Defining Your Object Model with JPA
In the perfect world, your object model would map seamlessly to your database schema. Most organizations however, have database naming standards, requirements for how relationships are modeled and columns that all tables must have.
In the perfect world, your object model would map seamlessly to your database schema. Most organizations however, have database naming standards, requirements for how relationships are modeled and columns that all tables must have.
The following example will show how to use JPA in a real-world scenario. You’ve been asked to quickly mock up a simple blog application; here are your constraints:
- All database table names are uppercase, words separated by an underscore (“_”)
- All table columns must start with the table name, or its initials
- All mutable tables need to track who created and updated a row and when the insert and update occurred
- Object relationships need to be managed intelligently
- You should use as few trips as possible to the database to make sure we can handle current and future load
The application should include the following objects:
- User
- Blog entry
- Comments
- The comments need to support nesting, so a user can reply to another’s comment, there is no limit to the nesting
- You need to list all users who start comment threads, comments without responses, etc.
Here is one possible object model:
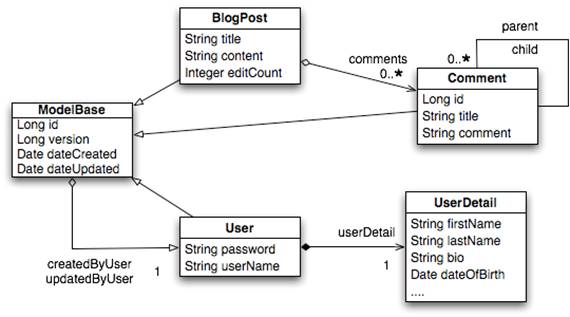
Figure 1: Blog Object Model
ModelBase is an abstract superclass of three entities: BlogPost, Comment, and User. It also defines fields for who created and modified each entity and when the changes occurred. The nested comment requirement is taken care of by Comment’s parent and child relationships.
The database schema for the object model is:
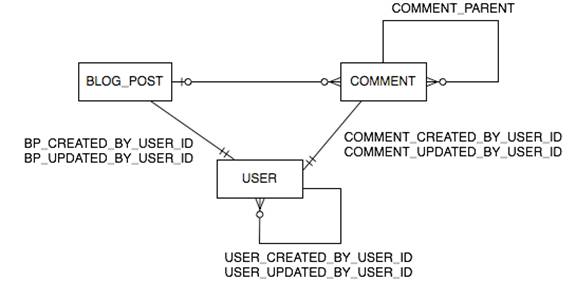
Figure 2: Blog Entity Relationship Diagram
The database tables can be seen here:
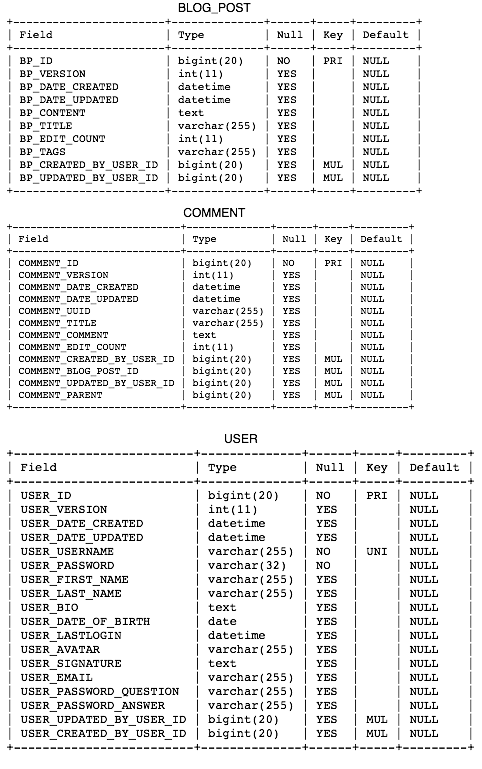
The root object of the class hierarchy is ModeBase. The @Column annotation maps each field in ModelBase to a database table column. The problem is, ModelBase does not follow the database naming conventions listed above. This will be fixed with the concrete class definitions a little later. Here is ModelBase:
1 import javax.persistence.*;
2
3 @MappedSuperclass
4 @EntityListeners({ModelListener.class})
5 public abstract class ModelBase {
6
7 @Id
8 @GeneratedValue(strategy = GenerationType.IDENTITY)
9 @Column(name="id")
10 private Long id;
11
12 @Version
13 @Column(name="version")
14 private Integer version;
15
16 @ManyToOne(fetch=FetchType.LAZY, cascade=CascadeType.ALL)
17 @JoinColumn(name="created_by_user_id")
18 private User createdByUser;
19
20 @Temporal(value = TemporalType.TIMESTAMP)
21 @Column(name = "date_created", nullable = false)
22 private Date dateCreated;
23
24 @ManyToOne(fetch=FetchType.LAZY)
25 @JoinColumn(name="updated_by_user_id")
26 private User updatedByUser;
27
28 @Temporal(value = TemporalType.TIMESTAMP)
29 @Column(name = "date_updated", nullable = false)
30 private Date dateUpdated;
31
32 // methods removed for readability
33 }
ModelBase uses the @MappedSuperclass annotation to tell the JPA persistence provide that this object is not an entity but it’s fields will be included in each entities table (for the entities that subclass ModelBase). You can use a mapped superclass to define all common fields. In this case it defines a field for optimist locking, version, primary key, id and fields for date created and updated. The second annotation, @EntityListener defines a class to be called by the JPA persistence provider at various lifecycle events. ModelListener, sets the user who created and modified each entity and when it was created and updated. Here is ModelListener:
1 public class ModelListener {
2
3 @PrePersist
4 public void setDatesAndUser(ModelBase modelBase) {
5
6 // set createdBy and updatedBy User information
7 User currentUser = UserUtil.getCurrentUser();
8
9 // check to see if modelBase and currentUser are
10 // the same, if so, make currentUser modelBase.
11 if (modelBase.equals(currentUser)) {
12 currentUser = (User) modelBase;
13 }
14
15 if (currentUser != null) {
