JAXP: Coding for Parser & Transformer Independence
This introductory article will educate developers about the JAXP API, and provide them with a strong understanding of the pluggability layer that will allow their applications to switch between parsers at will.
Introduction
The eXtensible Markup Language (XML) has gained tremendous popularity over recent years because of its ease of use and portability. When coupled with the Java programming language, the end result is a fitting combination of portable data and portable code. Every Java developer that interacts with XML documents in any form, from reading data to performing data transformation, must have a strong understanding of the Java API's for XML Processing (JAXP). Writing XML parser independent code has many benefits; the JAXP API is to XML as the JDBC API is to the relational database. This introductory article will educate developers about the JAXP API, and provide them with a strong understanding of the pluggability layer that will allow their applications to switch between parsers at will.
JAXPack
Sun has put out a bundle of publicly available Java APIs and Architectures for XML called Java XML Pack (JAXPack - http://java.sun.com/xml/javaxmlpack.html). The download contains several of the key standards that are currently evolving in the industry. For this article, we will focus on JAXP, the API for XML Processing. Sybase's EAServer product has included support for JAXP since version 3.6.1.
First off, we will take a look at the parsing capabilities that JAXP provides. In parsing an XML document, there are two basic approaches. SAX is an event-based approach and DOM is a tree-walking approach. It is up to the developer to choose the one most suitable to their needs. Let's dive right in and take an in-depth look at these APIs.
Throughout this article, we will be using the XML displayed in Figure 1 in order to illustrate our examples.

SAX
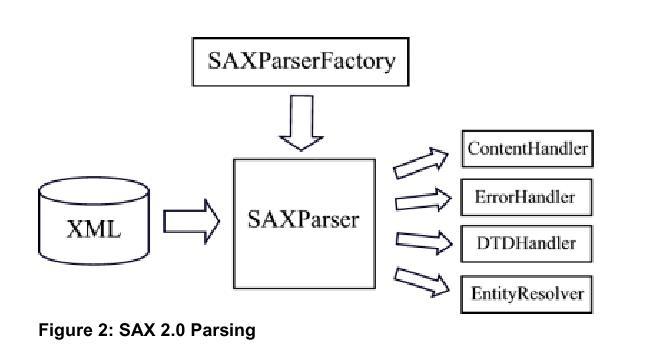
The Simple API for XML Parsing (SAX) is an event-driven parser that traverses the entire document from beginning to end, notifying the application that runs it each time it recognizes a syntax construction. This is done by means of callback methods contained in the event handler interfaces ContentHandler, ErrorHandler, DTDHandler, and EntityResolver. The methods can then be custom implemented by the developer to perform specific desired functions. Figure 2 depicts the relationship between the various components that go into parsing an XML document with a SAX parser.
We will now walk through the sample XML document from Figure 1 and detail the calls that the SAXParser makes as it goes line by line. For this example, we will not include the calls to the method ignorableWhiteSpace.

Now that you have a high level understanding of how SAX works, let's go through an example and see how the actual java code is implemented. The full source code of all the programs that we will be going over can be found through: http://www.sybase.com/developer. For the purposes of this article, I will only be including excerpts of relevant portions of the code.
Let's go right into the code:
public class SAXExample extends DefaultHandler {
.
.
.
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser saxParser = factory.newSAXParser();
DefaultHandler handler = new SAXExample();
saxParser.parse( new File(argv[0]), handler);
Notice that we've extended the DefaultHandler class, which implements ContentHandler, ErrorHandle, DTDHandler, and EntityResolver with "empty methods" and allows the programmer to override only the methods that they need.
Before we begin parsing, we first need to instantiate a SAXParserFactory object by calling newInstance. This method uses an ordered lookup procedure to determine which SAXParserFactory implementation to use (more on this later), which allows the developer to point to the desired implementation through a system property rather than having to refer to it in the actual code. This means that the code does not need to be recompiled each time the parser implementation is changed.
Once we have our SAXParserFactory, there are three options that can be set, which will determine how it will subsequently create SAXParser objects:
- setNamespaceAware toggles namespace awareness
- setValidating turns on validation
- setFeature sets the particular feature of the underlying implementation
After the SAXParserFactory is configured, we call newSAXParser to instantiate a JAXP SAXParser, which wraps the underlying SAX Parser and allows us to interact with it in a vendor-neutral way. Now we are ready to parse. In this case, parse takes a File object as input, but it can also accept other input sources such as an InputSource object, an InputStream object, or a Uniform Resource Identifier (URI).
Notice how the program specifies itself as the handler to the parser, which means that the parser will be calling the callback methods defined in SAXExample. As the parse method goes through the XML file line by line, event callbacks from our handler are invoked.
DOM
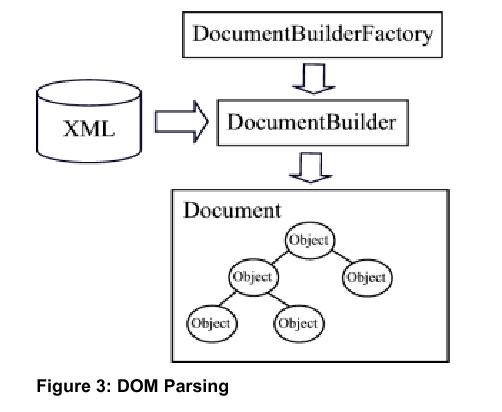
The Document Object Model (DOM) is a set of interfaces that parse an XML document into a tree structure of objects. Each object, or Node, has a type that is represented by an interface in the package org.w3c.dom, such as Element, Attribute, Comment, and Text. This DOM tree object representation can then be manipulated just like any tree data structure. This allows for random access to particular pieces of data from the XML document and the ability to modify the XML document, which are not possible with a SAX parser.
