Simplifying Domain Model Persistence in a J2EE application by using JDO
This article describes how using Java Data Objects (JDO) [JDO] can avoid these problems and accelerate development.
Introduction
Developing a persistent domain model for an enterprise application is challenging. The reason we implement the business logic with a domain model is because the problem domain is complex. Therefore, it is important to be able to easily and quickly make changes and run unit tests. However, quite often the technology that provides persistence can slow down development because it couples the code to the application server and the database. This can significantly lengthen the edit-compile-execute-debug cycle and test-driven development becomes harder to do. This article describes how using Java Data Objects (JDO) [JDO] can avoid these problems and accelerate development.
Persistence technologies that can only be used in the application server slow down development because they require the developer to redeploy components into the application server each time they want to test a change, which can be time consuming. Similarly, persistence technologies that couple the domain model code to the database also slow down development. Each time the developer changes the domain model they must update the database schema and rebuild the database before they can test their changes. Furthermore, tests typically run at least 10x slower when a database is involved. It is also harder to write the test setup and tear down code.
My previous article [RICHARDSON], published on TheServerSide, describes the Two Level Domain Model design strategy that decouples the business logic from the entity beans that provide persistence. It enables a domain model to be tested outside of an EJB container and without a database, which accelerates development. However, several of the comments on the article strongly argued that a simpler and easier approach would be to use Java Data Objects (JDO) [JDO] instead of entity beans. The arguments for using JDO seem compelling. JDO provides transparent persistence for Plain Old Java Objects (POJO) [FOWLER] classes, which means that we can develop and test the domain model without a database. JDO applications can be run outside of an application server, which accelerates the edit-compile-execute cycle by eliminating the time consuming J2EE component deployment step. However, quite often the devil is in the details and so to test these claims I implemented a JDO version of the example application.
This is the first of two articles that describes the issues I encountered when using JDO and how they were resolved. It covers various design topics including designing for testability and is organized as follows:
Section 1 describes the example application and provides an overview of its JDO implementation.
Section 2 describes some object-relational mapping issues with JDO, including object identity and how to persist embedded value objects.
Section 3 describes how to write code that invokes JDO APIs in a way that works both inside and outside an application server.
Section 4 describes how to design the session facade to make testing easier.
NOTE: The accompanying source code for this article can be downloaded at http://www.chrisrichardson.net/jdoExample/index.html
Overview of the Example Application
Since [RICHARDSON] describes the online restaurant delivery service application in detail I will only briefly describe it here. Figure 1 shows the key classes that implement the Process Order use case.
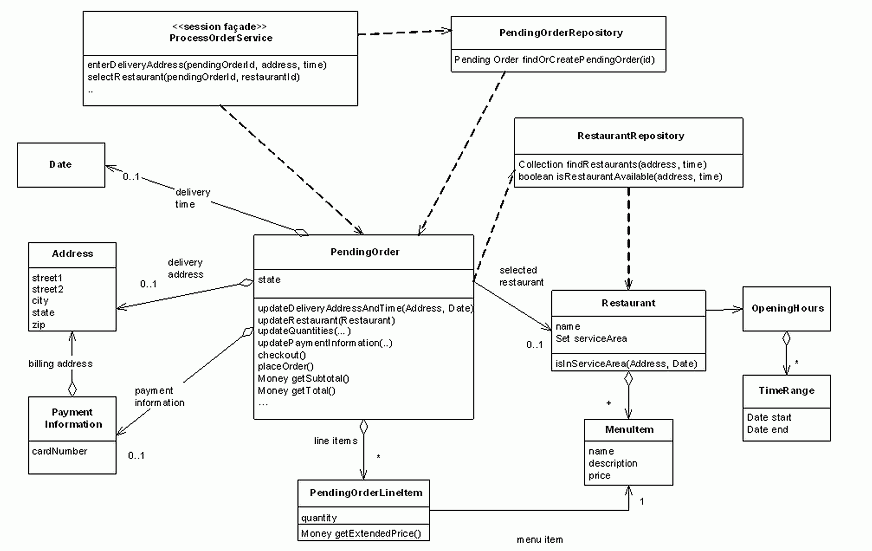
Figure 1 - Session facade and domain model classes
ProcessOrderService is a session facade [EJBPATTERNS] that encapsulates the domain model, which is implemented by POJO classes. It is a stateless session bean that defines methods corresponding to the steps of the use case. The methods' parameters and return values are primitive Java types and data transfer objects (DTO) [EJBPATTERNS], which are not shown in this diagram. For example, the method enterDeliveryAddress(), which is invoked by the presentation tier when the user enters the delivery information, has following parameters: pending order id, Address and Date. It returns an EnterDeliveryAddressAndTimeResponse, which consists of a status code, and a PendingOrderValue, which is a snapshot of the values in the PendingOrder, and its associated objects, including its line items and restaurant.
