Scaling Your Java EE Applications
In this article, Wang Yu takes real world cases as examples to explain ways on how to scale Java applications based on his experiences on the laboratory projects, and at the same time, bring together practice, science, algorithms, frameworks, and experience on failed projects, to help readers on building high scalable Java applications.
If an application is useful, then the network of users will grow crazily fast at some point. As more and more mission-critical applications are now running on Java EE, many Java developers are caring about scalability issues. However, most of popular Web 2.0 sites are built with script languages, and there are a lot of voices to doubt the scalability of Java Applications. In this article, Wang Yu takes real world cases as examples to explain ways on how to scale Java applications based on his experiences on the laboratory projects, and at the same time, bring together practice, science, algorithms, frameworks, and experience on failed projects, to help readers on building high scalable Java applications.
I have been working in an internal laboratory for years. This laboratory is always equipped with the latest big servers from our company and is free for our partners to test the performance of their products and solutions. Part of my job is to help them tune the performance on all kinds of the powerful CMT and SMP servers.
In these years, I have helped testing dozens of Java applications in variety of different solutions. Many products are aimed for the same industry domains and have very similar functionalities, but the scalability is so different that some of them can not only scale up on the 64 CPUs servers, but also scale out to more than 20 server nodes, while others can only be running on the machines with no more than 2 CPUs.
The key for the difference lies in the vision of the architect when designing the products. All these scaled-well Java applications were well prepared for the scalability, from the requirement collection phase, system design phase to the implementation phase of the products' life cycle. Your Java application scalability is really based on your vision.
Scalability, as a property of systems, is generally difficult to define, and is often mix-used with "performance". Yes, yes, scalability is closely related with performance, and its purpose is to get high performance. But the measurement for "scalability" is different from "performance". In this article, we will take the definitions from wikipedia:
Scalability is a desirable property of a system, a network, or a process, which indicates its ability to either handle growing amounts of work in a graceful manner, or to be readily enlarged. For example, it can refer to the capability of a system to increase total throughput under an increased load when resources (typically hardware) are added.
To scale vertically (or scale up) means to add resources to a single node in a system, typically involving the addition of CPUs or memory to a single computer. Such vertical scaling of existing systems also enables them to leverage virtualization technology more effectively, as it provides more resources for the hosted set of operating systems and application modules to share.
To scale horizontally (or scale out) means to add more nodes to a system, such as adding a new computer to a distributed software application. An example might be scaling out from one web server system to three. As computer prices drop and performance continues to increase, low cost "commodity" systems can be used for high performance computing applications such as seismic analysis and biotechnology workloads that could in the past only be handled by supercomputers. Hundreds of small computers may be configured in a cluster to obtain aggregate computing power which often exceeds that of traditional RISC processor based scientific computers.
The first installment of this article will discuss scaling Java applications vertically.
How to scale Java EE applications vertically
Many software designers and developers take the functionality as the most important factor in a product while thinking of performance and scalability as add-on features and after-work actions. Most of them believe that expensive hardware can close the gap of the performance issue.
Sometimes they are wrong. Last month, there was an urgent project in our laboratory. After the product failed to meet the performance requirement of their customer in a 4-CPU machine, the partner wanted to test their product in a bigger (8-CPU) server. The result was that the performance was worse than in the 4-CPU server.
Why did this happen? Basically, if your system is a multiprocessed or multithreaded application, and is running out of CPU resources, then your applications will most likely scale well when more CPUs added.
Java technology-based applications embrace threading in a fundamental way. Not only does the Java language facilitate multithreaded applications, but the JVM is a multi-threaded process that provides scheduling and memory management for Java applications. Java applications that can benefit directly from multi-CPU resources include application servers such as BEA's Weblogic, IBM's Websphere, or the open-source Glassfish and Tomcat application server. All applications that use a Java EE application server can immediately benefit from CMT & SMP technology.
But in my laboratory, I found a lot of products cannot make full usage of the CPU resources. Some of them can only occupy no more than 20% CPU resources in an 8-CPU server. Such applications can benefit little when more CPU resources added.
Hot lock is the key enemy of scalability
The primary tool for managing coordination between threads in Java programs is the synchronized keyword. Because of the rules involving cache flushing and invalidation, a synchronized block in the Java language is generally more expensive than the critical section facilities offered by many platforms. Even when a program contains only a single thread running on a single processor, a synchronized method call is still slower than an un-synchronized method call.
