Distributed Computing Made Easy
In case you haven't noticed, distributed computing is hard. The problem is that it is becoming increasingly important in the world of enterprise application development.
Introduction
In case you haven't noticed, distributed computing is hard.
The problem is that it is becoming increasingly important in the world of enterprise application development. Today, developers continuously need to address questions like: How do you enhance scalability by scaling the application beyond a single node? How can you guarantee high-availability, eliminate single points of failure, and make sure that you meet your customer SLAs? All questions that, in one way or the other, imply distributed computing.
For many developers, the most natural way of tackling the problem would be to divide up the architecture into groups of components or services that are distributed among different servers. While this is not surprising, considering the heritage of CORBA, EJB, COM and RMI that most developers carry around, if you decide to go down this path then you are in for a lot of trouble. Most of the time it is not worth the effort and will give you more problems than it solves.
For example, Martin Fowler thinks that a design like this "...sucks like an inverted hurricane" and continues with the following discussion (from his book Patterns of Enterprise Application Architecture):
“Hence, we get to my First Law of Distributed Object Design: Don't distribute your objects.How, then, do you effectively use multiple processors? In most cases the way to go is clustering. Put all the classes into a single process, and then run multiple copies of that process on various nodes. That way, each process uses local calls to get the job done and thus does things faster. You can also use fine-grained interfaces for all the classes within the process and thus get better maintainability with a simpler programming model.”
The main benefit of using clustering is a simplified programming model. The way I see it, clustering, and distribution in general, is something that should be transparent to the application developer. It is clearly a cross-cutting concern that should be orthogonal to and layered upon the application, a service that belongs in the runtime. In other words, what we ultimately need is clustering at the JVM level.
Sample problem
In this article I will walk you through a fairly generic, but common, distributed computing problem, and show how it can be simplified - to become almost trivial - using clustering at the JVM level.
First, let's define the problem. We need some sort of system that:
- Distributes out and executes a set of tasks on N number of nodes
- Can collect the result
- Load-balances itself
- Scales well
To simplify the implementation, we will only have to support tasks that are so-called embarrassingly parallel, which means they have no shared state, but can be executed in complete isolation. Luckily, a majority of applications actually fit into this category.
One of the most well-known and common patterns that solve our problem is the so-called Master/Worker pattern. So, let's take a look at how it works.
The Master/Worker pattern
The Master/Worker pattern consists of two logical entities: a Master, and one or more instances of a Worker. The Master initiates the computation by creating a set of tasks, puts them in some shared space and then waits for the tasks to be picked up and completed by the Workers.
The shared space is usually some sort of Shared Queue, but it can also be implemented as a Tuple Space (for example in Linda programming environments where the pattern is used extensively).
One of the advantages of using this pattern is that the algorithm automatically balances the load. This is possible due to the simple fact that, the work set is shared, and the workers continue to pull work from the set until there is no more work to be done.
The algorithm usually has good scalability as long as the number of tasks, by far exceeds the number of workers and if the tasks take a fairly similar amount of time to complete.
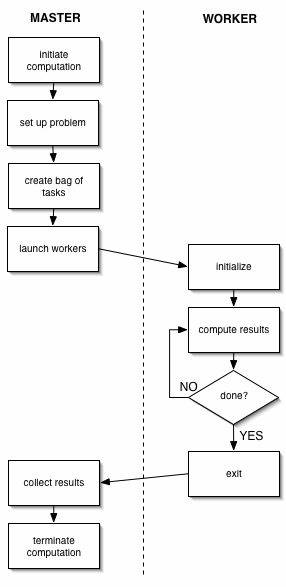
Thread-based single node implementation
We start by implementing the solution as a regular single node multi-threaded application, based on the Master/Worker pattern explained in the previous section.
The ExecutorService interface in the java.util.concurrent package (since Java 5) provides direct support for the Master/Worker pattern, and this is something that we will take advantage of. We are also going to use the Spring Framework's dependency injection (DI) capabilities to wire up and configure the system.