16 if (modelBase.getCreatedByUser() == null) {
17 modelBase.setCreatedByUser(currentUser);
18 }
19 modelBase.setUpdatedByUser(currentUser);
20 }
21
22 // set dateCreated and dateUpdated fields
23 Date now = new Date();
24 if (modelBase.getDateCreated() == null) {
25 modelBase.setDateCreated(now);
26 }
27 modelBase.setDateUpdated(now);
28 }
29 }
ModelListener has only one method, setDatesAndUser(ModelBase modelBase). This method is tied to the pre-persist entity lifecycle event and will always be called just before an entity is persisted to the database. This gives us a convenient way to set when and by whom the object is created and updated.
JPA requires that entity listeners be stateless and therefore we need a way to establish who the current user of our system is so we can set the createdByUser and updatedByUser fields. The UserUtil class uses a ThreadLocal to store the current user and provides an easy way for clients to establish the “current” user of the system.
1 public class UserUtil {
2
3 private static ThreadLocal<User> currentUser =
4 new ThreadLocal<User>();
5
6 public static void setCurrentUser(User user) {
7 currentUser.set(user);
8 }
9
10 public static User getCurrentUser() {
11 return currentUser.get();
12 }
13 }
If you want to turn off any inherited entity listeners for a particular entity, you can use @ExcludeSuperclassListeners. This annotation does not have any elements, you add it to your entity like this:
1 @ExcludeDefaultListeners 2 public class Comment extends ModelBase implements Serializable
Now, Comment will not be passed to ModelListener when it’s persisted.
There are a couple of drawbacks to using entity listeners, most notably the lack of any lifecycle methods for the listener itself, it must be stateless, and it must have a public no-arg constructor. If you can live with these restrictions entity listeners are a good way to hook into the JPA entity lifecycle.
JPA also supports callback methods, these are methods in your object model class itself and must have the following method signature: void methodName(). Use the entity lifecycle event annotations (e.g. @PrePersist or @PostPersist) to indicate which event the callback method participates in. Here is an example of a callback method (continuing with the example of Comment turning off it’s entity listeners):
1 @ExcludeDefaultListeners
2 public class Comment extends ModelBase implements Serializable {
3
4 // code removed for readability
5
6 @PrePersist
7 public void setDates() {
8 Date now = new Date();
9 if (getDateCreated() == null) {
10 setDateCreated(now);
11 }
12 setDateUpdated(now);
13 }
14 }
By default, an entities table name is the same as the entity itself. In the case of BlogPost, the default table name would be BlogPost. To explicitly set the table name an entity is mapped to, use the @Table annotation. To change the column mappings defined in ModelBase, use @AttributeOverride. If you need to override more than one field, use the @AttributeOverrides (plural) annotation. Here is how you change the mappings:
1 @Entity
2 @Table(name = "BLOG_POST")
3 @AttributeOverrides( { @AttributeOverride(name = "id", column = @Column(name = "BP_ID")),
4 @AttributeOverride(name="version", column=@Column(name="BP_VERSION")),
5 @AttributeOverride(name="dateCreated", column=@Column(name="BP_DATE_CREATED")),
6 @AttributeOverride(name="dateUpdated", column=@Column(name="BP_DATE_UPDATED"))
7 })
8 public class BlogPost extends ModelBase implements Serializable {
The two remaining fields to remap from ModelBase are not attributes but associations, so you need to use a different set of annotations, @AssociationOverrides (plural) and @AssociationOverride. Here is how you rename the createdByUser and updatedByUser foreign key columns in the BlogPost entity:
1 @AssociationOverrides( {
2 @AssociationOverride(name="createdByUser",
3 joinColumns=@JoinColumn(name="BP_CREATED_BY_USER_ID")),
4
5 @AssociationOverride(name="updatedByUser",
6 joinColumns=@JoinColumn(name="BP_UPDATED_BY_USER_ID"))
7 })
As you can see, the @AssociationOverride annotation is a little be more complex than @AttributeOverride because it has a nested annotation, @JoinColumn.