To observe the problems caused by the synchronized keyword, just send a QUIT signal to the JVM process, which gives you a thread dump. If you have seen a lot of thread stacks just like the following in the thread dump file, which means that your system hits "Hot Lock" problem.
........... "Thread-0" prio=10 tid=0x08222eb0 nid=0x9 waiting for monitor entry [0xf927b000..0xf927bdb8] at testthread.WaitThread.run(WaitThread.java:39) - waiting to lock <0xef63bf08> (a java.lang.Object) - locked <0xef63beb8> (a java.util.ArrayList) at java.lang.Thread.run(Thread.java:595) .........
The synchronized keyword will force the scheduler to serialize operations on the synchronized block. If many threads compete for the contended synchronizations, and only one thread is executing a synchronized block, then any other threads waiting to enter that block are stalled. If no other threads are available for execution, then processors may sit idle. In such situations, more CPUs can help little on performance.
Hot Lock may involve multiple thread switches and system calls. When multiple threads contend for the same monitor, the JVM has to maintain a queue of threads waiting for that monitor (and this queue must be synchronized across processors), which means more time spent in the JVM or OS code and less time spent in your program code.
To avoid the hot lock problem, following suggestions may be helpful:
Make synchronized blocks as short as possible
When you make the time a thread holds a given lock shorter, the probability that another thread competes with the same lock will become lower. So while you should use synchronization to access shared variables, you should move the thread safe code outside of the synchronized block. Take following code as an example:
Code list 1: public boolean updateSchema(HashMap nodeTree) { synchronized (schema) { String nodeName = (String)nodeTree.get("nodeName"); String nodeAttributes = (List)nodeTree.get("attributes"); if (nodeName == null) return false; else return schema.update(nodeName,nodeAttributes); } }
This piece of code wants to protect the shared variable "schema" when updating it. But the code for getting attribute values is thread safe, and can be moved out of the block, making the synchronized block shorter:
Code list 2: public boolean updateSchema(HashMap nodeTree) { String nodeName = (String)nodeTree.get("nodeName"); String nodeAttributes = (List)nodeTree.get("attributes"); synchronized (schema) { if (nodeName == null) return false; else return schema.update(nodeName,nodeAttributes); } }
Reducing lock granularity
When you are using a "synchronized" marker, you have two choices on its granularity: "method locks" or "block locks". If you put the "synchronized" on a method, you are locking on "this" object implicitly.
Code list 3: public class SchemaManager { private HashMap schema; private HashMap treeNodes; .... public boolean synchronized updateSchema(HashMap nodeTree) { String nodeName = (String)nodeTree.get("nodeName"); String nodeAttributes = (List)nodeTree.get("attributes"); if (nodeName == null) return false; else return schema.update(nodeName,nodeAttributes); } public boolean synchronized updateTreeNodes() { ...... } }
Compared the code with Code list 2, this piece of code is worse, because it locks on the entire object when calling "updateSchema" method. To achieve finer granularity, just lock the "schema" instance variable instead of the all "SchemaManager" instances to enable different methods to be paralleled.
Avoid lock on static methods
The worst solution is to put the "synchronized" keywords on the static methods, which means it will lock on all instances of this class. One of projects tested in our laboratory had been found to have such issues. When tested, we found almost all working threads waiting for a static lock (a Class lock):
-------------------------------- at sun.awt.font.NativeFontWrapper.initializeFont(Native Method) - waiting to lock <0xeae43af0> (a java.lang.Class) at java.awt.Font.initializeFont(Font.java:316) at java.awt.Font.readObject(Font.java:1185) at sun.reflect.GeneratedMethodAccessor147.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25) at java.lang.reflect.Method.invoke(Method.java:324) at java.io.ObjectStreamClass.invokeReadObject(ObjectStreamClass.java:838) at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1736) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1646) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1274) at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1835) at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1759) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1646) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1274) at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1835) at java.io.ObjectInputStream.defaultReadObject(ObjectInputStream.java:452) at com.fr.report.CellElement.readObject(Unknown Source) .........
When using Java2D to generate font objects for the reports, the developers put a native static lock on the "initialize" method. To be fair, this was caused by Sun's JDK 1.4 (Hotspot). After changing to JDK 5.0, the static lock disappeared.