The PendingOrder, and its associated line items, payment information, delivery address and time comprise the session state for the Process Order use case. As the user goes through the use case the information they enter is accumulated in a PendingOrder. In this application we store the session state in the database in order to make the server stateless.
The Restaurant, its menu items and opening times comprise the record data for this application. The record data is naturally stored in the database.
The domain model also has some repositories, which encapsulate access to the persistent store. The PendingOrderRepository manages PendingOrders and the RestaurantRepository manages Restaurants.
Figure 2 shows one way the application classes can use the JDO APIs.
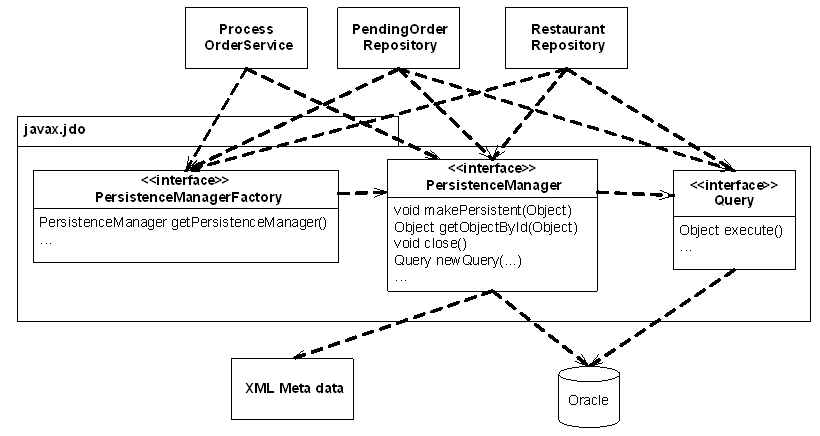
Figure 2 - Invoking JDO APIs
Most of the classes in the domain model, such as PendingOrder, PendingOrderLineItem, Restaurant and MenuItem, are unaware that they are persistent, and do not invoke the JDO APIs. They are all POJO classes and the developer writes XML metadata that specifies how these classes and their fields map to the tables and columns of the database. A JDO implementation provides a class file enhancement tool that reads the XML metadata and modifies the class files to make the classes persistent.
The session facade and the repositories are the only classes that need to invoke the JDO APIs. They use the PersistenceManagerFactory, PersistenceManager and Query interfaces provided by JDO. An application uses the PersistenceManagerFactory to obtain a PersistenceManager, which is the primary interface that JDO provides to an application. It defines various methods including getObjectById(), which finds an object given its id, makePersistent(), which makes a new object persistent, and close(), which closes a PersistenceManager. It also provides methods for obtaining a Query object, which defines methods for executing queries against the data store.
Each session facade business method typically uses a repository to load one or more "root" objects from the database by using the PersistenceManager and Query interfaces and then navigates to related objects by simply following references. Any changes that it makes to the objects are automatically persisted back to the database. The application creates an object by using 'new' in the usual way and then persists it by either calling PersistenceManager.makePersistent() or by making an already persistent object refer to it.
It is important to note, however, that while the domain model classes do not invoke the JDO APIs, JDO persistence is not completely transparent. Section 2 describes how the design of the domain model classes must be altered in small, yet significant ways to address a number of object-relational mapping issues.
Furthermore, while the application could use the JDO APIs directly as shown in Figure 2 there are some serious drawbacks with this straightforward approach. Since the repositories use JDO directly, their clients - i.e. the domain model classes and the session facade - are coupled to the database. Also, because of the way the repositories need to use the PersistenceManagerFactory to get the PersistenceManager, they and the classes that call them can only run inside the application server. Sections 3 and 4 describe a better approach that encapsulates the JDO APIs in order to decouple the domain model from the database and ensure that the code runs in both the application server and the 2-tier testing environment.
Object/Relational Mapping Issues
In this section we describe some object/relational mapping issues with using JDO.
Persisting Embedded Value Objects
Figure 3 shows the database schema for this application.
