indeed, its core functionality does not require another container.) Of course ensuring portability is always a challenge, but we avoid anything platform-specific or non-standard in the developer's view, and support users on WebLogic, Tomcat, Resin, JBoss, Jetty, Geronimo, WebSphere and other application servers. Spring's non-invasive, POJO approach enables us to take advantage of environment-specific features without sacrificing portability, as in the case of enhanced WebLogic, WebSphere and OC4J transaction management functionality that uses BEA and IBM proprietary APIs under the covers.
Inversion of control container
The core of Spring is the org.springframework.beans package, designed for working with POJOs. This package typically isn't used directly by users, but underpins much Spring functionality.
The next higher layer of abstraction is the bean factory. A Spring bean factory is a generic factory that enables configured objects to be retrieved by name, and which can manage relationships between objects.
A word on the term “bean”: very early versions of Spring were intended to configure only JavaBean objects. Since 1.0, Spring has been able to configure just about any Java object, regardless of whether it uses accessor and mutator methods, and in 2.5 it has become still more flexible. Nevertheless the term “Spring Bean” has remained common parlance. “Spring-managed object” is a more accurate term, conveying also the fact that Spring does not merely configure objects, but often continues to manage them at runtime -- for example, to apply enterprise services on every invocation.
Bean factories support three modes of object lifecycle:
- Singleton: in this case, there's one shared instance of the object with a particular name, which will be retrieved on lookup. This is the default, and most often used, mode. It's ideal for stateless service objects.
- Prototype or non-singleton: in this case, each retrieval will result in the creation of an independent object. For example, this could be used to allow each caller to have a distinct object reference.
- Custom object “scopes”, which typically interact with a store outside the control of the container. Some of these come out of the box, such as request and session (for web applications). Others come with third party products, such as clustered caches. It is easy to define custom scopes in the event that none of those provided out of the box is sufficient, through implementing a simple interface.
Because the Spring container manages relationships between objects, it can add value where necessary through services such as transparent pooling for managed POJOs, and support for hot swapping, where the container introduces a level of indirection that allows the target of a reference to be swapped at runtime without affecting callers and without loss of thread safety. One of the beauties of Dependency Injection (discussed shortly) is that all this is possible transparently, with no API involved.
As org.springframework.beans.factory.BeanFactory is a simple interface, it can be implemented in different ways. The BeanDefinitionReader interface separates the metadata format from BeanFactory implementations themselves, so the generic BeanFactory implementations Spring provides can be used with different types of metadata. You could easily implement your own BeanFactory or BeanDefinitionReader, although few users find a need to. The most commonly used BeanFactory definitions are:
- XmlBeanFactory. This parses a simple, intuitive XML structure defining the classes and properties of named objects.
- DefaultListableBeanFactory: This provides the ability to parse bean definitions in properties files, and create BeanFactories programmatically.
Each bean definition can be a POJO (defined by class name and JavaBean initialization properties or constructor arguments), or a FactoryBean. The FactoryBean interface adds a level of indirection. Typically this is used to create proxied objects using AOP or other approaches: for example, proxies that add declarative transaction management. This is conceptually similar to EJB interception, but works out much simpler in practice, and is more powerful.
BeanFactories can optionally participate in a hierarchy, "inheriting" definitions from their ancestors. This enables the sharing of common configuration across a whole application, while individual resources such as controller Servlets also have their own independent set of objects.
This motivation for the use of JavaBeans is described in Chapter 4 of Expert One-on-One J2EE Design and Development, which is available on the ServerSide as a free PDF.
Through its bean factory concept, Spring is an Inversion of Control container. (I don't much like the term container, as it conjures up visions of heavyweight containers such as EJB containers. A Spring BeanFactory is a container that can be created in a single line of code, and requires no special deployment steps.) Spring is most closely identified with a flavor of Inversion of Control known as Dependency Injection – a name coined by Martin Fowler, Rod Johnson and the PicoContainer team in late 2003.
The concept behind Inversion of Control is often expressed in the Hollywood Principle: "Don't call me, I'll call you." IoC moves the responsibility for making things happen into the framework, and away from application code. Whereas your code calls a traditional class library, an IoC framework calls your code. Lifecycle callbacks in many APIs, such as the setSessionContext() method for session EJBs, demonstrate this approach.
Dependency Injection is a form of IoC that removes explicit dependence on container APIs. Ordinary Java methods are used to inject dependencies such as collaborating objects or configuration values into application object instances. Where configuration is concerned this means that while in traditional container architectures such as EJB, a component might call the container to say "where's object X, which I need to do my work", with Dependency Injection the container figures out that the component needs an X object, and provides it to it at runtime. The container does this figuring out based on method signatures (usually JavaBean properties or constructors) and, possibly, configuration data such as XML.
The two major flavors of Dependency Injection are Setter Injection (injection via JavaBean setters); and Constructor Injection (injection via constructor arguments). Spring provides sophisticated support for both, and even allows you to mix the two when configuring the one object.
As well as supporting all forms of Dependency Injection, Spring also provides a range of callback events, and an API for traditional lookup where necessary. However, we recommend a pure Dependency Injection approach in general.
Dependency Injection has important benefits. For example:
- Because components don't need to look up collaborators at runtime, they're much simpler to write and maintain. In Spring's version of IoC, components express their dependency on other components via exposing JavaBean setter methods or through constructor arguments. For example, there is no need for JNDI lookups, which require the developer to write code that makes environmental assumptions.
- For the same reasons, application code is much easier to test. For example, JavaBean properties are simple, core Java and easy to test: simply write a self-contained JUnit or TestNG test method that creates the object and sets the relevant properties.
- A good IoC implementation preserves strong typing. If you need to use a generic factory to look up collaborators, you have to cast the results to the desired type. This isn't a major problem, but it is inelegant. With IoC you express strongly typed dependencies in your code and the framework is responsible for type casts. This means that type mismatches will be raised as errors when the framework configures the application; you don't have to worry about class cast exceptions in your code.
- Dependencies are explicit. For example, if an application class tries to load a properties file or connect to a database on instantiation, the environmental assumptions may not be obvious without reading the code (complicating testing and reducing deployment flexibility). With a Dependency Injection approach, dependencies are explicit, and evident in constructors or JavaBean properties.
- Most business objects don't depend on IoC container APIs. This makes it easy to use legacy code, and easy to use objects either inside or outside the IoC container. For example, Spring users often configure the Jakarta Commons DBCP DataSource as a Spring bean: there's no need to write any custom code to do this. We say that an IoC container isn't invasive: using it won't invade your code with dependency on its APIs. Almost any POJO can become a component in a Spring bean factory. Existing JavaBeans or objects with multi-argument constructors work particularly well, but Spring also provides unique support for instantiating objects from static factory methods or even methods on other objects managed by the IoC container.
This last point deserves emphasis. Dependency Injection is unlike traditional container architectures, such as EJB, in this minimization of dependency of application code on a container. This means that your business objects can potentially be run in different Dependency Injection frameworks - or outside any framework - without code changes.
In my experience and that of Spring users, it's hard to overemphasize the benefits that IoC -- and, especially, Dependency Injection -- brings to application code.
Spring BeanFactories are very lightweight. Users have successfully used them inside applets, as well as standalone Swing applications. There are no special deployment steps and no detectable startup time associated with the container itself (although certain objects configured by the container may of course take time to initialize). This ability to instantiate a container almost instantly in any tier of an application can be very valuable.
The Spring BeanFactory concept is used throughout Spring, and is a key reason that Spring is so internally consistent. Spring is also unique among IoC containers in that it uses IoC as a basic concept throughout a full-featured framework.
Most importantly for application developers, one or more BeanFactories provide a well-defined layer of business objects. This is analogous to, but simpler (yet more powerful), than a layer of local session beans. Having a well-defined layer of business objects is very important to a successful architecture.
A Spring ApplicationContext is a subinterface of BeanFactory, which provides support for:
- Message lookup, supporting internationalization
- An event mechanism, allowing application objects to publish and optionally register to be notified of events
- Automatic recognition of special application-specific or generic bean definitions that customize container behavior
- Portable file and resource access
XmlBeanFactory example
Spring users traditionally configure their applications in XML "bean definition" files, although other forms of configuration, including source-level annotations, properties files and Java code, can also be used, and Spring will merge the results of the different configuration sources.
The root of a Spring XML bean definition document is a <beans> element. The <beans> element contains one or more <bean> definitions. We normally specify the class and properties of each bean definition. We normally also specify the id, which will be the name that we'll use this bean with in our code.