Using lock free data structure in Java SE 5.0
The "synchronized" keyword in Java is simply a relatively coarse-grained coordination mechanism, and as such, is fairly heavy for managing a simple operation such as incrementing a counter or updating a value, like following code:
Code list 4: public class OnlineNumber { private int totalNumber; public synchronized int getTotalNumber() { return totalNumber; } public synchronized int increment() { return ++totalNumber; } public synchronized int decrement() { return --totalNumber; } }
The above code is just locking very simple operations, and the "synchronized" blocks are very short. However, if the lock is heavily contended (threads frequently ask to acquire the lock when it is already held by another thread), throughput can suffer, and contended synchronization can be quite expensive.
Fortunately, in Java SE 5.0 and above, you can write wait-free, lock-free algorithms under the help with hardware synchronization primitives without using native code. Almost all modern processors have instructions for updating shared variables in a way that can either detect or prevent concurrent access from other processors. These instructions are called compare-and-swap, or CAS.
A CAS operation includes three parameters -- a memory location, the expected old value, and a new value. The processor will update the location to the new value if the value that is there matches the expected old value; otherwise it will do nothing. It will return the value that was at that location prior to the CAS instruction. An example way to use CAS for synchronization is as following:
Code list 5: public int increment() { int oldValue = value.getValue(); int newValue = oldValue + 1; while (value.compareAndSwap(oldValue, newValue) != oldValue) oldValue = value.getValue(); return oldValue + 1; }
First, we read a value from the address, then perform a multi-step computation to derive a new value (this example is just increasing by one), and then use CAS to change the value of address from oldValue to the newValue. The CAS succeeds if the value at address has not been changed in the meantime. If another thread did modify the variable at the same time, the CAS operation will fail, but detect it and retry it in a while loop. The best thing of CAS is that it is implemented in hardware and is extremely lightweight. If 100 threads execute this increment()method at the same time, in the worst case each thread will have to retry at most 99 times before the increment is complete.
The java.util.concurrent.atomic package in Java SE 5.0 and above provides classes that support lock-free thread-safe programming on single variables. The atomic variable classes all expose a compare-and-set primitive, which is implemented using the fastest native construct available on the platform. Nine flavors of atomic variables are provided in this package, including: AtomicInteger; AtomicLong; AtomicReference; AtomicBoolean; array forms of atomic integer; long; reference; and atomic marked reference and stamped reference classes, which atomically update a pair of values.
Using an atomic package is easy. To rewrite the increasing method of code list 5:
Code list 6: import java.util.concurrent.atomic.*; .... private AtomicInteger value = new AtomicInteger(0); public int increment() { return value.getAndIncrement(); } ....
Nearly all the classes in the java.util.concurrent package use atomic variables instead of synchronization, either directly or indirectly. Classes like ConcurrentLinkedQueue use atomic variables to directly implement wait-free algorithms, and classes like ConcurrentHashMap use ReentrantLock for locking where needed. ReentrantLock, in turn, uses atomic variables to maintain the queue of threads waiting for the lock.
One successful story about the lock free algorithms is a financial system tested in our laboratory, after replaced the "Vector" data structure with "ConcurrentHashMap", the performance in our CMT machine(8 cores) increased more than 3 times.
Race condition can also cause the scalability problems
Too many "synchronized" keywords will cause the scalability problems. But in some special cases, lack of "synchronized" can also cause the system fail to scale vertically. The lack of "synchronized" can cause race conditions, allowing more than two threads to modify the shared resources at the same time, and may corrupt some shared data. Why do I say it will cause the scalability problem?
Let's take a real world case as an example. This is an ERP system for manufacture, when tested its performance in one of our latest CMT servers (2CPU, 16 cores, 128 strands ), we found the CPU usage was more than 90%. This was a big surprise, because few applications can scale so well in this type of machine. Our excitement just lasted for 5 minutes before we discovered that the average response time was very high and the throughput was unbelievable low. What were these CPUs doing? Weren't they busy? What were they busy with? Through the tracing tools in the OS, we found almost all the CPUs were doing the same thing - "HashMap.get()", and it seemed that all CPUs were in infinite loops. Then we tested this application on diverse servers with different numbers of CPUs. The result was that the more CPUs the server has, the more chances this infinite loop would happen.
The root cause of the infinite loop is on an unprotected shared variable-- a "HashMap" data structure. After added "synchronized" marker to all the access methods, everything was normal. By checking the source code of the "HashMap" (Java SE 5.0), we found there was some potential for such an infinite loop by corrupting its internal structure. As shown as following code, if we make the entries in the HashMap to form a circle, then "e.next()" will never be a null.