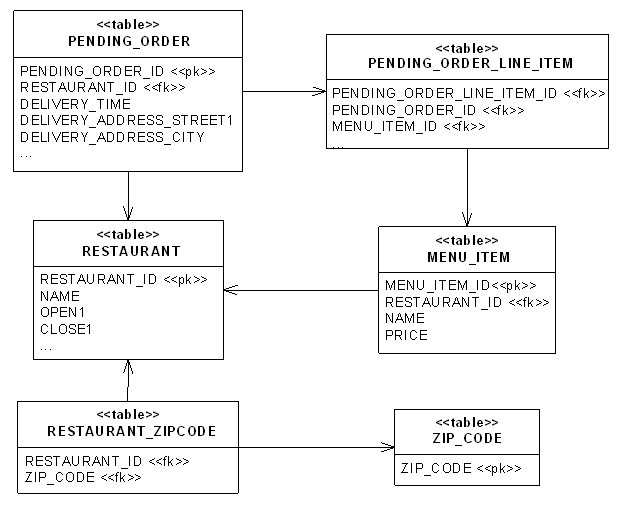
Figure 3 - Database schema
The schema is quite similar to the domain model. Each of the main classes in the domain model - PendingOrder, PendingOrderLineItem, Restaurant and MenuItem - has a corresponding table. The 1 to many associations between a restaurant and its menu items and between a PendingOrder and its line items are represented by foreign keys in the MENU_ITEM and PENDING_ORDER_LINE_ITEM tables respectively. Similarly, the many to 1 association between a PendingOrderLineItem and a MenuItem is represented by a foreign key in the PENDING_ORDER_LINE_ITEM table. A restaurant's zip codes, which in Java is a collection of strings, and corresponds to a many to many relationship between restaurants and zip codes is represented by the join table RESTAURANT_ZIP_CODE, which has foreign keys to both the RESTAURANT and ZIP_CODE tables.
JDO doesn't define any standard object/relational (O/R) mapping mechanism and it is up to each JDO vendor to decide what mapping they support. However, every JDO implementation that supports relational databases provides at a minimum, basic level of support for O/R mapping. A developer can declaratively specify the mapping between a class and its fields and a database table and its columns, and map object relationships to foreign keys and join tables in the database. Indeed, a typical JDO implementation will support almost the entire O/R mapping that this application requires.
However, one challenging aspect of the O/R mapping concerns the PendingOrder's Address, and PaymentInformation classes and the Restaurant's OpeningHours and TimeRange classes. These classes represent instances of the Embedded Value Pattern [FOWLER]. Rather than each of these classes having its own table we want to store their fields in the parent object's table. We want to map the fields of the PendingOrder's Address and PaymentInformation objects to columns of the PENDING_ORDER table and the fields of the Restaurant's OpeningHours and TimeRange classes to columns of the RESTAURANT table. Unfortunately, JDO implementations typically do not support persisting embedded value objects except, perhaps, by using serialization, which is not really useful for an enterprise system. This means that the application must contain code to persist the embedded value objects.
This can be accomplished by defining fields in the parent class corresponding to the fields of the embedded class and by adding code to the parent class to map between those fields and the embedded value objects. For example, PendingOrder has fields for the delivery address, such as deliveryStreet1, and deliveryCity, and for the payment information, such as paymentStreet1, and paymentCity:
class PendingOrder {
private String deliveryStreet1;
private String deliveryStreet2;
private String deliveryCity;
private String deliveryState;
private String deliveryZip;
...
}
The XML metadata maps these fields to columns into the PENDING_ORDER table.
There are a couple of different ways to map between the embedded value object and its fields in the parent object. One way to accomplish this for immutable objects, such as Address and PaymentInformation, is for the embedded object's getter to create it on the fly and for its setter to update the parent object's fields:
class PendingOrder {
protected void setDeliveryAddress(Address address) {
if (address == null) {
this.deliveryStreet1 = null;
this.deliveryStreet2 = null;
this.deliveryCity = null;
this.deliveryState = null;
this.deliveryZip = null;
} else {
this.deliveryStreet1 = address.getStreet1();
this.deliveryStreet2 = address.getStreet2();
this.deliveryCity = address.getCity();
this.deliveryState = address.getState();
this.deliveryZip = address.getZip();
}
}
public Address getDeliveryAddress() {
if (deliveryZip == null)
return null;
else
return new Address(
deliveryStreet1,
deliveryStreet2,
deliveryCity,
deliveryState,
deliveryZip);
}
...
}
This approach is quite simple but only works for immutable objects. It could also be inefficient since the getter creates a new object each time. An alternative approach, which works for mutable objects and is more efficient because it constructs the embedded object when the parent object is loaded, is to use the JDO instance callbacks. If a class implements the InstanceCallbacks interface, the JDO implementation will invoke the methods defined by that interface at the appropriate times during the object's lifecycle. The two callback methods that are useful here are jdoPostLoad() and jdoPreStore(). The method jdoPostLoad(), which is invoked after the object's fields are loaded from the database, creates the embedded object from its parent's fields. The method jdoPreStore(), which is called immediately before the object is stored in the database, updates the parent's fields with values from the child object.
