Redirect After Post
This article shows how to design a well-behaved web application using redirection.
All interactive programs provide two basic functions: obtaining user input and displaying the results. Web applications implement this behavior using two HTTP methods: POST and GET respectively. This simple protocol gets broken when application returns web page in response to POST request. Peculiarities of POST method combined with idiosyncrasies of different browsers often lead to unpleasant user experience and may produce incorrect state of server application. This article shows how to design a well-behaved web application using redirection.
Double Submit problem
Two most frequently used HTTP request methods are GET and POST. GET method retrieves resource from a web server. Resource is identified by base location and optional query parameters. Generally, parameters of GET request are used to narrow the result and do not change server state. The same GET request can be sent to the server as many times as needed.
On the contrary, parameters of POST request usually contain input data, which can change state of server application. Same data submitted twice may produce unwanted results, like double withdrawal from a bank account or storing two identical items in a shopping cart of an online store. Submission of the same data more than once in a POST request is undesirable and got its own name: Double Submit problem.
Take the standard use case with HTML FORM submitted to the server. Form data is processed and stored in the database, then server replies with a page containing results of operation.
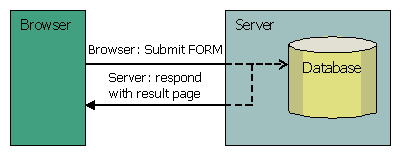
In the above use case the same POST request can be resubmitted using three methods:
- reloading result page using Refresh/Reload browser button (explicit page reload, implicit resubmit of request);
- clicking Back and then Forward browser buttons (implicit page reload and implicit resubmit of request);
- returning back to HTML FORM after submission, and clicking Submit button on the form again (explicit resubmit of request)
Considering the importance of POST data, browsers display a warning when the same POST request is about to be resent to the server. But the message is too technical and obscure for an average user. Also, some browsers do not ask for confirmation at all. Because of that many web sites show their own warnings. How often do you see messages like "Please do not click Back button or refresh this page" after you made an online payment?
The warning messages and confirmation dialogs clutter the interface and make a user feel nervous and uneasy, always afraid to make a mistake. If a web site relies on browser warnings but does not really check for double submit, the server database may become incorrect, while a user would lose confidence in internet transactions.
Is it possible to get rid of irritating warnings? Yes. HTML FORM submission method can be changed from POST to GET. Browsers are not required to ask confirmation when GET request is resubmitted, so this change makes user interface friendlier. But this "solution" breaks the semantic of GET method. It does not prevent resubmitting, it just hides the problem from a user.
The PRG pattern
The answer to double submit problem is redirection. This is a known technique, but it has not become a standard for "after-POST" results yet. As far as I know it does not have a well-known name. I suggest calling it PRG pattern for POST-REDIRECT-GET.
PRG pattern splits one request into two. Instead of returning a result page immediately in response to POST request, server responds with redirect to result page. Browser loads the result page as if it were an separate resource. After all, there are two different tasks to be done. First is to POST input data to the server. Second is to GET output to the client.
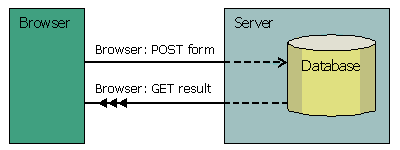
This approach provides a clean Model-View-Controller solution. All input data is stored, permanently or temporarily, in the Model on the server during the first step. The second step loads a View reflecting current Model state. When a user tries to refresh the result page, browser resends an "empty" GET request to the server. This request does not contain any input data and does not change server status. It only loads the View again. If server state was not changed by other processes/users, server responds with the same page as before refresh.
Loading resources using GET method is the cornerstone of suggested approach. Page loaded with GET request can be refreshed safely and transparently. Safely, because no input data is sent to the server. Transparently, because browser does not show warning message. The vehicle which makes transition from POST to GET possible is redirection.
With this technique user experience improves tremendously. No more scary messages with hard to decipher warnings. No trepidation to click Back, Forward or Refresh buttons. No fear to damage server data. Refresh button reloads result page with simple GET request. Back button returns a user to the page with the form. Following click on Forward button reloads the result page using GET again. Absolute freedom of browsing.
But wait, what about clicking on Submit button after returning back to the form page? The form would be resubmitted again, would not it? So all the trouble with redirection just to prevent inadvertent resubmit caused by page refresh?
Keep View Alive
Browsers did not always cache web pages. In the stone ages they were simple. Given the same address they pulled the same resource from the server again and again. Modern browsers are more intelligent. Based on different factors they try to determine should a page be reloaded from a server or not. If not, they can retrieving the page from a cache. For those still using dialup connection this is an instant save in terms of both traffic and time.