Code list 7: public V get(Object key) { if (key == null) return getForNullKey(); int hash = hash(key.hashCode()); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } return null; }
Not only its get() method, but also put() and other methods are all exposed by this risk. Is this a bug of JVM? No, this was reported long time ago (please refer to http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=6423457). Sun engineers didn't think it a bug, but rather suggested the use of "ConcurrentHashMap". So take it into consideration when building a scalable system.
Non-Blocking IO vs. Blocking IO
The java.nio package, which was introduced in Java 1.4, allows developers to achieve greater performance in data processing and offers better scalability. The non-blocking I/O operations provided by NIO allows for Java applications to perform I/O more like what is available in other lower-level languages like C. There are a lot of NIO frameworks currently, such as Mina from Apache and Grizzly from Sun, which are widely used by many projects and products.
During the last 5 months, there were two Java EE projects hold in our laboratory which only wanted to test their products' performance on both traditional blocking-I/O based servers and non-blocking I/O based servers, to see the difference. They chose Tomcat 5 as blocking-I/O based servers, and Glassfish as Non-blocking I/O based servers.
First, they tested a few simple JSP pages and Servlets, got the following result (on a 4-CPUs server):
|
Concurrent Users
|
Average Response Time (ms)
|
|
|
Tomcat
|
Glassfish
|
|
|
5
|
30
|
138
|
|
15
|
35
|
142
|
|
30
|
37
|
142
|
|
50
|
41
|
151
|
|
100
|
65
|
155
|
The performance of Glassfish was far behind Tomcat's according to the test result. The customer doubted about the advantage of non-blocking I/O. Why so many articles and technical reports are telling about the performance and scalability of the NIO?
After tested more scenarios, they changed their mind, for the results showed the power of NIO little by little. What they have tested are:
- More complex scenarios instead of simple JSPs and Servlets, involving EJB, Database, file IO, JMS and transactions.
- Simulating more concurrent users, from 1000 up to 10,000.
- Testing in different hardware environments, from 2CPUs, 4CPUs, up to 16 CPUs.
The figure below shows the results of the testing on a 4-CPU server.
|
|
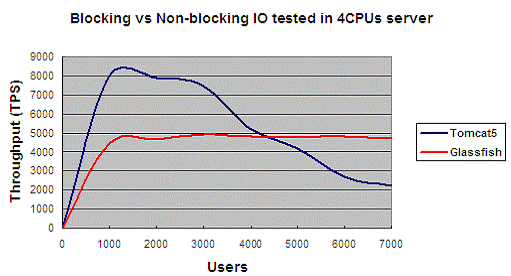
Figure 1: Throughput in a 4CPU server
Traditional blocking I/O will use a dedicated working thread for a coming request. The assigned thread will be responsible for the whole life cycle of the request - reading the request data from the network, decoding the parameters, computing or calling other business logical functions, encoding the result, and sending it out to the requester. Then this thread will return to the thread pool and be reused by other requests. This model in Tomcat 5 is very effective when dealing with simple logical in a small number of concurrent users under perfect network environments.
But if the request involves complex logic, or interacts with outer system such as file systems, database, or a message server, the working thread will be blocked at the most of the processing time to wait for the return of Syscalls or network transfers. The blocking thread will be held by the request until finished, but the operating system will park this thread to relieve the CPU to deal with other requests. If the network between the clients and the server is not very good, the network latency will block the threads longer. Even more, when keep-alive is required, the current working thread will be blocked for a long time after the request processing is finished. To better utilized the CPU resources, more working threads are needed.
Tomcat uses a thread pool, and each request will be served by any idle thread in the thread pool. "maxThreads" decides the maximum number of threads that Tomcat can create to service requests. If we set "maxThreads" too small, we cannot fully utilize the CPU resources, and more important, will get a lot of requests dropped and rejected by the server when concurrent users increases. In this testing, we set "maxThreads" to "1000" (which is too large and unfair to Tomcat). Under such settings, Tomcat will span a lot of threads when concurrent users go up to a high level.
The large number of Java threads will cause the JVM and OS busy with handling scheduling and maintenance work of these threads, instead of processing business logic. More over, more threads will consume more JVM heap memory (each thread stack will occupy some memory), and will cause more frequent garbage collection.