The Restaurant class uses this approach to persist its opening hours:
class Restaurant {
private int open1;
private int close1;
private int open2;
private int close2;
private int open3;
private int close3;
...
private OpeningHours openingHours;
public void jdoPostLoad() {
openingHours = new OpeningHours(new int[]{open1, close1, ...});
}
protected OpeningHours getOpeningHours() {
int notUsed = open1; // ensure object is loaded
return openingHours;
}
public void jdoPreStore() {
int[] times = openingHours.getTimes();
open1 = times[0];
close1 = times[1];
...
}
...
}
The fields open1, close1, open2, ... are persistent fields that store the Restaurant's opening hours. The jdoPostLoad() method creates an OpeningHours object from these fields and stores it in openingHours field, which is not persistent. The method getOpeningHours() returns the openingHours field. It first references the persistent field open1 to ensure that the object is loaded and that jdoPostLoad() is invoked. The jdoPreStore() method updates the open1, close1, ... fields.
One significant drawback of using JDO instance callbacks is that the domain classes end up containing JDO-specific code, which is extremely undesirable. Fortunately, this code can be ignored during in-memory testing since objects are neither loaded nor stored. For example, the tests would create Restaurant objects with their openingHours fields already initialized.
Object Identity
Because JDO provides transparent persistence, the domain model classes are unaware of their persistent identity. They refer to one another via references not primary keys, and the JDO implementation is responsible for ensuring that objects retain their identity in the database. However, since the ProcessOrderService exchanges data transfer objects (DTO) - not domain objects - with the presentation tier it has to map between domain objects and their object ids. When the session facade constructs a DTO from a domain object it has to put its object id in the DTO so that the presentation tier can specify it in subsequent requests. Similarly, when the presentation tier invokes a business method, the session facade has to find the object identified by an object id parameter. For example, all ProcessOrderService methods have a pending order id parameter and return a DTO that contains a pending order id.
Although the presentation tier and session facade communicate about domain objects using database primary keys, it is not straightforward to implement the mapping since JDO encapsulates the database. The JDO specification defines three types of object identity, which can be selected on a per class basis. Two of the three types of object identity, data store identity and application identity, are suitable for the classes in this application. With data store identity the JDO implementation is responsible for assigning an object its identity, i.e. generating the database primary key. An object's persistent identity is not stored in one of its fields. Instead, the application calls PersistenceManager.getObjectId(object) to get the object's identity. With application identity, which is an optional yet widely supported feature, an object's primary key consists of the values of one or more fields of the object. The application is responsible for generating unique primary keys.
With both types of identity each persistence class has an Object Id class, which is analogous to an entity bean's primary key class and conforms to a similar set of rules. There is also the additional requirement to be able to map between an object id and a String. An Object Id class must implement a toString() method and a constructor that takes a string value returned by toString() and recreates the original object id.
Each type of identity has an associated set of tradeoffs. With data store identity the application developer has less code to write. They don't have to implement primary key generation or define any Object Id classes since they are provided by the JDO implementation. On the other hand, the type of an Object Id class is opaque, which means that either it is passed around as a value of type Object or converted to and from a String. This can complicate the presentation tier since unlike with integer primary keys, it does not know the format, and would have to escape any primary key values that it inserts into the generated HTML, such as URL parameters. There is also no guarantee that the object id string is something we want to embed in a URL. It might be a long string or could contain information that we would rather not want to display to the user. Also, test cases for the session facade or the presentation tier that need to know the object ids of certain test objects are harder to write since the object id string is not necessarily the same as the primary key. Furthermore, the application cannot get the id of an object from a field. It must instead call PersistenceManager.getObjectId(object) which returns an instance of an Object Id class, which increases the number of JDO API calls in the code. Finally, it is a little strange to use a String value for a primary key when we know that the corresponding database column is numeric.
With application identity, the application developer has more control over the type of the primary keys. They could decide whether to use an integer or string value in DTOs and session facade method parameters and return values. Furthermore, the application can obtain the identity of an object by calling a getter for the primary key field. On the other hand, the developer has to write more code. Each domain class needs to have a primary key field or fields and an associated Object Id class. Since a primary key typically has no business meaning it is likely that an identity field has to be added to each domain model class. The developer also has to implement a primary key generation mechanism [EJBPATTERNS], unless they use non-standard extensions provided by some JDO implementations.
An application can usually use data store identity for most, if not all, of the classes, and so reduce the amount of code that needs to be written. However, neither approach is ideal and, surprisingly, neither option is truly transparent to the application. It makes sense, therefore, to encapsulate the object identity mechanism that a class uses within its repository. Each repository defines a getObjectId() method for each of the classes that it is responsible for. For example, the PendingOrderRepository class defines a getObjectId() method that takes a PendingOrder and returns a string:
class PendingOrderRepository {
public String getObjectId(PendingOrder order) {
...
