The difference between precision vs. recall in machine learning

The key difference between recall and precision is that precision accounts for false positives, while recall accounts for false negatives.
There are mathematical formulas to define recall and precision, but if you’re an AI architect it’s much more important to understand what they mean in practice.
Precision vs. recall
In basic terms, precision answers the question: When my model predicts something as positive, how often is it correct?
Recall answers the question: Out of all the actual positives that exist, how many did my model successfully find?
Imagine I added a newsletter to my website and predicted 20 out of 100 visitors would sign up. And indeed, 20 visitors did sign up.
The precision is 100%. Every sign-up was predicted, and we didn’t incorrectly predict more sign-ups than actually happened.
The recall is 100% as well. We found all the sign-ups. We didn’t miss anyone.
That’s the perfect model. But models are rarely so perfect.
Example of high recall and low precision
Now let’s say another model predicts that if the site gets 100 visitors, all 100 will subscribe — but in reality, only 20 actually sign up.
The precision is only 20% because the model was wrong 80% of the time. There were 80 false positives, which are part of the precision calculation.
precision = true positives ÷ (true positives + false positives)
However, the recall is 100%. Of all the actual sign-ups, the model caught every one. It was never incorrect about someone not signing up, so there were no false negatives.
recall = true positives ÷ (true positives + false negatives)
So in this case:
Precision = 20 ÷ (20 + 80) = 20% Recall = 20 ÷ (20 + 0) = 100%
This model has perfect recall but horrible precision.
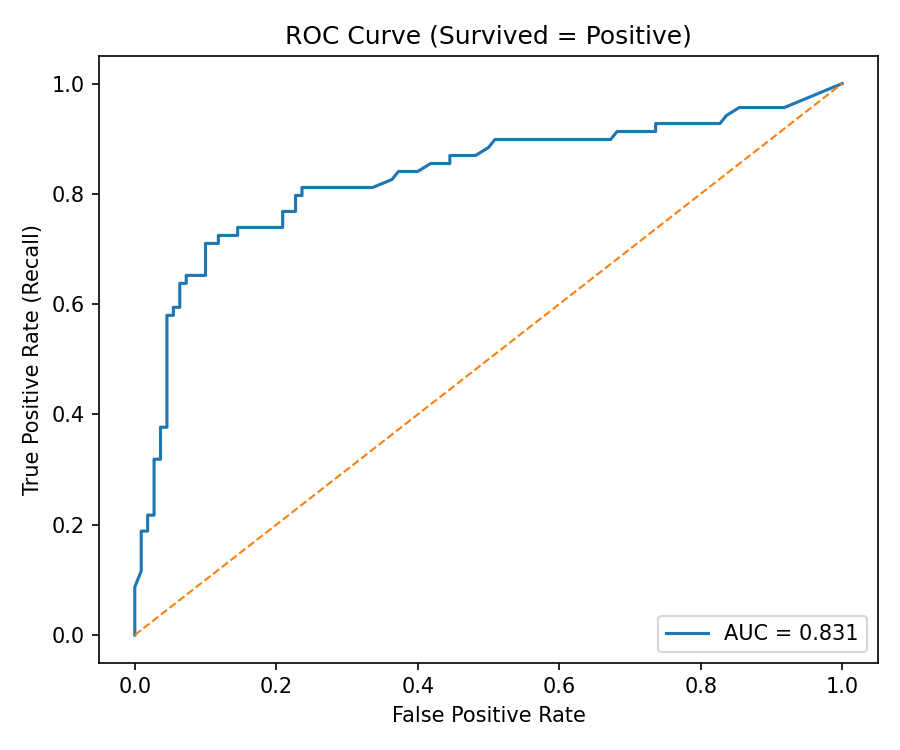
An ROC curve shows how much better a model is compared to random guessing.
Example of high precision with low recall
Now let’s say we’ve retrained our model and it predicts that of the first 100 visitors, only 1 will sign up. However, when we re-launch the site we get 20 sign-ups, not just the predicted one.
The model sucks, even though the precision is perfect since there are no false positives. Any time the model predicts something as positive, it’s correct.
