Apache Drill case study: A tutorial on processing CSV files
Rob Terpilowski decided to take Apache Drill for a test drive and use it for processing CSV files. Here's a quick tutorial to show how you can do it to.
Apache Drill claims that it can query just about any nonrelational data store, from processing CSV files, dealing with popular NoSQL databases like Amazon S3, working with big data stores like MongoDB and even standard flat files that sit scattered across an operating system's folder structure.
A current client of mine generates a Brobdingnagian log file containing data related to the latency of messages traversing the JMS-based messaging system. Latency statistics for each client are logged to the file in CSV format, making this data the perfect case study for testing out the veracity of Apache Drill in a scenario where the toll extracts data out of the CSV file allowing for latency data to be analyzed. What follows is the set of steps that were performed to install Apache Drill and subsequently evaluate its usefulness.
Installation and configuration of Apache Drill
Apache Drill requires a JRE installed on the machine running it. Here is the output of the version command of the JRE describing the installed version.

Obtaining the tool is just a matter of downloading Drill from the Apache website and untarring the compressed file.

With access to the Drill binaries, the Drill-embedded process can be started by invoking it from the bin directory of the installation.

If installation and configuration are successful, Drill will output an eye-rolling "message of the day" followed by a in input prompt in the format of: drill:zk=local>Processing CSV files.
Apache Drill claims that it query just about any nonrelational data store.
To configure Drill to read CSV files, the process is to create a new storage plug-in. By default, the manager web app is also available. This is the server where Drill is running. Dfs is a data store type that points at the local filesystem, so one named "MyCsvData" is created.
After creating the dfs data store, the tool prompts you to supply a configuration for the new data source in JSON format.
To configure access to a CSV files with an extension of .txt in /var/log/jms-jmx-data/output-jms-jmx the following JSON configuration can be used.

Notice that the workspace name is root. This name combines with the dfs name to create a new database with the name MyCsvData.root. After the configuration update is completed, the newly created MyCsvData.root database appears.
The use command can be used to instruct Drill to use the newly created database.
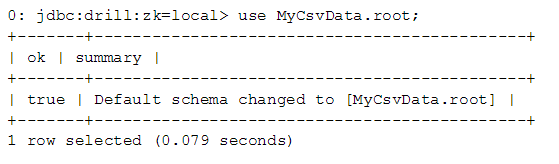
Viewing the files in the database, this use case generated an output.txt file of about 56 MB in length.
By running a select count(*) query we discover that 171,290 records are in the file.

Another select query can show us what a given record contains.
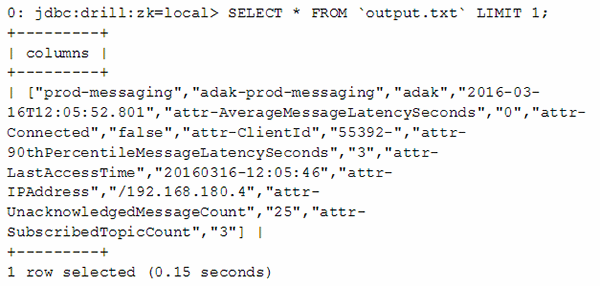
Each record contains statistics related to clients connected to our messaging server, with the client ID, and its 90th percentile latency being of particular interest. Columns can be selected in SQL using the column index. The particular fields we are interested in follow the "attr-Client" field and the "attr-90thPercentileMessageLatencySeconds" field, corresponding to columns nine and 11 respectively.
The following query checks to make sure the column index is correct:

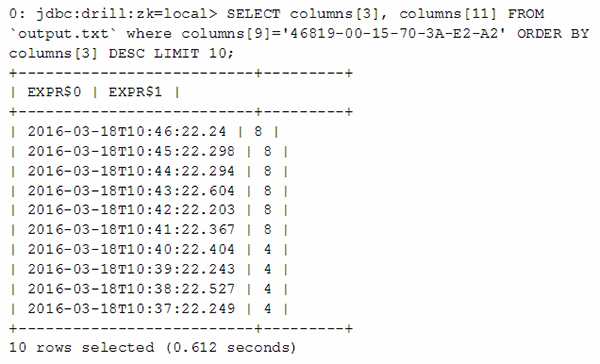
Finally, a select statement queries for latency stats pertaining to client 46819-00-15-70-3A-E2-A2, all of which is ordered with the newest records first.
Output Query Results to a CSV File
To output the results of the query to a CSV file, the following commands are used:

The output of the above command will be placed into the /tmp/my_output directory on your server. Below is a view into the /tmp/my_output directory, which shows the 0_0_0.csv file that contains the results of the query.

And that's it. There are many more database and file types that Apache Drill supports, so explore the Drill website and you will inevitably be amazed by what it can do with your NoSQL database, big data storage systems and even flat files stored directly on your computer's hard drive.
What interesting applications have you found Apache Drill ideal for? Let us know.
Next Steps:
Learn about Apache Spark
What is Apache Camel Spring?
How Hortonworks optimizes Apache Hadoop
Dig Deeper on Front-end, back-end and middle-tier frameworks
-
![]()
18 top big data tools and technologies to know about in 2026
By: Mary Pratt
-
![]()
Braindumps and Exam Dumps for Google's Certified Professional Database Engineer Test
By: Cameron McKenzie
-
![]()
Prep data for machine learning with AWS analytics services
By: Ernesto Marquez
-
![]()
Optimize Amazon Athena performance with these 5 tuning tips
By: Ernesto Marquez