}
}
The getObjectId() method could either get the object id from the PersistenceManager or from the object itself, depending on the type of identity used.
1 to Many Relationships Issues
The 1 to many relationships - PendingOrder → PendingOrderLineItem and Restaurant → MenuItem - in this domain model are unidirectional. Unfortunately, the way some, but not all, JDO implementations specify the database mapping for 1 to many relationships requires the Java classes to reference each other. For example, the PendingOrderLineItem class must have a field that references the PendingOrder class and the O/R mapping for the PendingOrder → PendingOrderLineItem relationship is specified by a combination of the metadata for both fields.
This requirement has a couple of drawbacks. The field in the child object must be set to refer to the parent object. Some JDO implementations have extensions that do this automatically but a portable application cannot rely on this feature. Instead, the application must set the field in the child object, which is additional work and is potentially error prone. Furthermore, the reference from the child object to the parent introduces an unnecessary dependency into the Java code, and can prevent the application from having a layered design, and thereby reduces maintainability, reusability and testability. It can also prevent the application from using 3rd party class libraries.
Designing Repositories for Testability
In this section we describe how to design the repositories to improve testability. We first describe how to make the repositories configurable so that the classes that use them can be tested using in-memory objects. After that, we show how to make it possible to test the repositories themselves outside of the application server.
Unlike the majority of the classes in the domain model which are independent of JDO, the repositories must use the JDO API to make objects persistent, and to retrieve them from the database. They could be implemented as simple wrappers around the JDO PersistenceManager and Query interfaces. For example, the method PendingOrderRepository.findPendingOrder() could be implemented as follows:
class PendingOrderRepository {
public PendingOrder findPendingOrder(String pendingOrderId) {
PersistenceManager pm = ...
Object key = pm.newObjectIdInstance(PendingOrder.class, pendingOrderId);
PendingOrder po = (PendingOrder)pm.getObjectById(key, true);
return po;
}
...
}
This method uses the PersistenceManager to first create an object id instance and then find the specified PendingOrder.
However, this simple approach couples the domain model classes that directly or indirectly use the repositories to JDO and therefore, to the database and potentially the application server, which would slow down development and complicate testing.
A better approach is to decouple a repository's interface from its implementation and to have the ability to plug-in different implementations. Ordinarily, a repository is configured to use a JDO implementation. During testing, however, we could use a Service Stub [FOWLER] that accesses a simple in-memory database of test objects.
Figure 4 shows the design of the PendingOrderRepository and the RestaurantRepository classes using this approach:
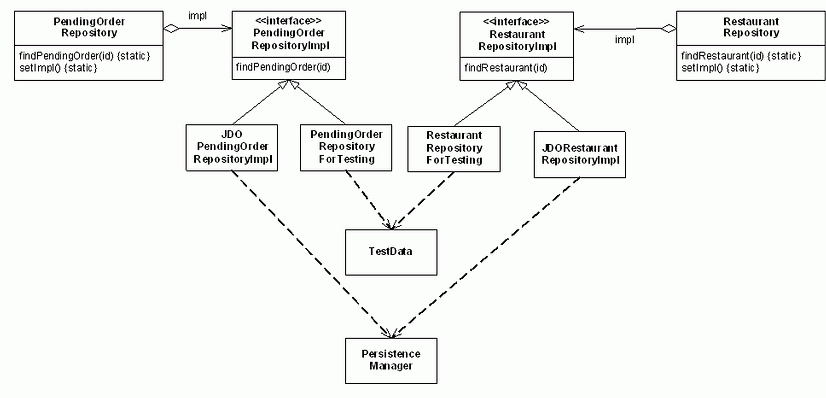
Figure 4 - PendingOrderRepository and RestaurantRepository design
Each repository defines static methods that delegate to an implementation class. For example, the PendingOrderRepository class defines methods that delegate to a PendingOrderRepositoryImpl:
public class PendingOrderRepository {
private static PendingOrderRepositoryImpl impl;
public static void setImplementation(PendingOrderRepositoryImpl impl) {
PendingOrderRepository.impl = impl;
}
public static PendingOrder createPendingOrder() {
return impl.createPendingOrder();
}
public static PendingOrder findPendingOrder(String pendingOrderId) {
return impl.findPendingOrder(pendingOrderId);
}
public static String getObjectId(PendingOrder pendingOrder) {
return impl.getObjectId(pendingOrder);
}
}
There are two implementations of each repository - a test implementation, which accesses in memory test data and a JDO implementation, which uses the JDO PersistenceManager to access the database. For example, the in-memory test cases for the domain model classes configure the PendingOrderRepository to use the class PendingOrderRepositoryForTesting, which uses a simple in-memory database of test objects. Similarly, the application startup code configures the PendingOrderRepository to use JDOPendingOrderRepositoryImpl, which is the JDO implementation of the PendingOrderRepository:
public class JDOPendingOrderRepositoryImpl implements
PendingOrderRepositoryImpl {
public PendingOrder createPendingOrder() {
JDOPendingOrder po = new JDOPendingOrder();
PersistenceManager pm = getPM();
pm.makePersistent(po);
return po;
}
public PendingOrder findPendingOrder(String id) {
PersistenceManager pm = getPM();
Object key = pm.newObjectIdInstance(
JDOPendingOrder.class, id);
return (PendingOrder)pm.getObjectById(key, true);
}
public String getObjectId(PendingOrder object) {
PersistenceManager pm = getPM();
return pm.getObjectId(object).toString();
}
public PersistenceManager getPM() {
return ...;
}
}
It uses the JDO PersistenceManager as described above.