But if the precision is perfect, how can we say the retrained model sucks? It’s because the recall is terrible.
The retrained model only caught 1 of the 20 sign-ups. From this perspective, the model was only right 5% of the time.
Here’s how the confusion matrix fills out:
- True positives: 1
- False negatives: 19
- False positives: 0
- True negatives: 80
So in this case:
Precision = 1 ÷ (1 + 0) = 100% Recall = 1 ÷ (1 + 19) = 5%
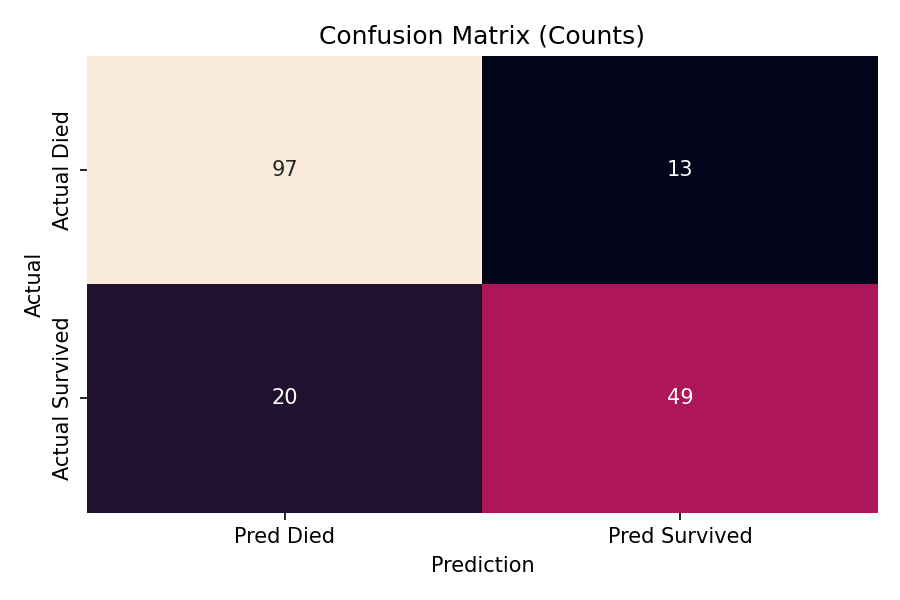
A confusion matrix plots false positives and negatives.
Striking a balance
In the real world, the goal is to strike a balance between precision and recall, while striving for high values for both.
We don’t want conservative models that have high precision but low recall.
And we don’t want overly permissive models that have high recall but low precision.
The goal is to find that Goldilocks zone where both recall and precision are high.
And that’s exactly what being an AI architect is all about: finding the right algorithms, weights, and data inputs to generate models that deliver the best combination of recall and precision.

Cameron McKenzie is an AWS Certified AI Practitioner, Machine Learning Engineer, Solutions Architect and author of many popular books in the software development and Cloud Computing space. His growing YouTube channel training devs in Java, Spring, AI and ML has well over 30,000 subscribers.
Next Steps

The AWS Solutions Architect Book of Exam Questions by Cameron McKenzie
So what’s next? A great way to secure your employment or even open the door to new opportunities is to get certified. If you’re interested in AWS products, here are a few great resources to help you get Cloud Practitioner, Solution Architect, Machine Learning and DevOps certified from AWS:
- AWS Certified Cloud Practitioner Book of Exam Questions
- AWS Certified Developer Associate Book of Exam Questions
- AWS Certified AI Practitioner Book of Exam Questions & Answers
- AWS Certified Machine Learning Associate Book of Exam Questions
- AWS Certified DevOps Professional Book of Exam Questions
- AWS Certified Data Engineer Associate Book of Exam Questions
- AWS Certified Solutions Architect Associate Book of Exam Questions
Put your career on overdrive and get AWS certified today!