10 disadvantages of microservices you'll need to overcome
Not everyone is keen to adopt a cloud-native architecture, for good reasons. These common drawbacks to microservices might convince you to stick with your traditional architecture.
Cloud-native architectures built upon Docker- and Kubernetes-based deployments are all the rage today. Teams that adopt microservices can enjoy some clear advantages, such as the following:
- Microservices provide freedom to choose different architectures, languages, processes and tools.
- A microservices architecture codifies many long-evangelized best practices for software components, such as domain-driven design and event-driven architectures.
- Microservices are well encapsulated, and can be revised independently.
- A microservices architecture supports a flexible and potentially shorter release schedule.
- Technologies that support microservices at runtime, such as Docker and Kubernetes, run on commodity hardware.
Nevertheless, app development teams should be wary that microservices do present some significant drawbacks. Before you break down a reliable monolith into a plethora of smaller, functionally identical micro-components, make sure you understand these challenges with a microservices architecture, and how to get around them -- or live with them.
The top 10 disadvantages of microservices fall into the following categories:
- Increased topological complexity.
- The need for automated deployments.
- Complex integration overhead and dependency hell.
- Data translation and incompatibilities.
- Network congestion.
- Decreased performance.
- Increased costs.
- Complex logging and tracing.
- Testing and debugging challenges.
- Organizational inertia.
Increased complexity
When a monolith is broken down into a subset of independent microservices that communicate across a network, this significantly increases the application's architectural complexity.
Let's say you want to break down a single monolithic application into 10 microservices. You now must update the following tasks:
- Scale 10 applications instead of one.
- Secure 10 API endpoints instead of one.
- Administer 10 Git repositories instead of one.
- Build 10 packages instead of one.
- Deploy 10 artifacts instead of one.
It's more difficult to manage a multitude of smaller programs versus a single, solitary, monolithic application. That's one of the biggest drawbacks to microservices.
This article is part of
What are microservices? Everything you need to know
Automated deployment
Microservices bring a lot of value to applications that operate at web scale, but they are also more complex to test, deploy and maintain. This is not manual work -- it must be automated. The sheer volume of services in enterprise-level applications demands this.
Companies that intend to adopt microservices architectures must embrace automation technologies including GitHub, Jenkins and Terraform. Moreover, personnel must possess the expertise to create scripts.
It's an enormous undertaking of time and resources to implement automation in a consistent and comprehensive manner. That's the price companies must pay to expect the benefits of microservices.
Integration overhead and dependency hell
It's a lot of extra work to standardize the data exchange contracts between microservices.
Microservices are developed independently and deployed inside isolated containers. At runtime, all of the isolated and independent microservices must communicate with each other. That means more integration of RESTful endpoints and standardized JSON or XML exchanges.
Furthermore, managing the interdependencies between microservices is a major struggle. RESTful endpoints are exceptionally fragile. Changes to one component can produce unintended consequences for another.
In a monolithic application, components interact directly through Java- or Python-based API calls. There is no need for a common data exchange format or RESTful APIs. Furthermore, all interactions are type-checked and validated at compile time.
Data translation
It would be great if all microservices used the same data structures and communication protocols, but this is often not the case. For example, it's entirely conceivable to have a REST microservice trying to communicate with a gRPC microservice, both using different HTTP protocols. There's a fundamental incompatibility.
One way to overcome such incompatibility is to implement a translation mechanism, such as a proxy (see the figure below).
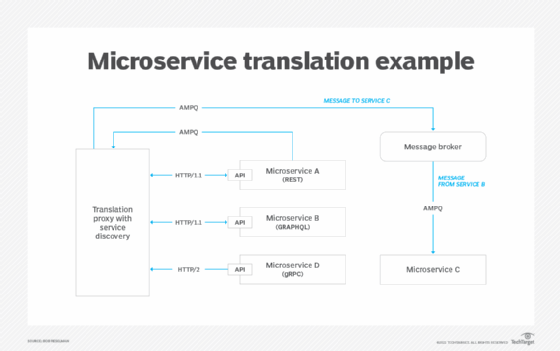
Data translation among microservices can also be a challenge. One service's ZIP code might be another service's postal code.
Data context translation is a problem that's been around for decades. Monolithic applications store all this data in a single database to minimize the issue. A microservices architecture, on the other hand, magnifies the problem -- an application typically accommodates dozens or even hundreds of microservices, and implementing data translation between them can create a significant challenge.
Network congestion
Microservices communicate through RESTful APIs that exchange data in JSON and XML formats. All of these exchanges occur over the HTTP protocol. A formerly quiet network becomes excessively chatty when microservices are introduced. The result is network congestion.