This approach is extremely valuable. The ability to test the domain classes using in-memory implementations of the repositories significantly accelerates development and testing. The only drawback is the increased complexity because of the additional classes that are required.
It is also important to be able to easily test the JDO implementations of the repositories: JDOPendingOrderRepositoryImpl and JDORestaurantRepositoryImpl. Specifically, we want to be able to test them outside of the application server. In turns out that the key issue is how they obtain a PersistenceManager, which up until now is something that we have glossed over.
Within an application server, a repository can use the following code fragment (ignoring performance issues etc) to get a PersistenceManager:
PersistenceManager getPM() {
PersistenceManagerFactory pmf =
(PersistenceManagerFactory)ctx.lookup("jdo...");
return pmf.getPersistenceManager();
}
This code does a JNDI lookup to get the PersistenceManagerFactory and calls getPersistenceManager(), which returns the PersistenceManager associated with the current transaction, making one if required.
Unfortunately, this code won't work in a 2-tier environment, such as a JUnit-based test driver, where the application code runs outside of the application server. Instead of using JNDI to lookup the PersistenceManagerFactory, an application must use the JDOHelper class:
Properties p = ... PersistenceManagerFactory pmf = JDOHelper.getPersistenceManagerFactory(p);
The JDOHelper class creates a PersistenceManagerFactory using the properties, which are typically read from a properties file.
Another problem is that in a 2-tier environment each call to the method PersistenceManagerFactory.getPersistenceManager() returns a new instance. Since JDO requires an application to use the same PersistenceManager instance throughout a transaction, this method must be called just once during each transaction. It is not possible for each repository to obtain its own instance since one or more repositories might be invoked multiple times within the same transaction.
One way to make the repositories work in both 2-tier and application server environments is to make the code that invokes them responsible for obtaining a PersistenceManager. The session facade could obtain the PersistenceManager, using the JNDI-based code shown above, and pass it to the domain class methods that directly or indirectly use the repositories. Similarly, the test code would use the JDOHelper-based approach to obtain a PersistenceManager. However, this approach is not workable since it clutters the domain model code with references to the PersistenceManager and thereby couples the code to JDO.
A much better approach, which is shown in Figure 5, is to encapsulate access to the PersistenceManager behind an interface that hides whether the code is running in an application server or a 2-tier environment.

Figure 5 - PersistenceManager access mechanism design
The JDO implementations of repositories get the PersistenceManager from the PMRegistry, which is a thread scoped registry:
class PMRegistry {
public static ThreadLocal pmHolder = new ThreadLocal();
public static PersistenceManager getPM() {
return (PersistenceManager) pmHolder.get();
}
public static void setPM(PersistenceManager pm) {
pmHolder.set(pm);
}
}
The PersistenceManager instance is stored in a ThreadLocal and so is specific to the thread. The setPM() method sets the instance and the getPM() returns it. The repositories call PMRegistry.getPM() whenever they need a PersistenceManager. For example:
public class JDORestaurantRepositoryImpl ...
public Restaurant findRestaurant(String restaurantId) {
PersistenceManager pm = PMRegistry.getPM();
return (Restaurant)pm.getObjectById(
new JDORestaurantKey(restaurantId),
true);
}
...
}
Encapsulating the mechanism for accessing the PersistenceManager enables the repositories and their clients to work in both application server and two-tier environments, which makes development and testing significantly easier and faster. The main drawback to this approach is that the encapsulation mechanism increases the complexity of the design by adding more classes.
Designing the Session Facade for Testability
In the previous section we described how the PMRegistry encapsulates the mechanism for accessing to the PersistenceManager. Obviously, the application must initialize the PMRegistry at the beginning of a transaction, and close the PersistenceManager at the end of the transaction.