Let's look at a simple example, which configures three application objects with relationships commonly seen in enterprise Java applications:
- A DataSource used to connect to a relational database
- A data access object (DAO) that uses the DataSource
- A business object that uses the DAO in the course of its work
In the following example, we use a BasicDataSource from the Jakarta Commons DBCP project. ComboPooledDataSource from the C3PO project is also an excellent option. BasicDataSource, like many other existing classes, can easily be used in a Spring bean factory, as it offers JavaBean-style configuration. The close() method that needs to be called on shutdown can be registered via Spring's "destroy-method" attribute, to avoid the need for BasicDataSource to implement any Spring interface.
<beans> <bean id="myDataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close" p:driverClassName="com.mysql.jdbc.Driver" p:url="jdbc:mysql://localhost:3306/mydb" p:username="someone"/>
All the properties of BasicDataSource we're interested in are Strings, so we specify their values using the "p:" attribute prefix, a special, non-validated Spring namespace that allows the use of bean property names as XML attributes. This shortcut was introduced in Spring 2.0 as a convenient alternative to the "value" attribute or <value> subelement, which is usable even for values that are problematic in XML attributes. Spring uses the standard JavaBean PropertyEditor mechanism to convert String representations to other types if necessary.
Now we define the DAO, which has a bean reference to the DataSource. Relationships between beans are specified using a combination of the "p:" prefix and "-ref" suffix, the "ref" attribute, or the <ref> element:
<bean id="exampleDataAccessObject" class="example.ExampleDataAccessObject" p:dataSource-ref="myDataSource"/>
The business object has a reference to the DAO, and an int property (exampleParam):
<bean id="exampleBusinessObject" class="example.ExampleBusinessObject" p:dataAccessObject-ref="exampleDataAccessObject" p:exampleParam="10"/> </beans>
Relationships between objects are normally set explicitly in configuration, as in this example. We consider this to be a Good Thing in most cases. However, Spring also provides two kinds of what we call "autowire" support, where it figures out the dependencies between beans: autowire by type, and autowire by name
The limitation with autowiring by type is that if there are multiple beans of a particular type it's impossible to work out which instance a dependency of that type should be resolved to. Unsatisfied dependencies are caught when the factory is initialized. (Spring also offers an optional dependency check for explicit configuration, which verifies that all properties have been set.)
This limitation in autowiring by type can often be overcome by autowiring by name. When using autowire by name, property names are used instead of types. For example, if a bean expresses a dependency by defining a setMaster method, Spring will try to find a bean with the name "master" within the BeanFactory and inject that bean to satisfy the dependency. While autowire by type works with either constructors or setter methods, autowire by name works automatically only with setter methods: a result of the fact that Java reflection does not expose the names of constructor or other method arguments. Spring 2.5 allows autowiring by name to be used for constructors via the @Qualifier parameter annotation. See the “Beyond XML” section below for further details.
We could use the autowire by type feature as follows in the above example, if we didn't want to code these relationships explicitly:
<bean id="exampleBusinessObject" class="example.ExampleBusinessObject" autowire="byType"> <property name="exampleParam" value="10" /> </bean>
With this usage, Spring will work out that the dataSource property of exampleBusinessObject should be set to the implementation of DataSource it finds in the present BeanFactory. It's an error if there is none, or more than one bean of the required type in the present BeanFactory. We still need to set the exampleParam property, as it's not a reference.
Autowire support has the advantage of reducing the volume of configuration, especially when used as an optional attribute on the root <beans> element, which activates autowiring for all beans managed by Spring. It also means that the container learns about application structure using reflection, so if you add an additional constructor argument of JavaBean property, it may be successfully populated without any need to change configuration. The tradeoffs around autowiring should be evaluated carefully.
Externalizing relationships from Java code often has great benefit over hard coding them, as it's possible to change XML files without changing a line of Java code. For example, we could simply change the myDataSource bean definition to refer to a different bean class to use an alternative connection pool, or a test data source. We could use JNDI to get a data source from an application server in a single alternative XML stanza, as follows. There would be no impact on Java code or any other bean definitions.
<jee:jndi-lookup id="myDataSource" jndiName="jdbc/myDataSource" />
Now let's look at the Java code for the example business object. Note that there are no Spring dependencies in the code listing below. A Spring IoC container is not invasive: you don't normally need to code awareness of it into application objects.
public class ExampleBusinessObject implements MyBusinessObject { private ExampleDataAccessObject dao; private int exampleParam; public void setDataAccessObject(ExampleDataAccessObject dao) { this.dao = dao; } public void setExampleParam(int exampleParam) { this.exampleParam = exampleParam; } public void myBusinessMethod() { // do stuff using dao } }
Note the property setters, which correspond to the XML references in the bean definition document. These are invoked by Spring before the object is used.
Such application beans do not need to depend on Spring. They don't need to implement any Spring interfaces or extend Spring classes: they just need to observe JavaBeans naming conventions. Reusing one outside of a Spring application context is easy, for example in a test environment. Just instantiate it with its default constructor, and set its properties manually, via setDataSource() and setExampleParam() calls. So long as you have a no-args constructor, you're free to define other constructors taking multiple properties if you want to support programmatic construction in a single line of code.
Note that the JavaBean properties are not declared on the business interface callers will work with. They're an implementation detail. We can easily "plug in" different implementing classes that have different bean properties without affecting connected objects or calling code.
Of course Spring bean factories have many more capabilities than described here, but this should give you a feel for the basic approach. As well as simple properties, and properties for which you have a JavaBeans PropertyEditor, Spring can handle lists, maps and java.util.Properties. Other advanced container capabilities include:
- Inner beans, in which a property element contains an anonymous bean definition not visible at top-level scope
- Post processors: special bean definitions that customize container runtime behavior. These are simple to implement and provide an easy way of extending what Spring does out of the box.
- Method Injection, a form of IoC in which the container implements an abstract method or overrides a concrete method to inject a dependency. This is a more rarely used form of Dependency Injection than Setter or Constructor Injection. However, it can be useful to avoid an explicit container dependency when looking up a new object instance for each invocation, or to allow configuration to vary over time--for example, with the method implementation being backed by a SQL query in one environment and a file system read in another.
Bean factories and application contexts are often associated with a scope defined by an application server or web container, such as:
- A Servlet context. In the Spring MVC framework, an application context is defined for each web application containing common objects. Spring provides the ability to instantiate such a context through a listener or Servlet without dependence on the Spring MVC framework, so it can also be used in Struts, WebWork or other web frameworks.
- A Servlet: Each controller Servlet in the Spring MVC framework has its own application context, derived from the root (application-wide) application context. It's also easy to accomplish this with Struts or another MVC framework.
These hooks provided by the Java EE specifications generally avoid the need to use a Singleton to bootstrap a bean factory.
However, Spring can be used standalone, and it's trivial to instantiate a BeanFactory programmatically. For example, we could create the bean factory and get a reference to the business object defined above in the following two statements:
XmlBeanFactory bf = new XmlBeanFactory( new ClassPathResource("myFile.xml", getClass())); MyBusinessObject mbo = (MyBusinessObject) bf.getBean("exampleBusinessObject");
This code will work outside an application server: it doesn't even depend on Java EE, as the Spring IoC container is pure Java. The Spring Rich Client project (a framework for simplifying the development of Swing applications using Spring) demonstrates how Spring can be used outside a Java EE environment, as do Spring's integration testing features, discussed later in this article. Dependency Injection and the related functionality are too general and valuable to be confined to a Java EE, or server-side, environment. In fact, most of Spring's core concepts aren't even specific to Java and are also available in .NET environments with Spring.NET (http://www.springframework.net), an application framework for the .NET platform.
Custom XML
Spring's XML configuration syntax is highly customizable. The spring-beans schema (http://www.springframework.org/schema/beans/spring-beans-2.5.xsd) is the most basic syntax and has traditionally been the most widely used. However, there are several common application artifacts whose configurations are largely identical, like JNDI object lookups. In these cases, Spring provides XML configuration extensions to enable essentially a domain-specific language (DSL) for configuration. This both reduces the amount of configuration and makes its intent much clearer.
Let's take a look at an example of configuring a DataSource obtained via JNDI lookup. Using the generic spring-beans schema, the bean declaration is as follows:
<bean id="dataSource" class="org.springframework.jndi.JndiObjectFactoryBean"> <property name="jndiName" value="jdbc/jpetsore" /> </bean>
While this is much better than the Service Locator pattern, it still requires the user to know the name of the Spring class used for JNDI object lookups as well as its required properties. Further, this bean definition will be largely the same for all JNDI lookups, regardless of the type of the stored JNDI object.