As you can see in Figure 1, there are three more fields to be defined in BlogPost. Here is their definition:
1 @Lob 2 @Column(name = "BP_CONTENT") 3 private String content; 4 5 @Column(name="BP_TITLE") 6 private String title; 7 8 @Column(name = "BP_EDIT_COUNT") 9 private Integer editCount;
The @Lob annotation tells the persistence provider that content is bound to a large object type column. The @Column annotation defines the column name the content field is mapped to. Use the @Column annotation to map an entities field to a specific column name.
One last thing to look at is BlogPost’s relationship to Comment. Here is how the comments field is defined:
1 @OneToMany(cascade={CascadeType.PERSIST,CascadeType.MERGE},
2 fetch=FetchType.LAZY)
3 @Cascade(org.hibernate.annotations.CascadeType.DELETE_ORPHAN)
4 private List<Comment> comments = new ArrayList<Comment>();
The OneToMany annotation tells the persistence provider this is an association and not an attribute. The cascade element tells the persistence provider to persist or merge any comments associated with this instance when blog post is persisted or merged. Unfortunately, JPA does not provide a cascade type for managing orphaned deletes. Fortunately, the Hibernate team has created a set of Hibernate extension annotations to make managing relationships (and every other aspect of an entity) easier. The delete orphan cascade annotation lets Hibernate know it can delete a row from the comment table if a comment is removed from the comments list. Without this annotation, you would have to manually delete the removed comment.
There are two ways for the persistence provider to map a one-to-many relationship in the database. One is to use a join table (a unidirectional relationship) and the other is to have a foreign key column in the many side of the relationship (a bidirectional relationship). Given the BlogPost to Comment relationship, if you just defined the blog post to comment relationship as shown above, JPA should expect the following tables in the database:
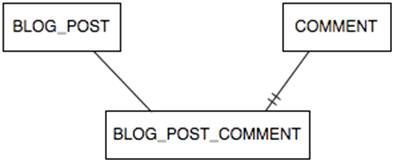
Figure 3: Blog Post to Comment join table
You eliminate the join table, BlogPost_Comment, by defining a bidirectional relationship. To tell JPA this is a bidirectional relationship, you need to add the mappedBy element to the @OneToMany annotation like this:
1 @OneToMany(cascade={CascadeType.PERSIST,CascadeType.MERGE},
2 fetch=FetchType.LAZY, mappedBy="blogPost")
3 @Cascade(org.hibernate.annotations.CascadeType.DELETE_ORPHAN)
4 private List<Comment> comments = new ArrayList<Comment>();
The mappedBy element indicates the owning-side of the relationship, or the field in Comment that will hold a reference to BlogPost. Here is the comment side of the relationship:
1 @ManyToOne 2 @JoinColumn(name="COMMENT_BLOG_POST_ID") 3 private BlogPost blogPost;
By defining the post to comments relationship this way we eliminate the need for a join table.
The Comment entity has the same attribute and association overrides as BlogPost (mapping to different column names of course), however it has an interesting relationship to itself. Comments support nested comments, so a comment can contain a list of responses to itself. To create this relationship, Comment needs two fields, one for the collection of comments and another to represent the parent comment. Here is how the fields are defined:
1 @ManyToOne
2 @JoinColumn(name="COMMENT_PARENT")
3 private Comment parent;
4
5 @OneToMany(mappedBy="parent",
6 cascade={CascadeType.MERGE, CascadeType.PERSIST})
7 @OrderBy("dateCreated DESC")
8 private List<Comment> children = new ArrayList<Comment>();
These relationships are the same as any other one-to-many bidirectional relationship between BlogPost and Comment; the only difference is both sides of the relationship are in the same class. The parent field holds the primary key of the parent comment.