The session facade is the logical place to do both of these things. It uses container-managed transactions and so each invocation of a business method corresponds to a transaction. One way to implement the session facade is as follows:
class ProcessOrderServiceBean implements SessionBean {
PersistenceManagerFactory pmf;
public void setSessionContext(...) {
pmf = (PersistenceManagerFactory)ctx.lookup("jdo...");
}
public SelectRestaurantResponse selectRestaurant(
String poId,
String restId) {
PersistenceManager pm = pmf.getPersistenceManager();
try {
PMRegistry.setPM(pm);
PendingOrder pendingOrder =
PendingOrderRepository.findPendingOrder(poId);
Restaurant restaurant =
RestaurantRepository.findRestaurant(restId);
...
} finally {
pm.close();
}
}
...
}
The setSessionContext() method looks up the PersistenceManagerFactory and each business method gets the PersistenceManager, initializes the PMRegistry, and closes the PersistenceManager before returning.
Although this approach is straightforward, it can slow down development and testing because the logic in the session facade is coupled to the database and the application server. A better approach is shown in Figure 6.
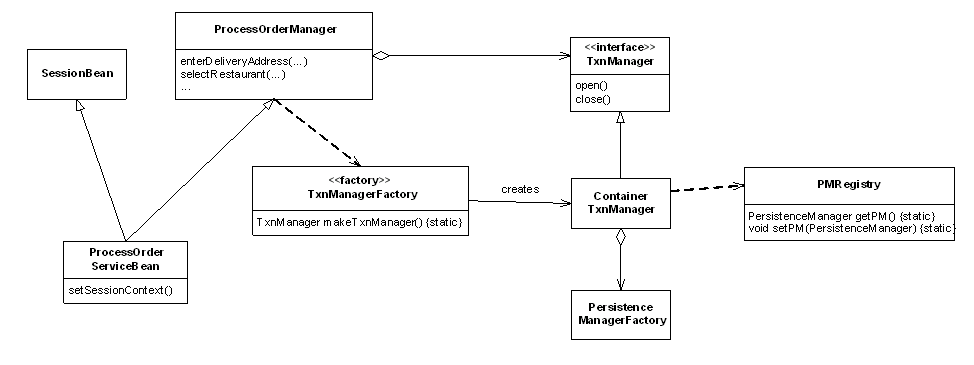
Figure 6 - Session Facade Design
There are two parts to the solution. First, the session facade is implemented by a pair of classes, ProcessOrderServiceBean and ProcessOrderManager. ProcessOrderServiceBean is a session bean that extends the POJO class ProcessOrderManager, which contains the majority of the session facade code and can be developed and tested outside of the EJB container. Second, the management of the PersistenceManager and the PMRegistry is encapsulated by a TxnManager interface. The TxnManagerFactory provides an API for creating a TxnManager, and is called by the ProcessOrderManager. There are implementations of the TxnManager interface for the application server and two-tier testing environment.
The ProcessOrderServiceBean is extremely simple:
public class ProcessOrderServiceBean
extends ProcessOrderManager
implements SessionBean {
protected SessionContext ctx;
public void setSessionContext(SessionContext context) {
this.ctx = context;
initialize();
}
...
}
It extends ProcessOrderManager and defines a setSessionContext() method that calls the initialize() method defined by ProcessOrderManager.
The ProcessOrderManager implements the business methods:
protected TxnManager tm;
protected void initialize() {
tm = TxnManagerFactory.makeTransactionManager();
}
public SelectRestaurantResponse selectRestaurant(
String pendingOrderId,
String restaurantId) {
tm.open();
try {
...
} finally {
tm.close();
}
}
...
}
It defines an initialize() method that creates a TxnManager. Each business method starts by calling TxnManager.open() and ends by calling TxnManager.close().
There are multiple implementations of the TxManager interface. ContainerTxnManager is an implementation for an application server environment:
public class ContainerTxnManager implements TxnManager {
private PersistenceManagerFactory pmf;
public ContainerTxnManager () {
try {
pmf = (PersistenceManagerFactory) ctx.lookup("java:/jdo");
} catch (NamingException e) {
throw new ApplicationException();
} finally {
...
}
}
public void open() {
PMRegistry.setPM(pmf.getPersistenceManager());
}
public void close() {
PersistenceManager pm = PMRegistry.getPM();
PMRegistry.setPM(null);
pm.close();
}
}
Its constructor does a JNDI lookup to get the PersistenceManagerFactory. Its open() method creates a PersistenceManager and stores it in the registry and its close() method closes the PersistenceManager and sets the registry instance to null. The test suites also define implementations of the TxnManager interface that work in the 2-tier testing environment.