One of the custom XML configuration extensions Spring provides out of the box is bound to the "jee" namespace, which allows us to express common tasks like JNDI lookups much more concisely:
<jee:jndi-lookup id="dataSource" jndi-name="jdbc/jpetstore"/>
As you can see, the number of lines of configuration is less, there is less prior framework knowledge required, and the intent of the declaration is much clearer. Given that each of these XML configuration extensions is backed by an XML schema, modern IDEs with XML completion support make it immediately evident which attributes and elements are required versus optional.
Spring provides several namespaces out of the box including "jee" for Java EE-related configuration, "aop" for aspect-oriented configuration, and "tx" for transaction-related configuration. As mentioned previously, however, this is extensible; developers can define their own XML schemas to provide their own configuration DSLs. The XML configuration extensions that Spring provides out of the box are based on the same extension mechanism that developers can use themselves, and so provide good examples.
By providing a custom XML schema, an implementation of Spring's NamespaceHandler interface, and some simple Spring configuration in the form of two Java properties files (to register the custom namespace), Spring allows developers to create their own configuration DSLs that can create a single bean or any number of beans. Let's look at a simple example that will create a java.text.SimpleDateFormat bean.
The XML schema, provided by the developer, defines the structure of the custom XML configuration elements that are to be supported. Here it is for our example:
<xsd:schema xmlns="http://www.mycompany.com/schema/myns" xmlns:xsd="https://www.w3.org/2001/XMLSchema" xmlns:beans="http://www.springframework.org/schema/beans" targetNamespace="http://www.mycompany.com/schema/myns" elementFormDefault="qualified" attributeFormDefault="unqualified"> <xsd:import namespace="http://www.springframework.org/schema/beans"/> <xsd:element name="dateformat"> <xsd:complexType> <xsd:complexContent> <xsd:extension base="beans:identifiedType"> <xsd:attribute name="lenient" type="xsd:boolean"/> <xsd:attribute name="pattern" type="xsd:string" use="required"/> </xsd:extension> </xsd:complexContent> </xsd:complexType> </xsd:element> </xsd:schema>
This is regular XML schema usage, serving to define the grammar for the custom element or elements.
Note the use of a convenient Spring base type called identifiedType (in bold) which means simply that the element will have an id attribute that will be used as the bean identifier in the container. This schema will allow us to use the following XML element in our Spring configuration:
<myns:dateformat id="dateFormat" pattern="yyyy-MM-dd HH:mm" lenient="true"/>
Remember, we're only defining a shorter, more intention-revealing way of declaring a bean (or set of beans). We could still define this particular bean using conventional <bean> elements thus:
<bean id="dateFormat" class="java.text.SimpleDateFormat"> <constructor-arg value="yyyy-HH-dd HH:mm"/> <property name="lenient" value="true"/> </bean>
The difference is that the former is clearer and more intuitive to use than the latter, especially when using schema-aware editors. Now that our schema is done, let's take a look at implementing the NamespaceHandler interface.
The NamespaceHandler interface, implemented by the developer for each custom XML namespace, has just three methods.
- init(), which allows for initialization of the NamespaceHandler and will be called by Spring before the handler is used.
- BeanDefinition parse(Element, ParserContext), which is called when Spring encounters a top-level element (not nested inside a bean definition or a different namespace). This method can register bean definitions itself and/or return a bean definition.
- BeanDefinitionHolder decorate(Node, BeanDefinitionHolder, ParserContext), which is called when Spring encounters an attribute or nested element of a different namespace.
Often a custom namespace element will generate a single bean definition. In this simple case, the developer can simply subclass AbstractSingleBeanDefinitionParser and override two methods, getBeanClass(Element) and doParse(Element, BeanDefinitionBuilder) to provide the custom behavior. Here is how we would implement the example:
public class SimpleDateFormatBeanDefinitionParser extends AbstractSingleBeanDefinitionParser { protected Class getBeanClass(Element element) { return SimpleDateFormat.class; } protected void doParse( Element element, BeanDefinitionBuilder bean) { // never null since the schema requires a value String pattern = element.getAttribute("pattern"); bean.addConstructorArg(pattern); // this is an optional property String lenient = element.getAttribute("lenient"); if (StringUtils.hasText(lenient)) { bean.addPropertyValue("lenient", Boolean.valueOf(lenient)); } } }
That's all. The creation of our single BeanDefinition is handled by the AbstractSingleBeanDefinitionParser superclass, as is the extraction and setting of the bean definition's unique identifier.
Lastly, the namespace handler must be registered so that Spring knows about it while it's parsing the XML configuration. This is done by simply adding two Java properties files to the classpath, either in your application's jar or elsewhere. The first, called META-INF/spring.handlers, maps XML namespace URIs to namespace handler classes. The first part (the key) of each key-value pair is the URI associated with your custom namespace extension, and needs to match exactly the value of the 'targetNamespace' attribute as specified in your custom XSD schema:
# file META-INF/spring.handlers http://www.mycompany.com/schema/myns=org.springframework.samples.xml.MyNamespaceHandler
Note that the colon character (':') is a valid delimiter in the Java properties format, and so needs to be escaped with a backslash.
The second Java properties file that needs to be added is called META-INF/spring.schemas, and it maps the XML namespace URI to the actual schema document, which must be placed on the classpath, again either in your application's jar or elsewhere. In our example, it would look thus:
# file META-INF/spring.schemas http://www.mycompany.com/schema/myns/myns.xsd=org/springframework/samples/xml/myns.xsd
At this point, we've enabled our own application-specific syntax that makes it easier and clearer to express what would otherwise be much more verbose.
Spring’s generic configuration serves most needs out of the box. Define your own custom namespaces only when one or more of the following applies:
- You are defining beans of the same class repeatedly, and they typically have the same properties set each time.
- A group of beans must be defined together to work correctly, and hence configuration is naturally at a higher level of abstraction than bean by bean.
- You want to create a configuration DSL that will be reused widely across a project or company.
- You want the contribution of additional bean definitions to be conditional on existing bean definitions. A <bean> element defines exactly one bean definition; a NamespaceHandler can define zero or more bean definitions.
- You want to create an abstraction between configuration file and implementing class. A custom namespace conceals the class names of bean definitions, so if these change, configuration will not be broken. It is also possible to generate different class names in different runtime environments.
Beyond XML
Spring aims to provide the ultimate configuration solution. Thus configuration does not need to be expressed in XML; Spring has its own powerful internal metadata format that is decoupled from any particular representation.
Since Spring 2.5, you can use Spring annotations or Java common annotations, defined by JSR-250 to configure your beans. By simply including a <context:annotation-config/> element in your application context's configuration, you can use these annotations not only on your property setter methods, but also on constructors, fields, and arbitrary methods and method parameters.
Here's an example using Spring's @Autowired annotation to configure a service bean that depends on a repository:
// In file OrderServiceImpl.java: public class OrderServiceImpl implements OrderService { private OrderRepository orderRepository; @Autowired public JdbcOrderServiceImpl(OrderRepository orderRepo) { this.orderRepository = orderRepo; } // ... } // In file JdbcOrderRepositoryImpl.java: public class JdbcOrderRepositoryImpl implements OrderRepository { @Autowired @Qualifier("myDataSource") private DataSource orderDataSource; // ... }
In the first class above, OrderServiceImpl, the @Autowired annotation indicates to Spring that this dependency should be injected by type via the constructor. In class JdbcOrderRepositoryImpl, the DataSource is injected by name; that is, as there may be multiple resources of type DataSource, the one with the bean name "myDataSource" will be the one provided.
In order to use JSR-250 common annotations in the example, simply replace @Autowired annotations with their @Resource equivalents:
// In file JdbcOrderRepositoryImpl.java: public class JdbcOrderRepositoryImpl implements OrderRepository { @Resource(name="myDataSource") private DataSource orderDataSource; // ... }
@Resource always takes a value, and by default Spring will interpret that value as the bean name to be autowired. In other words, it follows by name semantics. The name provided with the annotation will be resolved as a bean name by the BeanFactory of which the CommonAnnotationBeanPostProcessor is aware. The names may be resolved via JNDI if Spring's SimpleJndiBeanFactory is configured explicitly; however, we recommend relying on the default behavior and simply using Spring's JNDI lookup capabilities to preserve the level of indirection. Thus, in the above example, the DataSource will be provided via a regular ApplicationContext lookup according to the name provided.