But the convenience of caching affects standard behavior. Here is the question: what would a user see if after submitting a form he clicks Back browser button? Did you say that he would see the same form he just submitted with the same values filled in? Why? Because the browser saved the page in the cache in case it would be needed again?
Well, forget smart browsers and caching. How this is for you: each window or page in an interactive application is a View representing an application Model. In order for the View to be correct and consistent with the Model it must be rendered anew each time it is presented to the user.
In plain English: caching must be prohibited for web applications. Online books, dictionaries, pictures can be cached. But please dear browser, do not save snapshots of a live program, because they may not represent actual Model state anymore. It is bad if the saved View is just looked at (you'd rather cache images of naked chicks), but it is tenfold worse when a stale View is used to modify the Model.
Now I ask the same question again: what would a user see if he clicks Back button after submitting a form? You know the correct answer already: the user of a well-designed web application would see a View which represents current Model state. This View would be presented in a way that resubmitting of the same data would be impossible.
New trick for old FORM
Let us take a closer look at the standard use case of an HTML FORM and a result page. The form can be used to edit an existing business entity or a new one. After form is submitted, its data is stored in the database and result of operation is displayed.
According to the PRG pattern, result page must not be returned in response to POST request, because attempt to reload it would cause double submit problem. Instead, browser must load result page separately, using GET method.
We can define the following processing modules (actions in Struts-speak) for this use case: Create Item, Display Item, Store Item and Display Stored.
These modules are combined in input/output pairs:
- Create Item/Display Item - creates new empty item, then shows new item using Item Page HTML form and allows to enter item value;
- Store Item/Display Stored - stores item, then shows persisted item from database in read-only mode on Stored Result page.
- Store Item/Display Item - if fails to store, shows invalid item along with errors using the same HTML form;
- Display Item is used separately to show and update item which already exists in the database.
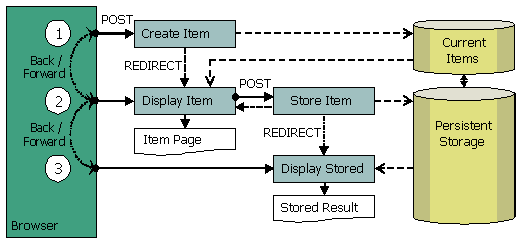
(1) Create Item is called from a link on some other web page when a new object should be created. This action constructs empty business object and stores it in the temporary area called Current Items, which itself can be stored in the database or in the session; then redirects to Display Item.
(2-1) Display Item loads constructed business object from the Current Items and shows it on the Item Page, which is HTML form. The form can be refreshed at any time, browser would just ask Display Item action to obtain and show business object again.
(2-2) User fills out object value and submits HTML form to the Store Item action. If object is not accepted, it is kept in the Current Items area, server redirects back to Display Item action, which reads invalid object along with error messages from the Current Items and redisplays it in the form. If Item Page needs to be is refreshed, it loads the same object from Current Items again.
(3) If the object is accepted by Store Item action, it is persisted in the database and removed from temporary area. After that browser is redirected to Display Stored action which shows the Stored Result page. It can display the object which was just persisted. The result page can be safely refreshed, it would load the object from the database again.
If a user clicks Back button on result page (3) after successfully creating and storing new object, he returns to Display Item action (2). The temporary object has been already removed from the temporary area. Display Item has nothing to show and displays an error page instead of the item form, notifying the user that the object cannot be shown simply because it does not exist anymore. Thus a user cannot resubmit the object again.
Similar situation should happen if during creation of a new object the user leaves the form page (2) to a page preceding it (1). For application that means that the user decided to discard the new object. New object is removed from the Current Items. When the user clicks Forward button and returns to Display Item (2), he would see an "Object not found" error.
Instead of displaying an error page when an object is gone from the temporary area, we can do smarter. Create Item generates unique object ID and redirects to Display Item with object ID as request parameter. Display Item action reads object from the session and compares its ID with the one passed in the argument, then shows object to the user. After the user entered object value and submitted it to the Store Item, object ID becomes the primary key of the object.
Now, when the user returns back from result page (3) after submitting an object, browser invokes Display Item action passing it the same request, which contains object ID (2). Object was removed from the session, but it was stored in the database. Display Item action reads the object from the database, copies it to the Current Items and shows it to the user. Depending on business rules, this object may become read-only, so the form would change to a simple page, showing object content, but not allowing submitting it again. Or, conversely, the form would allow to edit it and submit changes. In the latter case the title of the form would change from "Create New Object" to "Edit Existing Object". If the user submits this object, this is not considered as double submit case. It is an intentional update of existing object.