We have two entities: the Master , which coordinates the scheduling of the Work and the collection of the result, and the Shared Queue , which represents the shared space where the pending Work resides. These entities are defined as two different Spring beans named master and queue that are wired up and configured in the Spring bean config file. There is no need to define a Worker bean since the worker is "hidden" and managed under the hood by the ExecutorService.
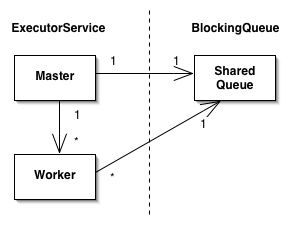
The figure above illustrates that conceptually, the ExecutorService consists of a Master that holds a reference to a Shared Queue (in our case a BlockingQueue) as well as N number of Workers, where each Worker has a reference to the same single Shared Queue.
Master
The master bean implements the ExecutorService interface. This interface provides methods that can produce a Future, or a list of Futures, for tracking progress of one or more asynchronous tasks, e.g. to schedule Work and wait for Work to be completed. The master bean is implemented using the proxy pattern and simply delegates to a ThreadPoolExecutor instance, which is a concrete implementation of the ExecutorService interface that uses a thread pool to manage the Worker threads. Delegating in this way allows for simpler configuration such as default values in the Spring bean config.
Here is how we could implement the master bean:
public class Master implements ExecutorService {
private final ExecutorService m_executor;
public Master(BlockingQueue workQueue) {
m_executor = new ThreadPoolExecutor(
10, 100, 300L, TimeUnit.SECONDS, workQueue);
}
public Master(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
BlockingQueue workQueue) {
m_executor = new ThreadPoolExecutor(
corePoolSize, maximumPoolSize,
keepAliveTime, TimeUnit.SECONDS, workQueue);
}
public List invokeAll(Collection work) throws InterruptedException {
return m_executor.invokeAll(work);
}
... // remaining methods are omitted
}
Shared Queue
Upon creation, the master bean is handed a reference to the shared queue bean, which is an instance of one of the classes that implements the java.util.concurrent.BlockingQueue interface.
The queue bean holds all the pending Work. We need to have a single instance of this queue that can be available to all workers, and we therefore define it as a Singleton in the bean config XML file.
It is called a blocking queue because it will block and wait for more Work to be added to the queue if the queue is empty. Additionally, an optional capacity limit can be set and will, if set, prevent excessive queue expansion, if the limit has been reached then the queue will block until at least one element has been removed.
Assembly
These two beans can now be wired up by the Spring bean config file:
<beans>
<bean id="master" class="demo.masterworker.Master">
<constructor-arg ref="queue"/>
</bean>
<bean id="queue" class="java.util.concurrent.LinkedBlockingQueue"/>
</beans>
Usage
Using the Master/Worker implementation is now simply a matter of getting the bean from the application context and invoking the invokeAll(..), or one of the other similar methods, in order to schedule work:
ApplicationContext ctx =
new ClassPathXmlApplicationContext("*/master-worker.xml");
// get the master from the application context
ExecutorService master = (ExecutorService) ctx.getBean("master");
// create a collection with some work
Collection<Callable> work = new ArrayList<Callable>();
for (int i = 0; i < 100; i++) {
work.add(new Callable() {
public Object call() {
... // perform work - code omitted
}
});
}
// schedule the work and wait until all work is done
List<FutureTask> result = master.invokeAll(work);
Discussion
This was a good exercise and the implementation is useful as it is, but this article is about distributed computing so let's now take a look at how we can turn this multi-threaded, single JVM implementation into a distributed multi-JVM implementation.
Enter Terracotta for Spring.
Introduction to Terracotta for Spring
Terracotta for Spring is a runtime for Spring-based applications that provides transparent and high performance clustering for your Spring applications with zero changes to the application code.
With Terracotta for Spring, developers can create single-node Spring applications as usual. They simply have to define which Spring application contexts they want to have clustered in the configuration file. Terracotta for Spring handles the rest. Spring applications are clustered automatically and transparently and are guaranteed to have the same semantics across the cluster as on the single node.