The @Autowired annotation can also be applied to arbitrary methods with any number of parameters, and Spring will treat such a method in a manner similar to constructor injection, supplying beans that match the method's parameters by type, and possibly by name via the @Qualifier annotation. For example:
public class JdbcOrderRepositoryImpl implements OrderRepository { @Autowired public void init( @Qualifier("myDataSource") orderDataSource, @Qualifier("otherDataSource") inventoryDataSource, MyHelper autowiredByType) { // ... }
The method name is not significant. Multiple methods can be used in the one class (with the order of calling not guaranteed). “Qualifiers” can be associated with bean definitions like this:
<bean id="myDataSource" class="..."> <qualifier value="order"/> </bean> <bean id="otherDataSource" class="..."> <qualifier value="inventory"/> </bean>
Guice-style resolution by annotation is also fully supported, as in the following example:
public class JdbcOrderRepositoryImpl implements OrderRepository { @Autowired public void setOrderServices( @Emea OrderService emea, @Apac OrderService apac) { // ... }
The annotations are associated with specific bean definitions through adding annotation qualifiers in the bean definitions, or through the use of the annotation on the target type itself.
This approach can lead to a profusion of annotation definitions, which are relatively verbose. However, it may be useful in some scenarios. Spring aims to provide a single container implementation that allows for any style of configuration (or a mix of styles) that the programmer prefers.
While this use of annotation-based autowiring is effective in reducing the amount of XML configuration, it still requires that each candidate bean be defined explicitly. To further reduce the required amount of XML configuration, you can make use of Spring's support for classpath scanning as a means to identify candidate beans. Spring provides @Component and @Repository "stereotyping" annotations that you can place on your candidate bean classes. By using the <context:component-scan base-package="…"> configuration element, you tell Spring to automatically scan for and load as beans those classes in a given base package or its subpackages. This way, you won't have to declare each bean in your configuration – they will automatically be detected:
package org.example.movies; @Repository public class JpaMovieFinder implements MovieFinder { // ... } <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-2.5.xsd" > <context:component-scan base-package="org.example"/> </beans>
You can filter candidate class scanning at a more detailed level. The types of filter expressions that Spring supports include named annotations, classes that can be assigned to particular interfaces or superclasses, regular expressions, and AspectJ pointcut expressions. Further, you can specify including patterns, excluding patterns, or both.
For example, in a test environment, the following configuration tells Spring to scan the classpath for any stub repositories in org.example and its subpackages, ignoring any classes found therein annotated with @Repository:
<beans ...> <context:component-scan base-package="org.example"> <context:include-filter type="regex" expression=".*Stub.*Repository"/> <context:exclude-filter type="annotation" expression="org.springframework.stereotype.Repository"/> </context:component-scan>
Annotations and classpath scanning make for an effective way to eliminate substantial XML configuration.
As a developer, Spring allows you the choice of the perfect configuration option for each task – notably:
- Annotations in Java code, when you don’t anticipate wiring changing frequently
- XML configuration files, when wiring is likely to change without recompilation, or you want to use the power of custom namespaces
- Properties files, to move simple configuration properties into the simplest possible format.
Don’t forget that you can also use the new operator to create objects in Java code: just because you have an IoC container doesn’t mean that the new operator no longer works!
JDBC abstraction and data access exception hierarchy
Data access is another area in which Spring shines.
JDBC offers fairly good abstraction from the underlying database, but is a painful API to use. Some of the problems include:
- The need for verbose error handling to ensure that ResultSets, Statements and (most importantly) Connections are closed after use. This means that correct use of JDBC can quickly result in a lot of code. It's also a common source of errors. Connection leaks can quickly bring applications down under load.
- The relatively uninformative SQLException. Traditionally JDBC does not offer an exception hierarchy, but throws an SQLException in response to all errors. Finding out what actually went wrong - for example, was the problem a deadlock or invalid SQL? - involves examining the SQLState value and error code. The meaning of these values varies between databases.
Spring addresses these problems in two ways:
- By providing APIs that move tedious and error-prone exception handling out of application code into the framework. The framework takes care of all exception handling; application code can concentrate on issuing the appropriate SQL and extracting results.
- By providing a meaningful exception hierarchy for your application code to work with in place of SQLException. When Spring first obtains a connection from a DataSource it examines the metadata to determine the database product. It uses this knowledge to map SQLExceptions to the correct exception in its own hierarchy descended from org.springframework.dao.DataAccessException. Thus your code can work with meaningful exceptions, and need not worry about proprietary SQLState or error codes. Spring's data access exceptions are not JDBC-specific, so your DAOs are not necessarily tied to JDBC because of the exceptions they may throw.
The following UML class diagram illustrates a part of this data access exception hierarchy, indicating its sophistication. Note that none of the exceptions shown here is JDBC-specific. There are JDBC-specific subclasses of some of these exceptions, but calling code is generally abstracted wholly away from dependence on JDBC: an essential if you wish to use truly API-agnostic DAO interfaces to hide your persistence strategy.
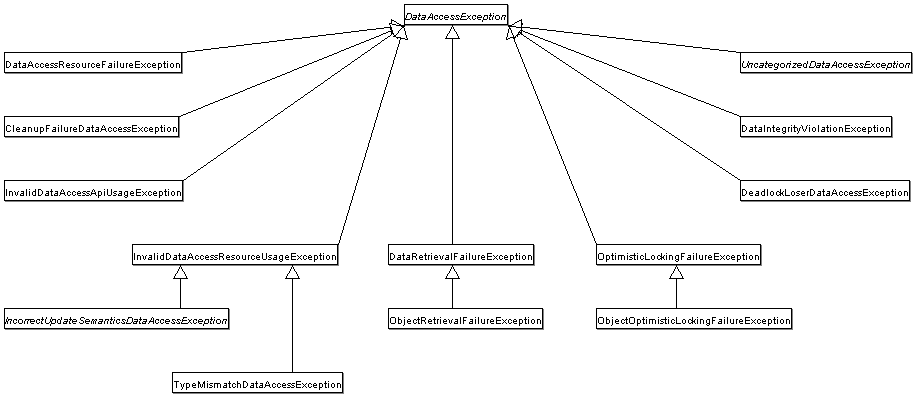
|
The Spring JDBC core org.springframework.jdbc.core package uses callbacks to move control - and hence error handling and connection acquisition and release - from application code to inside the framework. This is a different type of Inversion of Control, but equally valuable to that used for configuration management.
Spring uses a similar callback approach to address several other APIs that involve special steps to acquire and cleanup resources, such as JDO (acquiring and relinquishing a PersistenceManager), JPA (same but for EntityManager), transaction management (using JTA) and JNDI. Spring classes that perform such callbacks are called templates.
For example, the Spring SimpleJdbcTemplate object can be used to perform a SQL query and save the results in a list as follows:
SimpleJdbcTemplate template = new SimpleJdbcTemplate(dataSource); Listnames = template.query("SELECT USER.NAME FROM USER", new ParameterizedRowMapper () { public String mapRow(ResultSet rs, int rowNum) throws SQLException; return rs.getString(1); } });
The mapRow callback method will be invoked for each row of the ResultSet.
Application code within the callback is free to throw SQLException: Spring will catch any exceptions and rethrow them in its own hierarchy. The application developer can choose which exceptions, if any, to catch and handle.
The SimpleJdbcTemplate provides many methods to support different scenarios including prepared statements and batch updates. Simple tasks like running SQL functions can be accomplished without a callback, as follows. The example also illustrates the use of bind variables:
int youngUserCount = template.queryForInt("SELECT COUNT(0) FROM USER WHERE USER.AGE < ?", 25);
The Spring JDBC abstraction has a very low performance overhead beyond standard JDBC, even when working with huge result sets. (In one project in 2004, we profiled the performance of a financial application performing up to 1.2 million inserts per transaction. The overhead of Spring JDBC was minimal, and the use of Spring facilitated the tuning of batch sizes and other parameters. This application now powers all interbank transfers in the world’s fourth largest economy.)
The org.springframework.jdbc.object package contains the StoredProcedure class. By extending this class, Spring enables a stored procedure to be proxied by a Java class with a single business method. If you like, you can even define an interface that the stored procedure implements, meaning that you can free your application code from depending on the use of a stored procedure at all.