Editing of existing object is simple, this case is basically already covered. We just need to make sure that Display Item makes no difference between new and existing object. Display Item takes object ID as request parameter, then looks up business object in the Current Items first. If object is not found, it is looked up in the database, copied to temporary area and then displayed (2). After object is updated and submitted, it is stored in the database. When the user clicks Back button from the result page (3), the item form reloads object from the database again (2) so it can be modified and submitted once again. Is this a double submit case? No. It is a deliberate modification of the same object by a user. Of course, you can create all the business rules you want, for example prohibit modification of the same object within certain timeframe.
Let us complete the use case and take a look at how the object is deleted.
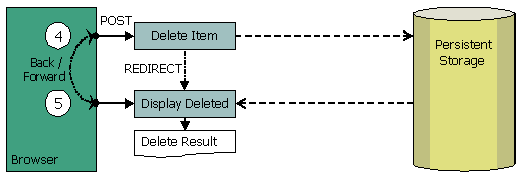
Deletion is simple. Get ID as request parameter, pass it to Delete Item action (4), it deletes object in the Model and redirects to result page (5) which verifies with the database that particular object does not exist anymore. Result page can be safely refreshed without producing another delete request and without warning messages. When Back button is clicked on result page (5), browser returns to the page which invokes Delete Item action (4). If this action is called again with the same object ID, then apply it to the Model, get "object not found" exception, show error page. Again this is not a double submit, this is an explicit attempt to delete the same object again. Big deal, it was already deleted.
I think you got the idea. Just another quick example: an online store.
Storing several identical items in the shopping basket is not a problem while a user is still shopping. It is enough to show the basket content and the quantity of each item. What is really important is to ensure that the payment is processed only once. It may look something like this:
- A shopping basket is created, the unique basket ID is assigned to the basket.
- If a user clicks on Back button after adding an item to the basket, browser reloads up-to-date basket information from the server and shows to the user that the item is already in the basket. It is up to the user to add another identical item.
- When the basket is submitted, its content is sent to a purchasing subsystem; the basket is invalidated; its transaction number is saved in history table if needed and destroyed from application context.
- When a user clicks Back button after purchase was made, browser attempts to load the basket and fails because the basket, its ID and its content already have been destroyed. Browser shows error message instead of the basket. Submitting the same basket twice is impossible.
- In case of caching browser or proxy a user who clicked Back button would see the same basket which was already submitted to purchasing subsystem. User's attempt to resubmit the basket would fail because basket tracking ID has been already destroyed along with the basket itself. As a courtesy for users of caching browsers the server can reply with error stating that the submitted basket does not exist any longer.
The Mantra
PRG pattern can be rephrased like this:
Never show pages in response to POST
Always load pages using GET
Navigate from POST to GET using REDIRECT
Repeat these lines before going to bed.
Think in terms of resources
Desktop applications are presentation-centric. When you select menu item you pretty much know which window would be displayed and how it would look like. Depending on Model state the window may display different information, but the overall window layout would be the same. Desktop user interface is relatively static and is largely defined at development stage.
Web applications should be resource-centric. They can attain greater presentation flexibility instead of fixating on delivering a particular page. Browser should request from a server a resource, a business entity, not a page. Depending on resource availability and state server would generate different presentation for that resource. It can be a regular "read-only" web page, or a form with input controls, or a message that resource is not available or it was permanently removed. Think in terms of resources, not pages.
Work with objects
When you obtain input data, you should know which objects it belongs to. When you display data, you should know content of which object is shown. At any time you must know which object you are working with. Use object ID to load, display and store an object. Pass object ID as request parameter.
Use the session or other short-term server storage as a buffer for currently edited or viewed objects. Ensure that your Views always represent current Model state.
Protect the Model
A web page is only a wrapper of what lies beneath: the Model, the business objects, the database. What is displayed to a user is important, but more important is what is stored in the Model. Protect your Model, nurture it, build all kind of error handling around it. After all, inconsistent user interface is just a nuisance; the chaos begins when the Model blows up.
Model should be accessed and updated using few well-defined ways. Generally, Model should not allow concurrent updates by the same client. Keeping Model valid and up-to-date is the best guarantee from inconsistency between presentation and business/persistence layers.