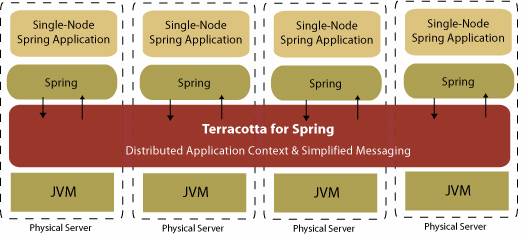
The main features that we will make use of in our sample application are:
- Drops in and out transparently
No changes to existing code necessary, does not even require the source code. The application is transparently instrumented at load time, based on a minimal declarative XML configuration. Terracotta for Spring does not require any classes to implement Serializable, Externalizable or any other interface. This is possible since we do not use serialization, but are only shipping the actual deltas over the wire. - Natural clustering of Spring beans
Life-cycle semantics and scope for Spring beans are preserved across the cluster - within the same logical ApplicationContext. The current clusterable bean types are Singleton and Session Scoped beans. The user can declaratively configure which beans in which Spring application contexts to cluster. - Object identity is preserved
Java's "pass-by-reference" semantics are maintained across the cluster, so regular object references work. This means that you can use your domain model the way you have designed it, as well as traditional OO design patterns etc. without a need to think about distribution, caching or clustering. - Distributed coordination
The Java Memory Model is transparently maintained throughout the cluster, including distributed coordination, for example wait(), notify(), synchronized() {...} etc. - Memory management
It also provides distributed garbage collection and functions also as a virtual heap. For example, run an application with 200 G heap on a machine with 4 G of RAM in which memory is paged in and out on a demand basis.
Let's go multi-JVM
So far, we have only implemented a regular, single node, multi-threaded, implementation of the Master/Worker pattern (that can be used as a single node implementation the way it is). But the interesting thing is that in order to turn this implementation from a multi-threaded application into a distributed, multi-JVM application, we do not need to write any code at all. All we need to do is to drop in Terracotta for Spring along with its XML configuration file, in which we simply define which Spring beans we want to cluster. In our case this means the queue bean, since this queue needs to be available in the whole cluster, e.g. distributed. This is something that we accomplish by simply configuring the bean as Singleton in the bean config XML file as well as listing it among the shared beans in the Terracotta for Spring configuration file.
Here is an example of a configuration file that would make the single node implementation distributed. The important parts are highlighted in bold. First, we have the path(s) to the Spring bean config file(s) that are used to configure the application context we want to share. Second, we have the names of the beans to cluster and the name has to be defined in one of the bean config files.
<?xml version="1.0" encoding="UTF-8"?>
<tc:tc-config xmlns:tc="http://www.terracottatech.com/config-v1">
<application>
<dso>
<spring>
<application name="*">
<application-contexts>
<application-context>
<paths>
<path>*/master-worker.xml</path>
</paths>
<beans>
<bean name="queue"/>
</beans>
</application-context>
</application-contexts>
</application>
</spring>
</dso>
</application>
</tc:tc-config>
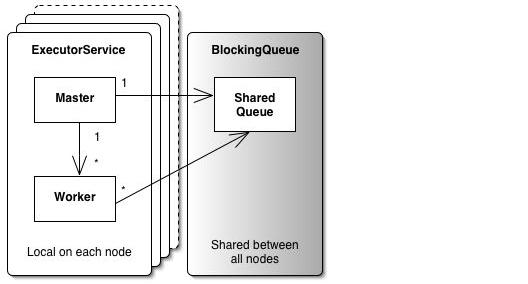
Now we have turned our single-node, multi-threaded application into a distributed, multi-node application. What this means in practice is that we are now able to run the original code that was written for a single JVM - without any thought about distribution or clustering - in a distributed environment, with the exact same semantics as on a single node. We have also seen that we can transparently cluster, not only user-defined classes, but the core Java class libraries, including its concurrency abstractions.
Under the hood
Terracotta uses aspect-oriented technologies to adapt the application at class load time. In this phase it extends the application in order to ensure that the semantics of Java are correctly maintained across the cluster, including object references, thread coordination, garbage collection etc.