For example, if there were a stored procedure called "AllTitles" in a movie database to get all of the titles currently available, we would create a StoredProcedure subclass that implements an application-specific interface for use by clients.
public class AllTitleSproc extends StoredProcedure implements AllTitleLister { private static final String STORED_PROCEDURE_NAME = "AllTitles"; private static final String RESULT_SET_NAME = "titles"; public AllTitleSproc(DataSource dataSource) { setDataSource(dataSource); setSql(STORED_PROCEDURE_NAME); declareParameter( new SqlReturnResultSet( RESULT_SET_NAME, new TitleMapper())); compile(); } public List<Title> listAllTitles() { Map result = execute(new HashMap()); // no input params return (List<Title>) result.get(RESULT_SET_NAME); } private static class TitleMapper implements ParameterizedRowMapper<Title> { public Title mapRow(ResultSet resultSet, int i) throws SQLException { Title t = new Title(resultSet.getLong(1)); t.setName(resultSet.getString(2)); return t; } } }
Notice first that we can achieve portability with stored procedures across databases; all that is required is that the stored procedure name be the same (although we could make this configurable if we wanted in order to further increase portability). Second, notice that the class AllTitleSproc implements an application-specific interface, AllTitleLister:
public interface AllTitleLister { List<Title> listAllTitles(); }
This allows code that uses this functionality to be completely independent of how movie titles are obtained:
public class AllTitleListerClient { private AllTitleLister allTitleLister; public void setAllTitleLister(AllTitleLister allTitleLister) { this.allTitleLister = allTitleLister; } public void useLister() { List<Title> titles = allTitleLister.listAllTitles(); for (Title t : titles) { System.out.println(t.getId() + ":" + t.getName()); } }
Since the allTitleLister property is provided via dependency injection, this client code only depends upon the interface and none of its implementation details.
The Spring data access exception hierarchy is based on unchecked (runtime) exceptions. Although controversial at first, time has shown that this was the right decision.
Data access exceptions not usually recoverable. For example, if we can't connect to the database, a particular business object is unlikely to be able to work around the problem. One potential exception is optimistic locking violations, but not all applications use optimistic locking. It's usually bad to be forced to write code to catch fatal exceptions that can't be sensibly handled. Letting them propagate to a top-level handler like a Servlet container is usually more appropriate. All Spring data access exceptions are subclasses of DataAccessException, so if we do choose to catch all Spring data access exceptions, we can easily do so.
If we do want to recover from an unchecked data access exception, we can still do so. We can write code to handle only the recoverable condition. For example, if we consider that only an optimistic locking violation is recoverable, we can write code in a Spring DAO as follows:
try { // do work } catch (OptimisticLockingFailureException ex) { // I'm interested in this }
If Spring data access exceptions were checked, we'd need to write the following code. Note that we could choose to write this anyway:
try { // do work } catch (OptimisticLockingFailureException ex) { // I'm interested in this } catch (DataAccessException ex) { // Fatal; just rethrow it }
One potential objection to the first example - that the compiler can't enforce handling the potentially recoverable exception - applies also to the second. Because we're forced to catch the base exception ( DataAccessException), the compiler won't enforce a check for a subclass ( OptimisticLockingFailureException). So the compiler would force us to write code to handle an unrecoverable problem, but provide no help in forcing us to deal with the recoverable problem.
Spring's use of unchecked data access exceptions is consistent with that of many - probably most - successful persistence frameworks. (Indeed, it was partly inspired by JDO, and has in turn influenced several other products.) JDBC is one of the few data access APIs to use checked exceptions. TopLink and JDO, for example, use unchecked exceptions exclusively. Hibernate switched from checked to unchecked exceptions in version 3.
Spring JDBC can help you in several ways:
- You'll never need to write a finally block again to use JDBC
- Connection leaks will be a thing of the past
- You'll need to write less code overall, and that code will be clearly focused on the necessary SQL
- You'll never need to dig through your RDBMS documentation to work out what obscure error code it returns for a bad column name. Your application won't be dependent on RDBMS-specific error handling code.
- Whatever persistence technology use, you'll find it easy to implement the DAO pattern without business logic depending on any particular data access API.
- You'll benefit from improved portability (compared to raw JDBC) in advanced areas such as BLOB handling and invoking stored procedures that return result sets.
All this amounts to substantial productivity gains and fewer bugs. I used to loathe writing JDBC code; now I find that I can focus on the SQL I want to execute, rather than the incidentals of JDBC resource management.
Spring's JDBC abstraction can be used standalone if desired - you are not forced to use the other parts of Spring.
O/R mapping integration
Of course often you want to use O/R mapping (ORM), rather than use relational data access. Your overall application framework must support this also. Thus, Spring integrates out of the box with the JPA 1 and JDO 1 and 2 specifications, as well as Hibernate (versions 2 and 3), TopLink, iBatis and other ORM products. Its data access architecture allows it to integrate with any underlying data access technology.
Why would you use an ORM product plus Spring, instead of the ORM product directly? Spring adds significant value in the following areas:
- Session management. Spring offers efficient, easy, and safe handling of units of work such as JPA EntityManagers, in any runtime environment. Related code using the ORM tool alone generally needs to use the same EntityManager for efficiency and proper transaction handling. Spring can transparently create and bind one to the current thread, using either a declarative, AOP method interceptor approach, or by using an explicit, "template" wrapper class at the Java code level. Thus Spring solves many of the usage issues that affect many users of ORM technology.
- Resource management. Spring application contexts can handle the location and configuration of JPA EntityManagerFactories, JDBC datasources, and other related resources. This makes these values easy to manage and change.
- Integrated transaction management. Spring allows you to wrap your ORM code with either a declarative, AOP method interceptor, or an explicit 'template' wrapper class at the Java code level. In either case, transaction semantics are handled for you, and proper transaction handling (rollback, etc.) in case of exceptions is taken care of. As we discuss later, you also get the benefit of being able to use and swap various transaction managers, without your ORM-related code being affected. As an added benefit, JDBC-related code can fully integrate transactionally with ORM code, in the case of most supported ORM tools. This is useful for handling functionality not amenable to ORM.
- Exception wrapping, as described above. Spring can wrap exceptions from the ORM layer, converting them from proprietary (possibly checked) exceptions, to a set of abstracted runtime exceptions. This allows you to handle most persistence exceptions, which are non-recoverable, only in the appropriate layers, without annoying boilerplate catch-throw blocks and exception declarations. You can still trap and handle exceptions anywhere you need to. Remember that JDBC exceptions (including DB specific dialects) are also converted to the same hierarchy, meaning that you can perform some operations with JDBC within a consistent programming model.
- To avoid vendor lock-in. ORM solutions have different performance and other characteristics, and there is no perfect one size fits all solution. Alternatively, you may find that certain functionality is just not suited to an implementation using your ORM tool. Thus it makes sense to decouple your architecture from the tool-specific implementations of your data access object interfaces. If you ever need to switch to another implementation for reasons of functionality, performance, or any other concerns, using Spring now can make the eventual switch much easier. Spring's abstraction of your ORM tool's Transactions and Exceptions, along with its IoC approach which allow you to easily swap in mapper/DAO objects implementing data-access functionality, make it easy to isolate all ORM-specific code in one area of your application, without sacrificing any of the power of your ORM tool. The PetClinic sample application shipped with Spring demonstrates the portability benefits that Spring offers by providing variants that use JDBC, Hibernate, TopLink and Apache OJB to implement the persistence layer.
- Ease of testing. Spring's inversion of control approach makes it easy to swap the implementations and locations of resources such as JPA EntityManagerFactories, datasources, transaction managers, and mapper object implementations (if needed). This makes it much easier to isolate and test each piece of persistence-related code in isolation.
Above all, Spring facilitates a mix-and-match approach to data access. ORM is not the solution to all problems, although it is a valuable productivity win in many cases. Spring enables a consistent architecture, and transaction strategy, even if you mix and match persistence approaches, with or without JTA.
In cases where ORM is not ideally suited, Spring's simplified JDBC is not the only option: the "mapped statement" approach provided by iBATIS SQL Maps is worth a look. It provides a high level of control over SQL, while still automating the creation of mapped objects from query results. Spring integrates with SQL Maps out of the box. Spring's PetStore sample application illustrates iBATIS integration.
Transaction management
Abstracting a data access API is not enough; we also need to consider transaction management. JTA is the obvious solution, but it's a cumbersome API to use directly, and as a result many J2EE developers used to feel that EJB CMT is the only rational option for transaction management. Spring has changed that.