Now that you have the fields defined, you need to add methods to manage the relationship. Both sides of the relationship need to be set in order for the Comment entity to behave properly. To ensure the relationship is set up correctly the java bean property methods for children need to be slightly modified. Since the JPA annotations used in the Comment entity are field based, the JPA persistence provider does not use property accessor methods to set its state. This means we do not need the public void setChildren(List<Comment> children) method for the persistence provider. In addition, by removing this method clients of our model cannot directly set the collection. Next is the public List<Comment> getChildren() method; like setChildren() this method allows clients to directly modify a comments children. To fix this, make getChildren() return an immutable list, like this:
1 public List<Comment> getChildren() {
2 return Collections.unmodifiableList(children);
3 }
The final step is to define methods to add and remove child comments. Here is the method for adding child comments:
1 public void addChildComment(Comment comment) {
2 if (comment == null) {
3 throw new IllegalArgumentException("child comment is null!");
4 }
5
6 // check to see if comment has a parent
7 if (comment.getParent() != null) {
8 // if there is a parent check to see if it's already
9 // associated to this comment
10 if (comment.getParent().equals(this)) {
11 // if this instance is already the parent, we can just return
12 return;
13 }
14 else {
15 // disconnect post from it's current relationship
16 comment.getParent().children.remove(this);
17 }
18 }
19
20 // make this instance the new parent
21 comment.setParent(this);
22 children.add(comment);
23 }
If you want to add a remove comment method, it might look like this:
1 public void removeChildComment(Comment comment) {
2 if (comment == null) {
3 throw new IllegalArgumentException("child comment is null!");
4 }
5
6 // make sure we are the parent before we break the relationship
7 if (comment.parent != null && comment.getParent().equals(this)) {
8 comment.setParent(null);
9 children.remove(comment);
10 }
11 else {
12 throw new IllegalArgumentException(
13 "child comment not associated with this instance");
14 }
15 }
Not only does this method remove a comment from its parents children collection, it makes sure the parent of comment is this instance. If comment were not associated with this instance, removing it from children would have no affect. However, setting its parent to null would leave a dangling comment in the database.
The last two methods to deal with are getParent() and setParent() . Here is their definition:
1 public Comment getParent() {
2 return parent;
3 }
4
5 private void setParent(Comment parent) {
6 this.parent = parent;
7 }
The addChildComment() method uses setParent() , however; clients of the object model should not be able to change a comments parent. The easiest way to ensure this is to make setParent() private. getParent() is fine the way it is. The pattern used for Comments parent/child relationship can be applied to any bidirectional association in your object model.
Deciding where to put the relationship management methods in a bidirectional relationship is rather arbitrary since the purpose of the methods is to ensure the relationships are established correctly. With one-to-many bidirectional relationships, I tend to put the management methods on the “one” side. In the case of Comment this isn’t obvious, but in the BlogPost to Comment relationship I placed the relationship methods in BlogPost. This seems more natural; you add comments to a blog post, not the other way around. If you have a many-to-many relationship it really doesn’t matter which side has the methods so pick one and restrict the other side.
JPA provides methods for fetching entities by their primary key but it might be a good idea to provide some queries to fetch blog posts and comments by User, count the number of comments and blog posts a user has made, determine which comments do not have child comments, and find all root comments (those without a parent).
JPA provides three different types of queries, dynamic queries, static or named queries, and native queries. Dynamic and static queries use the Java Persistence Query Language and native queries use SQL. A dynamic query is one that is processed at runtime, meaning it is parsed and SQL generated every time it’s created. Static queries are processed when the persistence provider loads your object model. This means static queries are parsed once and reused every time you run the query.
To declare a named or static query, you use the @NamedQuery annotation. If you have more than one named query, you need to use the @NamedQueries annotation. Both annotations can be placed on an entity or mapped superclass and are declared at the class or type level. Query names are global, that is, they are not bound to any entity. As a result, you should use some sort of naming convention. One approach is to prefix every query name with the entity name it’s associated with.