Glassfish doesn't need so many threads. In non-blocking IO, a working thread will not binding to a dedicated request. If one request is blocking due to any reasons, this thread will reuse by other requests, In such way, Glassfish can handle thousands of concurrent users by only tens of working threads. By limiting the threads resources, Non-blocking IO has better scalability (refer to the figure below). That's the reason that Tomcat 6 has embraced non-blocking IO too.
|
|
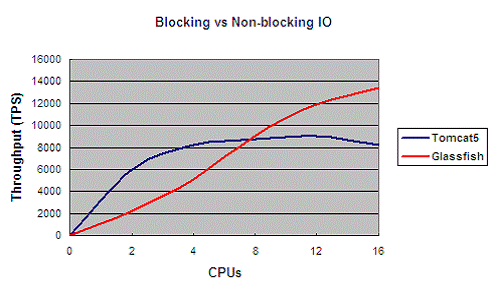
Figure 2: scalability test result
Single thread task problem
A Java EE-based ERP system was tested in our laboratory months ago, and one of its testing scenarios was to generate a very complex annual report. We tested this scenario in different servers and found that the cheapest AMD PC server got the best performance. This AMD server has only two 2.8G HZ CPUs and 4G memory, yet its performance exceeded the expensive 8-CPUs SPARC server shipped with 32G memory.
The reason is because that scenario is a single thread task, which can only be run by a single user (concurrently access by many users is meaningless in this case ). So it can just using one CPU when running. Such a task cannot scale to multi-processors. At the most of time, the frequency of CPU plays the leading role of the performance in such cases.
Parallelization is the solution. To parallelize the single thread task, you must find a certain level of independence in the order of operations, then use multiple threads to achieve the parallelization. In this case, the customer had refined their "annual report generation" task to generate monthly reports first, then generate the annual report based on those 12 monthly reports. "Monthly reports" are just transition results, since such reports are useful for the end users. But "monthly reports" can be generated concurrently and will be used to generate the final report quickly. In this way, this scenario was scaled to 4-CPU SPARC servers very well, and exceeded the AMD server more than 80% on performance.
Re-architecture and re-code the whole solution is a time consuming work and error prone. One of projects in our laboratory used JOMP and achieved parallelization for its single-thread tasks. JOMP is a Java API for thread-based SMP parallel programming. Just like OpenMP, JOMP uses compiler directives to insert parallel programming constructs into a regular program. In a Java program, the JOMP directives take the form of comments beginning with //omp. The JOMP program is run through a precompiler which processes the directives and produces the actual Java program, which is then compiled and executed. JOMP supports most features of OpenMP, including work-sharing parallel loops and parallel sections, shared variables, thread local variables, and reduction variables. The following code is an example of JOMP programming.
Code list 8: Li n k e dLi s t c = new Li n k e dLi s t ( ) ; c . add ( " t h i s " ) ; c . add ( " i s " ) ; c . add ( " a " ) ; c . add ( "demo" ) ; / / #omp p a r a l l e l i t e r a t o r f o r ( S t r i n g s : c ) System . o u t . p r i n t l n ( " s " ) ;
Like most parallelizing compilers, JOMP also focus on loop-level and collection parallelism, studying how to execute different iterations simultaneously. To be parallelized, two iterations shouldn't present any data dependency-that is, neither should rely on calculations that the other one performs.
To write a JOMP program is not an easy work. First, you should familiar with OpenMP directives, and familiar with JVM Memory Model's mapping for those directives, then know your business logic to put the right directives on the right places.
Another choice is to use Parallel Java. Parallel Java, like JOMP, supports most features of OpenMP; but unlike JOMP, PJ's parallel constructs are obtained by instantiating library classes rather than by inserting precompiler directives. Thus, "Parallel Java" needs no extra precompilation step. Parallel Java is not only useful for the parallelization on multiple CPUs, but also for the scalability on multiple nodes. The following code is an example of "Parallel Java" programming.
Code list 9: static double[][] d; new ParallelTeam().execute (new ParallelRegion() { public void run() throws Exception { for (int ii = 0; ii < n; ++ ii) { final int i = ii; execute (0, n-1, new IntegerForLoop() { public void run (int first, int last) { for (int r = first; r <= last; ++ r) { for (int c = 0; c < n; ++ c) { d[r][c] = Math.min (d[r][c], d[r][i] + d[i][c]); } } } }); } } });
Scale Up to More Memory
Memory is an important resource for your applications. Enough memory is critical to performance in any application, especially for database systems and other I/O-focused systems. More memory means larger shared memory space and larger data buffers, to enable applications read more data from the memory instead of slow disks.