Spring provides its own abstraction for transaction management. Spring uses this to deliver:
- Programmatic transaction management via a callback template analogous to the SimpleJdbcTemplate, which is much easier to use than straight JTA
- Declarative transaction management analogous to EJB CMT, but without the need for an EJB container. Actually, as we'll see, Spring's declarative transaction management capability is a semantically compatible superset of EJB CMT, with some unique and important benefits.
Spring's transaction abstraction is unique in that it's not tied to JTA or any other transaction management technology. Spring uses the concept of a transaction strategy that decouples application code from the underlying transaction infrastructure (such as JDBC). It offers a superset of the capabilities of JTA, supporting simulation of nested transactions using savepoints in savepoint-capable resources, and allowing control over isolation level.
Why should you care about this? Isn't JTA the best answer for all transaction management? If you're writing an application that uses only a single database, you don't need the complexity of JTA. You're not interested in XA transactions or two phase commit. You may not even need a high-end application server that provides these things. But, on the other hand, you don't want to have to rewrite your code should you ever have to work with multiple data sources.
Imagine you decide to avoid the overhead of JTA by using JDBC or JPA EntityTransactions directly. If you ever need to work with multiple data sources, you'll have to rip out all that transaction management code and replace it with JTA transactions. This isn't very attractive and led most authors on Java EE to recommend using global JTA transactions exclusively, effectively ruling out using a web container such as Tomcat for transactional applications. Using the Spring transaction abstraction, however, you only have to reconfigure Spring to use a JTA, rather than JDBC or JPA, transaction strategy and you're done. This is a configuration change, not a code change. Thus, Spring enables you to write applications that can scale down as well as up.
AOP
Among other things, AOP provides a proven, flexible solution to addressing cross-cutting enterprise concerns, such as transaction management, which were traditionally addressed by EJB.
The first goal of Spring's AOP support is to provide J2EE services to POJOs. Spring AOP is portable between application servers, so there's no risk of vendor lock in. It works in either web or EJB containers, and has been used successfully in WebLogic, Tomcat, JBoss, Resin, Jetty, Orion and many other application servers and web containers.
Spring AOP supports method interception. Key AOP concepts supported include:
- Interception: Custom behavior can be inserted before or after method invocations against any interface or class. This equates to “before”, “after” and "around advice" in AspectJ terminology.
- Introduction: Specifying that an advice should cause an object to implement additional interfaces. This can amount to mixin inheritance.
- Static and dynamic pointcuts: Specifying the points in program execution at which interception should take place. Static pointcuts concern method signatures; dynamic pointcuts may also consider method arguments at the point where they are evaluated. Pointcuts can be reused.
Spring implements AOP using dynamic proxies (where an interface exists) or CGLIB byte code generation at runtime (which enables proxying of classes). Both approaches work in any application server, or in a standalone environment.
Spring integrates with AspectJ, providing the ability to seamlessly include AspectJ aspects into Spring applications . Since Spring 1.1 it has been possible to dependency inject AspectJ aspects using the Spring IoC container, just like any Java class. Thus AspectJ aspects can depend on any Spring-managed objects. The integration with the AspectJ 5 is exciting, as AspectJ provides the ability to dependency inject any non Spring-managed POJO using Spring, based on XML or annotation-driven pointcuts.
Since Spring 2.0, Spring can also use the AspectJ pointcut expression language to specify pointcuts or matching rules. This is very beneficial, as AspectJ offers much richer semantics, and greater type safety, than simplistic pure interception solutions. It also means that the same aspects can be written for use in Spring and AspectJ: two different runtime choices--one simple, powerful, programming model.
Because Spring advises objects at instance, rather than class loader, level, it is possible to use multiple instances of the same class with different advice, or use unadvised instances along with advised instances.
Perhaps the commonest use of Spring AOP is for declarative transaction management. This builds on the transaction abstraction described above, and can deliver declarative transaction management on any POJO. Depending on the transaction strategy, the underlying mechanism can be JTA, JDBC, Hibernate or any other API offering transaction management.
The following are the key differences from EJB CMT:
- Transaction management can be applied to any POJO. We recommend that business objects implement interfaces, but this is a matter of good programming practice, and is not enforced by the framework.
- Programmatic rollback can be achieved within a transactional POJO through using the Spring transaction API. We provide static methods for this, using ThreadLocal variables, so you don't need to propagate a context object such as an EJBContext to ensure rollback.
- You can define rollback rules declaratively. Whereas EJB 2.1 and earlier will not automatically roll back a transaction on an uncaught application exception (only on unchecked exceptions, other types of Throwable and "system" exceptions), application developers often want a transaction to roll back on any exception. Spring transaction management allows you to specify declaratively which exceptions and subclasses should cause automatic rollback—at a per method (or use case) level, rather than the more coarse grained per exception level offered by EJB 3.0. Default behavior is as with EJB, but you can specify automatic rollback on checked, as well as unchecked exceptions. This has the important benefit of minimizing the need for programmatic rollback, which creates a dependence on the Spring transaction API.
- Because the underlying Spring transaction abstraction supports savepoints if they are supported by the underlying transaction infrastructure, Spring's declarative transaction management can support nested transactions, in addition to the propagation modes specified by EJB CMT (which Spring supports with identical semantics). Thus, for example, if you are performing JDBC operations on Oracle, you can use declarative nested transactions using Spring.
- Transaction management is not tied to JTA. As explained above, Spring transaction management can work with different transaction strategies.
It's also possible to use Spring AOP to implement application-specific aspects. Whether or not you choose to do this depends on your level of comfort with AOP concepts, rather than Spring's capabilities, but it can be very useful. Successful examples we've seen include:
- Custom security checks, where the complexity of security checks required is beyond the capability of the standard JEE security infrastructure. Of course, before rolling your own security infrastructure, you should check the capabilities of Spring Security (formerly Acegi Security for Spring), a powerful, flexible security framework that integrates with Spring using AOP, and reflects Spring's architectural approach.
- Debugging and profiling aspects for use during development
- Aspects that apply consistent exception handling policies in a single place
- Interceptors that send emails to alert administrators or users of unusual scenarios
Application-specific aspects can be a powerful way of removing the need for boilerplate code across many methods.
Spring AOP integrates transparently with the Spring IoC container. Code obtaining an object from a Spring BeanFactory doesn't need to know whether or not it is “advised”—that is, whether any aspects apply to it (or “advise” it). As with any object, the contract will be defined by the interfaces the object implements.
Performance monitoring, auditing or tracing is one of the many areas where Spring AOP can be used along with AspectJ 5's pointcut expression language. To monitor invocations of service methods, we can use the following style of configuration:
<bean id="performanceMonitor" class="com.example.PerformanceMonitor"/> <aop:config> <aop:aspect ref="performanceMonitor"> <aop:around pointcut="execution(public * com.example.Service+.*(..))" method="monitor" /> </aop:aspect> </aop:config>
The above declaration causes the POJO class com.example.PerformanceMonitor's "monitor" method to be called wherever any public method in the class com.example.Service or its subclasses would have been called. The monitor method can start a timer, allow execution to proceed as normally (via proceed() on org.aspectj.lang.ProceedingJoinPoint), then stop the timer after proceed() returns, record the time taken, then return the proxied method's return value:
public Object monitor(ProceedingJoinPoint pjp) throws Throwable { long start = System.nanoTime(); try { return pjp.proceed(); } finally { long time = System.nanoTime() - start; // do something with time... } }
We can also use the “@AspectJ “ style of programming introduced in AspectJ 5, where the annotation is included in the aspect class itself, as follows, This is appropriate and elegant when the matching rule (or pointcut) is closely linked to the aspect implementation:
@Around("execution(public * com.example.Service+.*(..))") public Object monitor(ProceedingJoinPoint pjp) throws Throwable { long start = System.nanoTime(); try { return pjp.proceed(); } finally { long time = System.nanoTime() - start; // do something with time... } }
Automatic application of such aspects (when defined as Spring beans) is enabled through the following XML tag:
<aop:aspectj-autoproxy />
There are a number of ways to set up proxying concisely, if you don't need the full power of the AOP framework, such as using Java 5.0 annotations to drive transactional proxying without XML metadata.
The following example illustrates the simplest way to use Spring AOP to perform transaction management for a POJO. First, define a business interface:
public interface AccountService { Account createAccount(String name); }
The transaction management-related portion of the Spring configuration is now reduced to the following (assuming JPA is used with DataSource "myDataSource"):
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager"> p:dataSource-ref="myDataSource"/> <tx:annotation-driven/>
Given the above example, any invocations to the service's "createAccount" method will actually be on a Spring transaction manager that implements the AccountService interface. The proxy will begin or join a transaction (since the default transaction propagation setting is REQUIRED), will allow execution to proceed through the JpaAccountServiceImpl's "createAccount" method implementation, and the transaction will commit or rollback appropriately based on the exit of the method. The @Transactional attribute can be used on types or methods.