Here are the named queries used in Comment and BlogPost:
1 @NamedQueries({
2 // select comments that do not have parent comments
3 @NamedQuery(name = "comment.rootComments",
4 query = "SELECT c FROM Comment c WHERE c.parent IS NULL"),
5
6 // select comments made by a User
7 @NamedQuery(name = "comment.userComments",
8 query = "SELECT c FROM Comment c WHERE c.createdByUser = :user"),
9
10 // count the number of comments made by a user
11 @NamedQuery(name = "comment.userCount",
12 query = "SELECT COUNT(c) FROM Comment c WHERE c.createdByUser = :user"),
13
14 // select the comments a user made without responses
15 @NamedQuery(name = "comment.noChildren",
16 query = "SELECT c FROM Comment c WHERE c.children IS EMPTY AND c.parent IS NULL AND c.createdByUser = ?1")
17 })
18 public class Comment extends ModelBase implements Serializable{ ... }
19
20
21 @NamedQueries( {
22 @NamedQuery(name = "blogPost.createdByUser",
23 query = "SELECT p FROM BlogPost p WHERE p.createdByUser = ?1"),
24
25 // determine the number of posts a User has made
26 @NamedQuery(name = "blogPost.postCount",
27 query = "SELECT COUNT(p) FROM BlogPost p WHERE p.createdByUser = ?1"),
28
29 // fetch a blog post and eagerly fetch its comments
30 @NamedQuery(name = "blogPost.createdByUserComments",
31 query = "SELECT p FROM BlogPost p JOIN FETCH p.comments as c WHERE p.createdByUser = ?1")
32 })
33 public class BlogPost extends ModelBase implements Serializable { ... }
Each of the above queries uses either positional or named parameters; positional parameters use the “?1” syntax and named parameters use the “:name” syntax. Here is how you would create and execute a static query which uses named parameters:
1 // assume entityManager exists
2 User user = UserUtil.getCurrentUser();
3
4 // Here is the definition of comment.userComments for reference
5 // SELECT c FROM Comment c WHERE c.createdByUser = :user
6
7 Query q = entityManager.createNamedQuery("comment.userComments");
8 q.setParameter("user", user);
9 List results = q.getResultList();
Another query using positional parameters (note: the count function returns a Long):
1 // assume entityManager exists
2 User user = UserUtil.getCurrenstUser();
3
4 // Here is the definition of blogPost.postCount for reference
5 // SELECT COUNT(p) FROM BlogPost p WHERE p.createdByUser = ?1
6
7 Query q = entityManager.createNamedQuery("blogPost.postCount");
8 q.setParameter(1, user);
9 Long result = (Long) q.getSingleResult();
The JPQL has many built in functions and expressions to assist you in working with your object model. If you have not checked out JPQL before, you might be surprised by how powerful it is.
The last query to look at is blogPost.createdByUserComments. This query uses the fetch join operator to eagerly fetch a blog posts’ comments. The BlogPost to Comment association is defined as being LAZY (here is the relationship again):
1 @OneToMany(cascade={CascadeType.PERSIST,CascadeType.MERGE},
2 fetch=FetchType.LAZY, mappedBy="blogPost")
3 @Cascade(org.hibernate.annotations.CascadeType.DELETE_ORPHAN)
4 private List<Comment> comments = new ArrayList<Comment>();
Making the relationship LAZY (by setting the fetch element of the @OneToMany annotation to FetchType.LAZY) enables your application to fetch a blog post, say when a user wants to edit the post, without also fetching all the comments. When you want to fetch the blog post and its comments, you can use the named query, blogPost.createdByUserComments. Sometimes you will want to make a relationship eager, by setting the fetch element of the @OneToMany annotation to FetchType.EAGER, so when you fetch entity “A” the persistence provider will also fetch entity “B”. Having one fetch to get back several objects is more efficient than multiple trips to the database but you will need to decide the correct semantics for each collection in your object model.
If you haven’t looked at JPA before, I hope this short example will encourage you to give it a try. Hibernate’s latest release has excellent JPA support and provides an extensive set of JPA extension annotations.
Biography
Chris Maki is a Principal Software Engineer at Overstock.com. Before joining Overstock.com, Chris was an independent consultant specializing in server-side Java development. He has been designing and building server-side systems for 15 years in C++, Objective-C, and Java.
Chris spent many years working as an enterprise architect specializing in large-scale Java system design and development. In addition to being a Java evangelist, he is an avid proponent of Agile Software Development.
Chris is the President of the Utah Java User Group and a member of the WebBeans (JSR-299) and JPA 2.0 (JSR-317) expert groups.
When Chris isn't playing with his computer, you can find him hanging out with his wonderful wife of 12 years, Nicole, and their three boys, Trenton, Avery, and Brayden. You can find Chris on his blog at https://www.jroller.com/page/cmaki.