The downside of using this API is that it is extremely memory and CPU intensive, since building the DOM requires that the entire XML structure be read and held in memory.
Let's see an example:
public class DOMExample {
.
.
.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder domParser = factory.newDocumentBuilder();
Document document = domParser.parse( new File(argv[0]) );
Similar to SAX, we first instantiate a DocumentBuilderFactory object, by using the newInstance method. Just like the SAXParserFactory, the factory can be configured to handle namespaces and validation. In addition, there are several other settings that can be selected, but that is beyond the scope of this article. Once the factory is ready, we can create a new DocumentBuilder object, which is then used to parse the XML file, creating a Document DOM object. Just like the SAXParser's parse method, it can also accept other input sources such as an InputSource object, an InputStream object, or an URI.
Node thePhonebook = document.getDocumentElement(); NodeList personList = thePhonebook.getChildNodes(); Node currPerson = personList.item(0); Node fullName = currPerson.getChildNodes().item(0); Node firstName = fullName.getChildNodes().item(0); Node lastName = fullName.getChildNodes().item(1); Text firstNameText = (Text)firstName.getFirstChild(); Text lastNameText = (Text)lastName.getFirstChild(); Node phone = currPerson.getChildNodes().item(1); Node workPhone = phone.getChildNodes().item(0); Node homePhone = phone.getChildNodes().item(1); Text workPhoneText = (Text)workPhone.getFirstChild(); Text homePhoneText = (Text)homePhone.getFirstChild();
Once we have the Document DOM object we can simply traverse the structure as we would any tree. Calling getDocumentElement returns the root element. From there, we can get a NodeList of child nodes and proceed from there. At the leaf level of our DOM structure, we can find Text objects, which inherit from Node. Calling getData returns to us the string. As you can see, the user needs to have prior knowledge of the structure of the data in order to be able to know how to access it, unlike in SAX, which just reacts to what it finds.
But one of the major advantages of DOM is that we can actually modify our data structure. For example:
if (firstNameText.getData().equals("Richard") &&
lastNameText.getData().equals("Mullins")) {
homePhoneText.setNodeValue("(510)333-3333");
}
Calling setNodeValue actually changes the data stored in the DOM tree. Later on, we will see how XSLT can be used to write out the new tree into a data file.
XSLT
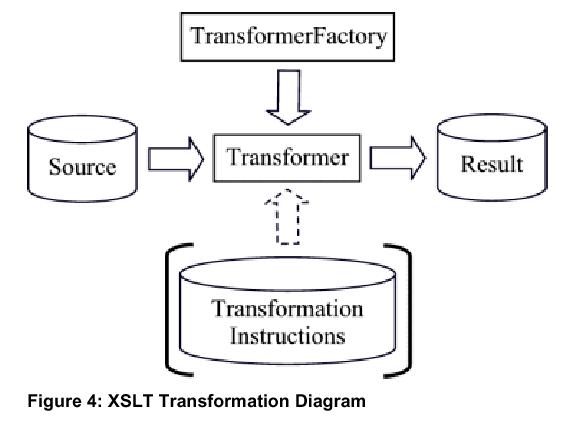
XSL Transformations (XSLT) is an API that can be used to transform XML documents into other XML documents or other formats such as HTML. A stylesheet written in the XML Stylesheet Language (XSL) is usually needed to perform the transformation. The stylesheet contains formatting instructions which specify how the document is to be displayed.
Here is an example that takes a DOM object and transforms it into an XML document:
//create a new DOMSource using the root node of an existing DOM tree DOMSource source = new DOMSource(thePhonebook); StreamResult result = new StreamResult(System.out); TransformerFactory tFactory = TransformerFactory.newInstance(); Transformer transformer = tFactory.newTransformer(); transformer.transform(source, result);
We first instantiate a new TransformerFactory object by calling newInstance, which goes through the ordered lookup procedure to determine the Transformer implementation to use. As with SAX and DOM factories, there are several settings that can be set which determine the way Transformer objects are created. After a new transformer is created using newTransformer, the transform method is then called, which takes a Source object (implemented by DOMSource , SAXSource , StreamSource) and transforms it into the format of the Result object (implemented by DOMResult, SAXResult, and StreamResult).
Abstraction Layer
As mentioned earlier, an ordered lookup procedure is used in order to determine which implementation of SAX, DOM, or XSLT to use. This order is defined in the API as:
- Use the javax.xml.parsers.SAXParserFactory (or javax.xml.parsers.DocumentBuilderFactory) system property
- Use the properties file "lib/jaxp.properties" in the JRE directory containing the fully qualified name for the implementation class with the key being the system property from above.
- Use the Services API, which looks for the classname in the file META-INF/services/javax.xml.parsers.SAXParserFactory in the jar files used by the runtime.
- Use the platform default SAXParserFactory instance.
For DOM, you just need to replace javax.xml.parsers.SAXParserFactory with javax.xml.parsers.DocumentBuilderFactory. And as for XSLT, use javax.xml.transform.TransformerFactory instead.
Summary
So as you can see, by utilizing the JAXP API, code is written to interact directly with the abstraction layer. This guarantees vendor independence and the ability to swap out the backend implementation quickly and easily. In parsing an XML document, the Java developer has two options depending on their specific needs. SAX is an event-based parsing model that utilizes callback procedures, while DOM is a tree-walking model that parses the XML data into a tree before manipulating it. XSLT provides the ability to transform XML documents into other XML documents or other formats such as HTML. All in all, what we have in JAXP is a powerful, flexible, and easy to use set of tools that will meet the XML processing needs of most Java developers.