Spring also automatically supports EJB’s @TransactionAttribute: however, note that the semantics of this are less rich than @Transactional.
While it's also possible to construct AOP proxies programmatically without using a BeanFactory, although this is more rarely used. We believe that it's generally best to externalize the wiring of applications from Java code, and AOP is no exception.
MVC web framework
Spring includes a powerful and highly configurable MVC web framework.
Spring's MVC model is most similar to that of Struts, although it is not derived from Struts. A Spring Controller is similar to a Struts Action in that it is a multithreaded service object, with a single instance executing on behalf of all clients. However, we believe that Spring MVC has some significant advantages over Struts. For example:
- Spring provides a clean division between controllers, JavaBean models, and views.
- Spring's MVC is very flexible. Unlike Struts, which forces your Action and Form objects into concrete inheritance (thus taking away your single shot at concrete inheritance in Java), Spring MVC is entirely based on interfaces. Furthermore, just about every part of the Spring MVC framework is configurable via plugging in your own interface. Of course we also provide convenience classes as an implementation option.
- Spring provides interceptors as well as controllers, making it easy to factor out behavior common to the handling of many requests.
- Spring MVC is truly view-agnostic. You don't get pushed to use JSP if you don't want to; you can use Velocity, XLST or other view technologies. If you want to use a custom view mechanism - for example, your own templating language - you can easily implement the Spring View interface to integrate it.
- Spring Controllers are configured via IoC like any other objects. This makes them easy to test, and beautifully integrated with other objects managed by Spring.
- Spring MVC web tiers are typically easier to test than Struts web tiers, due to the avoidance of forced concrete inheritance and explicit dependence of controllers on the dispatcher servlet.
- The web tier becomes a thin layer on top of a business object layer. This encourages good practice. Struts and other dedicated web frameworks leave you on your own in implementing your business objects; Spring provides an integrated framework for all tiers of your application.
As in Struts 1.1 and above, you can have as many dispatcher servlets as you need in a Spring MVC application.
The following example shows how a simple Spring Controller can access business objects defined in the same application context. This controller looks up an Order and returns it in its handleRequest() method:
public class OrderController implements Controller { private OrderRepository repo; @Autowired public OrderController(OrderRepository orderRepository) { repo = orderRepository; } public ModelAndView handleRequest( HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { String id = request.getParameter("id"); Order order = repo.getOrderById(id); return new ModelAndView("orderView", "order", order); } }
Spring IoC isolates this controller from the underlying OrderRepository; it could be based on JDBC just as much as it could be a web service. The interface could equally be implemented by a plain Java object, test stub, mock object, or proxy to a remote object. This controller contains no resource lookup; nothing except code necessary to support its web interaction.
Spring MVC also provides support for data binding, forms, wizards and more complex workflow. However, if you require sophisticated conversation management, you should consider Spring Web Flow, a powerful framework that provides a higher level of abstraction for web flows than any traditional web MVC framework.
A good introduction to the Spring MVC framework is Thomas Risberg's Spring MVC tutorial (http://www.springframework.org/docs/MVC-step-by-step/Spring-MVC-step-by-step.html). See also "Web MVC with the Spring Framework" (http://www.springframework.org/docs/web_mvc.html).
If you're happy with your favorite web framework, Spring's layered infrastructure allows you to use the rest of Spring without our MVC layer. We have Spring users who use Spring for middle tier management and data access but use Struts, WebWork, Tapestry or JSF in the web tier.
Testing
As you've probably gathered, I and the other Spring developers are firm believers in the importance of comprehensive unit and integration testing. We believe that it's essential that frameworks are thoroughly unit tested, and that a prime goal of framework design should be to make applications built on the framework easy to unit test.
Spring itself has an excellent unit test suite. We've found the benefits of test first development to be very real on this project. For example, it has made working as an internationally distributed team extremely efficient, and users comment that CVS snapshots tend to be stable and safe to use.
Applications built on Spring are very easy to test, for the following reasons:
- IoC facilitates unit testing
- Applications don't contain plumbing code directly using Java EE services such as JNDI, which is typically hard to test
- Spring bean factories or contexts can be set up outside a container
The ability to set up a Spring bean factory outside a container offers interesting options for the development process. Work can begin by defining business interfaces and integration testing their implementation outside a web container. Only after business functionality is substantially complete is a thin layer added to provide a web interface.
Spring provides powerful and unique support for a form of integration testing outside the deployed environment. This is not intended as a substitute for unit testing or testing against the deployed environment. However, it can significantly improve productivity.
The Spring Framework provides first class support for integration testing in the form of the classes packaged in the spring-test.jar library. In this library, you will find the org.springframework.test package which contains valuable classes for integration testing using a Spring container, which do not require an application server or other deployment environment. Such tests can run in JUnit or TestNG – even in an IDE – without any special deployment step. They will be slower to run than unit tests but much faster to run than the equivalent Cactus tests or remote tests relying on deployment to an application server. Typically it is possible to run hundreds of tests hitting a development database – usually not an embedded database, but the product used in production – within seconds, rather than minutes or hours. Such tests can very quickly verify correct wiring of your Spring contexts, and data access using JDBC or ORM tool, such as correctness of SQL statements. For example, you can test your DAO implementation classes.
Prior to the 2.5 release of the framework, Spring provided integration testing support specific to JUnit 3.8. As of the 2.5 release, Spring offers support for unit and integration testing in the form of the Spring TestContext Framework, which is agnostic of the actual testing framework in use, thus allowing instrumentation of tests in various environments including JUnit 3.8, JUnit 4.4, TestNG, etc. The Spring TestContext Framework requires Java 5 or higher.
The Spring team recommends using the Spring TestContext Framework for all new integration testing involving ApplicationContexts or requiring transactional test fixtures; however, if you are developing in a pre-Java 5 environment, you will need to continue to use the JUnit 3.8 legacy support.
The Spring integration testing support frameworks share several common goals, including:
- The ability to cache container configuration between test cases, which greatly increases performance where slow-to-initialize resources such as JDBC connection pools or Hibernate SessionFactories are concerned.
- The ability to populate test fixture instances via Dependency Injection. This makes it possible to reuse Spring XML configuration when testing and eliminates the need for custom setup code for tests.
- Infrastructure to create a transaction around each test method and roll it back at the conclusion of the test by default. This makes it possible for tests to perform any kind of data access without worrying about the effect on the environments of other tests. In my experience across several complex projects using this functionality, the productivity and speed gain of such a rollback-based approach is very significant.
- Spring-specific support classes that are really useful when writing integration tests.
For details outlining each of these goals, please consult the revised "Testing"
chapter of the Spring reference manual.
For example, in the following revised PetClinic example (which is based on the example included in the Spring distribution in samples/petclinic), we define integration tests in an abstract class that is configured with annotations provided by the Spring TestContext Framework. This class – which is essentially a POJO, thanks to the use of SpringJUnit4ClassRunner – is configured to provide some extremely convenient features, like automatically injecting dependencies, rolling back transactions at the end of each test, and reusing the configuration bootstrapped via Spring during the test setup (thanks to the fact that we're rolling back after each test, restoring the environment to the same initial state).
@RunWith(SpringJUnit4ClassRunner.class) @TestExecutionListeners({ DependencyInjectionTestExecutionListener.class, TransactionalTestExecutionListener.class}) @Transactional @ContextConfiguration( locations={"applicationContext-dataSourceCommon.xml"}) public abstract class AbstractClinicTests { // dependency injected by Spring @Autowired protected Clinic clinic; // test that runs in transactional context with rollback @Test public void testFindOwners() { Collection<?> owners = this.clinic.findOwners("Davis"); assertEquals(2, owners.size()); owners = this.clinic.findOwners("Daviss"); assertEquals(0, owners.size()); } // more tests... }
Now that we've defined our abstract tests, we can simply subclass it for use with specific technologies and run them as simple JUnit 4.4 tests. Here's the first one, using straight JDBC:
@ContextConfiguration(locations={"applicationContext-jdbc.xml"}) public class JdbcClinicTests extends AbstractClinicTests {}
Note that for this example, JdbcClinicTests does not contain a single line of code: we only need to supply the correct locations to @ContextConfiguration, and the tests are inherited from AbstractClinicTests. The relevant portions of the Spring configuration file, applicationContext-jdbc.xml, are shown here (the bean named " dataSource" is defined in applicationContext-dataSourceCommon.xml):
<bean id="transactionManager" class="...jdbc.datasource.DataSourceTransactionManager" p:dataSource-ref="dataSource"/> <bean class="...samples.petclinic.jdbc.HsqlJdbcClinic" p:dataSource-ref="dataSource"/>
All that we need to in this configuration file is define our "transactionManager" bean as a simple Spring DataSourceTransactionManager, our Clinic implementation bean as our own HsqlJdbcClinic, and Spring takes care of the rest. We can simply execute JdbcClinicTests as a regular JUnit 4.4 test class, and Spring will configure our environment, run each test method in its own transaction, and roll back the transaction after each test!