For example, it (as mentioned above) maintains the semantics of regular synchronized blocks across the cluster by taking a cluster-wide lock for the object instance that you are synchronizing on right before entering the block and releasing it right after exiting the block. You can declaratively define the exact semantics for the lock (read, write or concurrent). Another example is the invocation of notifyAll(), which is turned into a cluster wide notification allowing for all nodes to contend for the lock.
This is what is happening under the hood in our sample application when Terracotta is coordinating the access to the BlockingQueue and FutureTasks (throughout the cluster). Terracotta supports distributed use of any other thread coordination abstraction, such as Barriers, Semaphores, Mutexes, Guards etc., as well as any custom written abstraction. The only requirement is that it has to use Java's synchronization primitives internally (an article on how to implement distributed barriers using Terracotta can be found here).
I also mentioned before that Terracotta does not use serialization. This means that any regular Plain Old Java Object (POJO) can be shared as well as referenced from a shared instance (part of the shared object graph). What this also means is that Terracotta is not sending the whole object graph to all nodes but breaks down the graph into pure data and is only sending the actual "delta" over the wire, meaning the actual changes, the data that is "stale" on the other node(s). Since it has a central server (see below) that keeps track of who is referencing who on each node, it can also work in a lazy manner and only send the changes to the node(s) that references objects that are "dirty" and need the changes.
The architecture is hub and spoke based, meaning there is a central server which is managing the clients, it uses TCP/IP so the server just needs to be somewhere on the network. The client in this case is simply your regular application together with the Terracotta libraries. The server is not a single-point of failure, but has a SAN-based solution to support fail-over in an active-passive manner. This means that you can have an arbitrary number of (passive) servers waiting in line and upon failure the selected one will pick up right where the master server that has crashed left off.
Discussion
As you have seen, with the use of Terracotta for Spring it is possible to turn a regular single-node multi-threaded implementation into a distributed, multi-JVM implementation without any code changes and while maintaining the exact same semantics. This is extremely powerful and opens up for a completely new way of implementing distributed applications (see Future work below). The main points in this exercise have been to see that Terracotta for Spring takes care of:
- Transparent sharing of the state for the application across multiple distributed nodes
- Coordination of resources is maintained across multiple distributed nodes
- Pass-by-reference semantics is maintained across multiple distributed nodes
- Declarative configuration with zero changes to existing code
Future work
I believe that this way of developing distributed applications, with sharing of state, resource coordination and distributed memory management done at the JVM level, can simplify how we implement applications immensely, since we can focus on the logic and concepts and do not need to worry about the distribution mechanisms and problems.
It would for example be an interesting exercise to implement a Blackboard System, something that is generally very hard, due to all the potential problems related to distributed computing that needs to be addressed. But using Terracotta, the implementation could be simplified to a single-node multi-threaded application, e.g. one could work at a higher level, focusing on getting the concepts and algorithms right, while other cross-cutting concerns like distributed sharing of state, distributed coordination, distributed memory management etc. are layered upon the application afterwards. The same holds for Tuple Space implementations, such as JavaSpaces etc.
Resources
Terracotta for Spring is Free Software for production use. You can find more info here:
- Info about the product: http://www.terracottatech.com/terracotta_Spring.shtml
- Download the product: http://terracottatech.com/downloads.jsp
- Terracotta's company weblog: http://blog.terracottatech.com/
- The author's weblog: http://jonasboner.com/
Acknowledgment
Thanks to Eugene Kuleshov and Chris Richardson for valuable feedback.
About the Author
Jonas Bonér is Sr. Engineer at Terracotta Inc. with a focus on strategy, product development and architecture, and technical evangelism. Prior to Terracotta, Jonas was a senior software engineer for the JRockit team at BEA Systems, where he was working on runtime tools, JVM support for AOP and technology evangelism. He is the founder of the AspectWerkz AOP framework and committer to the Eclipse AspectJ 5 project.





