
CYCLONEPROJECT - Fotolia
How is asynchronous microservices tracing best accomplished?
How can you trace a tricky workflow in an asynchronous microservices-oriented architecture? Two options include correlation IDs and distributed tracing tools.

With components and APIs provisioned across multiple servers in cloud-based, virtual environments, it's difficult to map out a flow of execution for synchronous interactions where you can clearly define the order of execution.
But tracing distributed microservices with asynchronous request-response cycles raised the difficulty to an even higher level. With the right microservices tracing tools and a little knowledge of how microservices-oriented architectures work, it's possible to solve the challenging distributed microservices tracing puzzle.
Synchronous vs. asynchronous microservices
The synchronous microservices request-response pattern is as follows:
- A request is made to the distributed microservice.
- The microservice handles the request but blocks the client.
- The microservice unblocks the client when it sends back a response.
- When the client receives the response, control flow moves on.
The request-response cycle of an asynchronous microservice is quite different.
With asynchronous exchanges, clients publish events to a message broker. A variety of subscribers then individually pull and act on messages. In most cases there's no guarantee that the subscribers will follow the order that it publishes messages to the broker. While this doesn't usually hurt an application's integrity, and most asynchronous microservices-oriented architectures take the arbitrary nature of the message order into account, it makes it difficult to trace microservices request-response cycles.
However, it doesn't make distributed microservices tracing impossible.
Tracing distributed microservices
One way to trace behavior in an asynchronous microservices-oriented architecture is to use the correlation identifier (ID) pattern. Another way is to use a distributed tracing tool.
The correlation ID is the single, unique identifier that unifies messages that are part of a single workflow.
When a subscriber receives a message from a message broker, it inspects the message header for the presence of the header, x-correlation-id. This header is an extension to standard header attributes, but it has started to gain conventional acceptance in the microservices development community.
If the attribute is present, it will be passed on in the header of any message the current subscriber emits. If it's not present, the subscriber can create one -- usually in the form of a GUID -- and then pass it on just as if the correlation ID was present within the initial message.
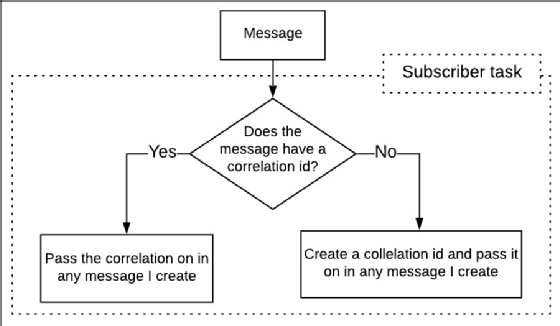
Afterwards, when it's time to analyze or debug a workflow, a developer can look up the messages' log entries based on the specified correlation ID. Once an engineer retrieves all the log entries and associated messages according to correlation ID, they will use logical analysis to get insights into how to properly execute the workflow.
These steps assume that the microservices-oriented architecture's logging policy provides a correlation ID and value to all log entries made by a given microservice associated with the workflow. While some companies are disciplined about correlation IDs, others are less formal. The correlation ID and logging policy must be in sync. If not, teams risk incomplete logging and will only have limited microservices tracing data on their workflows.
Microservices tracing tools
In less reliable situations, it's easier to use a distributed microservices tracing tool that automatically handles the correlation.
A distributed microservices tracing tool observes the messaging activities within a microservices-oriented application and reports those activities in an organized manner. There are many profiling tools available to do distributed tracing. Some, like Java Flight Recorder, are open source, while others require a licensing fee.
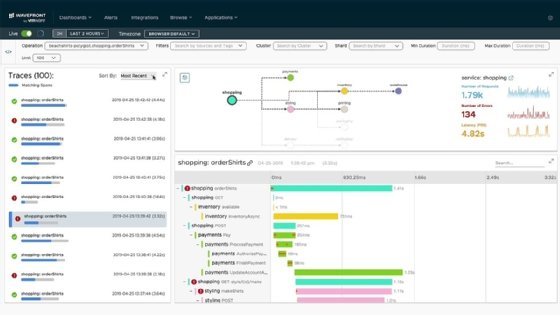
OpenTelemetry is an open source distributed tracing tool that supports asynchronous tracing. The Twitter-developed Zipkin also supports asynchronous tracing. Java Mission Control can also provide insights into how a microservice behaved on a specific Java Virtual Machine.
Some products that require a licensing fee include Datadog's APM and Distributed Tracing tool or VMware's Wavefront.
Troubleshooting problems with distributed microservices is never easy, especially when an asynchronous architecture is in use. But when developers add correlation identifiers into the mix, and possibly incorporate a tool that specializes in data profiling, they can solve the asynchronous, distributed microservices tracing puzzle.