To test a different implementation of Clinic that uses Hibernate, we simply change our configuration to use a HibernateTransactionManager and our own HibernateClinic.
Here is the Hibernate-based JUnit 4.4. test class:
@ContextConfiguration(locations={"applicationContext-hibernate.xml"}) public class HibernateClinicTests extends AbstractClinicTests {}
And the relevant the configuration file " applicationContext-hibernate.xml":
<!-- Hibernate "sessionFactory" bean defined here for use with the HSQL "dataSource" bean and HSQL dialect --> <bean id="transactionManager" class="...orm.hibernate3.HibernateTransactionManager" p:sessionFactory-ref="sessionFactory"/> <bean class="...samples.petclinic.hibernate.HibernateClinic" p:sessionFactory-ref="sessionFactory"/>
The above examples could just as easily have been implemented with JUnit 3.8 or TestNG. The Spring TestContext Framework thus allows developers to leverage the unit testing framework most suitable to their project and team.
As you can see, the benefits of using Spring at testing time are significant.
Who's using Spring?
There are thousands of production applications using Spring. Users include investment and retail banking organizations, well-known dotcoms, global consultancies, academic institutions, government departments, defense contractors, several airlines, and scientific research organizations (including CERN). Some examples:
- Voca, Europe's largest processor of direct debit & credit transactions, uses Spring heavily in a system that processes billions of payments per year. The introduction to Spring helped drive a significant gain in developer productivity, and Spring plays an important role in processing each of over 80 million payment instructions daily. Interface21's expertise was instrumental in the architecture of Voca’s core payment engine.
- eSpaceNet, the European patent office's online patent database, is responsible for managing all patents across the continent of Europe. Spring's web application development solutions have improved productivity, enhanced performance, and reduced maintenance costs.
- Sabre Airlines Solutions, the leading provider of airline information systems, uses Spring throughout their next-generation aircraft control system.
- Accenture, one of the world’s leading SIs, uses Spring extensively in client engagements and best practice solutions. Accenture has also contributed to the Spring Portfolio through collaborating with Interface21 to create the Spring Batch project.
- Nine out of the top 10 global banks use Spring extensively in Java applications. Several have standardized on Spring to structure their applications.
Interestingly, although the first version of this article was published six months before the release of Spring 1.0 final, almost all the code and configuration examples would still work unchanged in today's 2.5 release. We are proud of our excellent record on backward compatibility. This demonstrates the ability of Dependency Injection and AOP to deliver a non-invasive API, and also indicates the seriousness with which we take our responsibility to the community to provide a stable framework to run vital applications.
Summary
Spring is a powerful framework that solves many common problems in enterprise Java. Most Spring features are also usable in a wide range of Java environments, beyond classic Java EE.
Spring provides a consistent way of managing business objects and encourages good practices such as programming to interfaces, rather than classes. The architectural basis of Spring is an Inversion of Control container designed to configure any POJO. However, this is only part of the overall picture: Spring is unique in that it uses its IoC container as the basic building block in a comprehensive solution that addresses all architectural tiers.
Spring provides a unique data access abstraction, including a simple and productive JDBC framework that greatly improves productivity and reduces the likelihood of errors. Spring's data access architecture also integrates with TopLink, Hibernate, JDO, JPA and other O/R mapping solutions.
Spring also provides a unique transaction management abstraction, which enables a consistent programming model over a variety of underlying transaction technologies, such as JTA or JDBC.
Spring provides an AOP framework written in standard Java, which provides declarative transaction management and other enterprise services to be applied to POJOs or - if you wish - the ability to implement your own custom aspects. This framework is powerful enough to enable many applications to dispense with the complexity of EJB, while enjoying key services traditionally associated with EJB.
Spring also provides a powerful and flexible MVC web framework that is integrated into the overall IoC container. Numerous other enterprise services, such as remoting and JMX integration, are offered out of the box, but are beyond the scope of this article.
Spring and Java versions
While many new features (such as annotation-based programming styles) require Java features introduced in version 5.0, as of Spring 2.5, all core functionality is still available in applications using Java 1.4. This is important to users of older application servers, who do not need to upgrade their production environments to take advantage of a productive modern programming model.
New Java 6-specific features include:
- JDBC 4.0: Jdbc4NativeJdbcExtractor, support for extended DataSource interface
- JMX MXBean support: server-side export and client-side proxying of MXBeans
- ServiceLoader API: making services discovered via META-INF/services available for dependency injection
- JAX-WS support: including support for service exposure via the built-in web server in JDK 1.6
The future
One of the key benefits of Dependency Injection is that your code can not merely be configured in an environment it does not depend on explicitly, but can benefit from services that were not envisaged at its time of authoring. Thus Spring offers a flexible component model that can offer a variety of value adds for little or no effort. For example:
- You can “export” any Spring-managed object as a JMX MBean without writing Java code
- Spring Dynamic Modules for OSGi™ Service Platforms allows Spring to take advantage of the powerful modularization capabilities of OSGi, without business objects needing to depend on OSGi APIs or an OSGi runtime.
- Spring’s compatibility with the SCA SOA standard makes Spring managed objects “SCA ready”. SCA specifies a Spring binding for Java.
- Spring integrates with a range of clustering and grid solutions such as GigaSpaces, Oracle Coherence and Terracotta.
- Your code can take advantage of Spring’s rich and deepening range of platform integrations, while remaining free of proprietary extensions. For example, in a WebLogic environment, you gain sophisticated transaction monitoring functionality due to the fact that Spring ties into BEA APIs, without writing a line of WebLogic-specific code in your application.
Spring moves forward rapidly, and development activity is further accelerating, so the range of value adds available continues to grow.
More information
See the following resources for more information about Spring:
- Interface21 offers Spring training courses worldwide - http://www.interface21.com/training.
- Expert One-on-One J2EE Design and Development (Rod Johnson, Wrox, 2002). Although Spring has evolved and improved significantly since the book's publication, it's still an excellent place to go to understand Spring's motivation.
- J2EE without EJB (Rod Johnson with Juergen Hoeller, Wrox, 2004). Sequel to J2EE Design and Development that discusses the rationale for Spring and the lightweight container architecture it enables.
- The Spring Reference Manual. The printable form is over 500 pages as of Spring 2.5. Spring also ships with several sample applications that illustrate best practices and can be used as templates for your own applications.
- Pro Spring: In-depth Spring coverage by core developer Rob Harrop.
- Spring Framework home page: http://www.springframework.org/. This includes Javadoc and several tutorials.
- User forums
- Spring-developer mailing list.
- Interface21 offers production and development support for Spring: http://www.interface21.com/support.
We pride ourselves on excellent response rates and a helpful attitude to queries on the forums and mailing lists. We hope to welcome you into our community soon!
About the Author
Rod Johnson , the founder of Spring, has over ten years experience as a Java developer and architect and has worked with J2EE since the platform emerged. He is the author of the best-selling Expert One-on-One J2EE Design and Development (Wrox, 2002), and J2EE without EJB (Wrox, 2004, with Juergen Hoeller) and has contributed to several other books on J2EE. Rod serves on several Java specification committees including Java EE 6, and is a regular conference speaker. Rod is CEO of Interface21, the company that leads and sustains Spring. Interface21 provides production and development support, training and consultancy for Spring.
Thanks also to Matthew Adams and Sam Brannen of Interface21.
Recommended Books for Learning Spring
Spring in Action ~ Craig Walls
Spring Recipes: A Problem-Solution Approach ~ Gary Mak
Professional Java Development with the Spring Framework ~ Rod Johnson PhD
Pro Java EE Spring Patterns: Best Practices and Design Strategies ~ Dhrubojyoti Kayal