This approach has two main benefits. It refactors the session facade moving the business methods into a POJO class that can be developed and tested outside of the application server. Furthermore, it decouples the session facade from JDO enabling it to be tested without a database. The main drawback to this approach is that the encapsulation mechanism increases the complexity of the design by adding more classes.
Summary
Figure 7 shows the design approach described in this article.
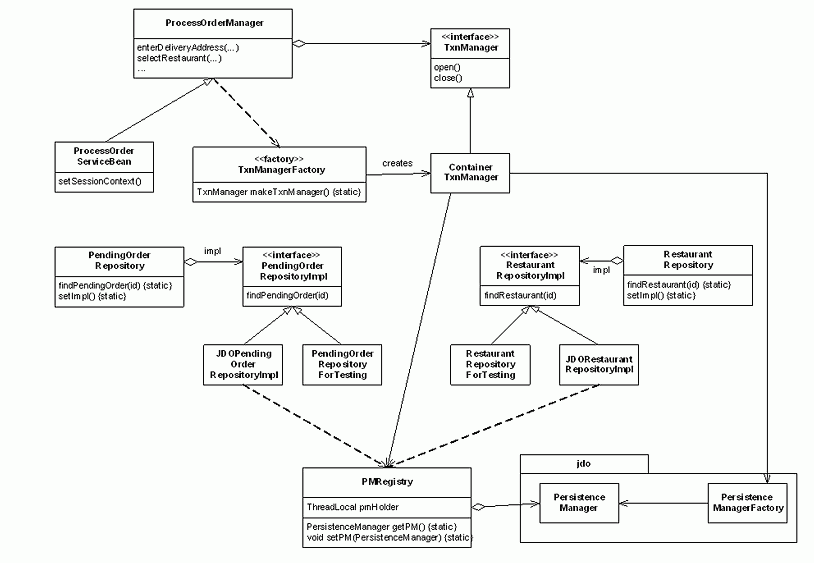
Figure 7 - Designing for testability
There are three parts to the solution. First, each repository consists of static methods that delegate to an implementation interface. There are two concrete implementations of this interface - a JDO version and a test version that accesses in-memory objects. This approach decouples the domain model classes from the JDO APIs enabling them to be developed and tested without a database.
Second, the JDO versions of the repositories do not access the PersistenceManagerFactory. Instead, they get the PersistenceManager from the PMRegistry, which is a thread-scoped singleton, which is initialized by either the session facade or the test case setup code. Using the PMRegistry enables the repositories to run in both application server and 2-tier testing environments.
Finally, the session facade is implemented by a pair of classes - ProcessOrderServiceBean, which is the session bean, and ProcessOrderManager, which is a POJO class. The ProcessOrderManager is responsible for initializing the PMRegistry. However, it does not do it directly and instead delegates to a TxnManager, which encapsulates the mechanism used to obtain the PersistenceManager. This approach enables the majority of session facade code to be tested outside of the application server.
Overall, JDO is a fairly good technology for persisting a domain model and mostly lives up to its claims. However, persistence is not entirely transparent in a couple of ways. JDO implementations do not directly support embedded value objects, which requires changes to the domain model that possibly involve the use of JDO instance callbacks. Also, some JDO implementations force what would otherwise be unidirectional 1 to many relationships to be bi-directional.
This article shows that a domain model that uses JDO as the persistence mechanism can be designed in a way that enables it to be tested outside of the application server and without a database. It is a lot easier to do this with JDO than it is with entity beans using the approach described in my previous article. Furthermore, JDO lets you do 2-tier testing of the domain model against a database, which is extremely useful, and not possible with entity beans.
However, simply using JDO does not guarantee that you will be able to do this. The naive use of JDO will result in a domain model that is coupled to both the application server and the database. You have to explicitly design the application to support in-memory and 2-tier testing. While the resulting design is slightly more complex because it requires a few additional classes, the ability to write code that executes outside of the application server and, where possible, without a database, accelerates development and testing tremendously.
References
[EJBPATTERNS] EJB Design Patterns, F. Marinescu
[FOWLER] - Enterprise Application Patterns, Martin Fowler
[JDO] Java Data Objects Specification, 1.0, http://jcp.org/aboutJava/communityprocess/final/jsr012/index.html
[RICHARDSON] - Two Level Domain Model, Chris Richardson, /articles/article.tss?l=TwoLevelDomainModel
About the Author
Chris Richardson is a freelance software architect and mentor who specializes in J2EE application development. He has over 15 years of experience developing object-oriented software systems in a wide variety of domains including online trading, mobile system provisioning, telecommunications and e-commerce. He is based in the San Francisco Bay Area and can be reached at [email protected].