Fortunately, most microservice communications occur within private, local subnets where network bandwidth can be easily increased. However, all of this XML and JSON activity over the network leads to the next drawback of microservices: performance implications.
Decreased performance
A big disadvantage of microservices is that they consume more memory, clock-cycles and network bandwidth than a comparable monolithic architecture.
A monolithic application runs all of its components within the scope of a single process. Interactions between components happen at the hardware level; one component invokes another through a standard method call. The only performance overhead is to schedule each call on the local CPU. Components that execute within the same process share data instantaneously, as it's just a pointer to a reference in memory.
Monoliths vs. microservices compared
Compare those interactions within a monolith to the following scenario: two microservices that communicate with each other across a network.
- First, one component describes its data in a text-based JSON file.
- The component delivers the JSON to the second microservice through a network call.
- That second microservice parses the JSON and extracts the data.
- The second microservice implements the required functionality.
- The second microservice creates its own JSON text file for response data.
- The second microservice issues a new network call to the first calling microservice.
- The first microservice receives and parses the JSON file to extract the response data.
That's a lot of overhead to achieve what happens instantaneously within a monolithic runtime.
The microservices disadvantage of performance and resource usage takes us into the next disadvantage, which is cost.
Increased computing costs
After decomposition, a single monolith broken up into multiple microservices requires the following:
- More total memory to run.
- Duplicate resources when using multiple containers or VMs.
- Extra bandwidth consumption to invoke RESTful web services.
- More CPU cycles to send, parse, read and reassemble JSON files.
Today, enterprises pay for cloud-based computing as if it is a utility. The more CPU or memory an application uses, the bigger the cloud computing bill.
The increased number of resources required to support a microservices architecture as compared to a monolithic one means increased costs. That's a major drawback to microservices.
Complex logging, tracing and auditing
Cloud-native applications are typically deployed into Kubernetes clusters where ephemeral containers provide the required microservices runtime. However, the ephemeral nature of microservices, especially on a multinode network, makes it extremely difficult to log, track and audit them.
If the Docker container that hosts a microservice goes down, the log files are immediately lost unless some daemon process in the background actively moved the log data out of the container and pushed it to a reliable storage location. Tools such as the open source Fluentd help address this problem, but it is still a problem.
With a monolithic architecture, there is one folder on the server to which all of the log, tracing and auditing data is written, and most traditional servers have built-in log rotation mechanisms. It's much easier to manage logging and tracing on a monolith.
The extra work required to manage log files, trace files and audit data across a cloud-native cluster is one of the biggest disadvantages of microservice architectures.
Difficult troubleshooting and problem detection
Troubleshooting problems is difficult with microservices for the same reasons that trace file and log aggregation is difficult. When a failed request is handled by multiple microservices hosted within isolated runtimes, it can be very difficult to track down where the request failed and why. Compare that to a monolithic application where troubleshooting follows the path of a failed request on a single server hosted on a single computer.
Furthermore, it can be cumbersome to replicate the exact path the failed request made, especially when container hosted microservices are constantly spun up and down.
Distributed debugging
Similarly, it's difficult to debug a microservices-architected application. Consider the need to trace the path of a request in and out of an architecture in which potentially hundreds of microservices interact in concert, and each container is independent. This practically necessitates a comprehensive monitoring strategy. Logging the internals of a microservices architecture provides a limited view, but monitoring must see the big picture.
Various tools aim to help debug interservice activity using distributed tracing. Options include open source projects such as Jaeger and Zipkin, and commercial products including Datadog, Dynatrace and Wavefront. No matter what tooling you use, a monitoring strategy is necessary to observe internal and external activity with the various microservices that make up the application.
Organizational inertia
Finally, one of the biggest problems with microservices is how to overcome organizational inertia and convince an enterprise to adopt them.
The transition from monoliths to a microservices-based architecture is a big commitment: new tools to adopt, new development approaches and new skills to learn. Unless there is a compelling reason to go cloud-native and rearchitect a monolith, many organizations think it's easier to just keep doing what works and maintain a monolith into the future.
Compelling arguments will overcome the organizational inertia. If the IT department isn't ready to break down the monolith into microservices, then perhaps the drawbacks to microservices outweigh the benefits -- and that's OK, too. Not every organization is ready or needs to live in the cloud-native world.
There is still a role for monoliths in the modern IT landscape.
Bob Reselman is a software developer, system architect and writer. His expertise ranges from software development technologies to techniques and culture.
Cameron McKenzie has been a Java EE software engineer for 20 years. His current specialties include Agile development, DevOps and container-based technologies such as Docker, Swarm and Kubernetes.