Java garbage collection relieves programmers from the burden of freeing allocated memory, in doing so making programmers more productive. The disadvantage of a garbage-collected heap is that it will halt almost all working threads when garbage is collecting. In addition, programmers in a garbage-collected environment have less control over the scheduling of CPU time devoted to freeing objects that are no longer needed. For those near-real-time applications, such as Telco systems and stock trade systems, this kind of delay and less controllable behavior are big risks.
Coming back to the question of whether Java applications scale by given more memory, the answer is yes, sometimes. Too little memory will cause garbage collection to happened too frequently. Enough memory will keep the JVM processing your business logic most of time, instead of collecting garbage.
But it is not always true. A real world case in my laboratory is a Telco system built on a 64-bit JVM. By using a 64-bit JVM, the application can break the limit of 4GB memory usage found in a 32-bit JVM. It was tested on a 4-CPU server with 16GB memory, and they gave 12GB memory to the Java application. In order to improve the performance, they cached more than 3,000,000 objects in memory when initialization to avoid creating too many objects when running. This product was running very fast during the first hour of testing, then suddenly, system halted for more than 30 minutes. We had determined that it was the garbage collection that stopped the system for half an hour.
Garbage collection is the process of reclaiming memory taken up by unreferenced objects. Unreferenced objects are ones the application can no longer reach because all references to them have gone out of extent. If a huge number of live objects exist in the memory (just like the 3,000,000 cached objects), the garbage collection process will take a long time to traverse all these objects. That's why the system halted for such a long and unacceptable time.
In other memory-centric Java applications tested in our laboratory, we found the following characteristics:
- Every request processing action needed big and complex objects
- It kept too many objects into HttpSession for every session.
- The HttpSession timeout was too long, and HttpSession was not explicitly invalidated.
- The thread pool, EJB pool or other objects pool was set too large.
- The objects cache was set too large.
Those kinds of applications don't scale well. When the number of concurrent users increasing, the memory usage of those applications increases largely. If large numbers of live object cannot be recycled in time, the JVM will spend considerable time on garbage collection. On the other hand, if given too much memory (in a 64-bit JVM), the JVM will still spend considerable time on garbage collection after running for a relatively long time.
The conclusion is that Java applications are NOT scalable by given too much memory. In most cases, 3GB memory assigned to Java heap (through "-Xmx" option) is enough (in some operating systems, such as Windows and Linux, you may not be able to use more than 2G memory in a 32-bit JVM). If you have more memory than the JVM can use (memory is cheap these days), please give the memory to the other applications within the same system, or just leave it to the operating system. Most OSs will use spare memory as a data buffer and cache list to improve IO performance.
The Real Time JVM (JSR001) has the ability to let the programmer control memory collection. Applications can use this feature to say to the JVM "Hi, this huge space of memory is my cache, I will take care of it myself, please don't collect it automatically". This functionality can make Java applications scale on the huge memory resources. Hope JVM vendors will bring it into the normal free JVM versions in the near future.
To scale these memory-centric Java applications, you need multiple JVM instances, or multiple machine nodes.
Other Scale Up Problems
Some scalability problems in Java EE applications are not related to themselves. The limitation from external systems sometime will become the bottleneck of scalability. Such bottlenecks may include:
- Database management system: This is the most common bottleneck for most of enterprise and Web 2.0 applications, for the database is normally shared by the JVM threads. So effectiveness of database access, and the isolation levels between database transactions will affect the scalability significantly. We have seen a lot of projects where most of the business logic resides in the database in terms of stored procedures, while keeping the Web tier very lightweight just to perform simple data filtering actions and process the stored procedures in database. This architecture is causing a lot of issues with respect to scalability as the number of requests grow.
- Disk IO and Network IO
- Operating System: Sometimes the scalability bottleneck may lie in the limitation of the operating system. For example, putting too many files under the same directory can cause file systems to slow when creating and finding a file.
- Synchronous logging: This is a common problem about scalability. In some of the cases, the problem was solved by using a logging server such as Apache log4j. Others have used JMS messages to convert synchronous logging to asynchronous one.
These are not only problems for Java EE applications, but for all systems on any platform. To resolve these problems need help from database administrators, system engineers and network analyzers on all the levels of the systems.
The second installment of this article will discuss problems with scaling horizontally.
About the Author
Wang Yu presently works for ISVE group of Sun Microsystems as a Java technology engineer and technology architecture consultant. His duties include supporting local ISVs, evangelizing and consulting on important Java technologies such as Java EE, EJB, JSP/Servlet, JMS, Web services technologies. He can be reached at [email protected].