Define clear business/persistence rules, do not rely on web layer to validate input data. Data can come from anywhere: from a user of your web page, from web-service, from third-party application or from aliens, and all of them cannot be trusted. Validate input data directly in the heart of the application, in the Model.
Prevent resubmits
Include object ID and modification timestamp in a form page, provide time of modification for all business objects in the Model. Use ID to look up business object in the persistent storage, and timestamp to distinguish double submit from a cached page.
Consider applicability of tokens. A token allows to detect a double submit from a stale form page. Token is stored in the session before the form submitted for the first time; the same token value is planted on the HTTP form. When the form is submitted, the token value submitted as well. Application verifies that the token is present in the session, accepts input data, and removes token from the session. If a stale form is resubmitted, the form token would not have its session counterpart anymore. Tokens can be used as a pure web layer solution, Struts have built-in support for tokens.
Model can deal with resubmission more reliably than tokens. If a form is used to add or delete data, apply input values to the Model directly. Properly designed Model would throw insert or delete exception. If a form is used for editing of existing object, compare timestamp on the form with timestamp in the database and do not accept input with timestamp earlier than persisted data.
Controlling data with Model makes things easy. You can notify a user that the data being resubmitted is already in the database. "Thank you, stop clicking that button and refresh the page. The original input form has gone long ago, but your browser still keeps it in the cache."
Prohibit caching of application pages. Insert
<meta HTTP-EQUIV="Pragma" content="no-cache"> and
<meta HTTP-EQUIV="Expires" content="-1">
in your pages. A page would be considered expired right after it loaded from the server.
Separate input from output
Use different classes to process input and output. If you use Struts, create separate input and output form classes, this works very well with two-stage PRG pattern:
- POST request is received by the server
- Struts populates input form class with request parameters
- Input form class validates input data
- Model is updated, information related to current operation is saved in the session for use by consequent GET requests
- Browser is redirected to output action and loads the result page using GET
- Server looks up current object in the session and/or in the Model and fills an output form
- View is created using output form data and is sent back to the browser
You can define only setters in the input form, and only getters in the output form to make form classes easier to read and to ensure that Struts would not populate output form fields with request parameters.
You may want to split large action classes into input an output actions as well.
Use session-scoped UI objects
PRG pattern implies roundtrip to a browser, so the request data is lost. There are two choices to keep POST data: either to transfer it a redirecting response and the in a GET request, or to store it on the server. The first approach is bulky and is non-idempotent. You would have two different kinds of GET request, one to redisplay the HTML form with all its previous data, another to display business object from the database, using just its ID.
Thus, the proper way is to store temporary data on the server and provide GET request with object ID only. That way output action would not even know, was the object just created or loaded from database.
Temporary data corresponds to currently edited or viewed object, and includes both business and presentation data, like:
- object value;
- error messages related to this object;
- page title.
Because this temporary object defines presentation of business object, I call it UI object. If you use Struts, you can use form classes with session scope as UI objects. It is the easiest way to convert regular "forwarding" application into "redirecting" one.
Apparently, the same form class would be used in both input and output actions, so the output action could get access to values set in the input action. The attractiveness of session-scoped form classes is undermined by the fact, that Struts repopulates form fields with each request. This is undesirable, so the mutators would need to verify the name of current action mapping and do not update field values for output action. Struts calls reset method before populating the form, and validate after that. If these methods are used for both input and output, current mapping name should be verified, so the appropriate code could be used.
Session-scoped form classes are kept in memory during client session, which may become an issue. If your form class have references to large objects, you may need to release these objects manually.
Another issue arises when more that one form instance is needed to be created. How this can be done from application code, if form classes are maintained by Struts?
So, despite of the certain convenience of session-scoped form classes I suggest to create your own UI objects. You can have better control over them, you can decide do you want to store them in the session or in database. You will have better abstraction from Struts framework, and porting to other frameworks would be easier.
Form classes are intended for two simple things: deliver input data from HTML form, and render output data on web page. Form classes are just value objects, enhanced with additional functionality like validation. Keep them in request scope, do not use them to store UI or business data.
Struts: use ForwardAction class in output actions
If you have separate input and output form classes, you have got two sets of reset and validate methods. These methods are called by Struts before passing control to an action class. You can use validate in the input form for its original purpose: to verify input data. Output form, on the other hand, does not have much to validate, it is used just to build the result page. So, you can move code from execute method of action class to validate method of output form class and to get rid of custom action class altogether.
Struts: do not expose Views
Views, which are usually JSP pages, must not be available for direct access from a browser. Forget that JSP can process the request. Regard JSP as HTML with data access, use it for output only. Always pass control through action class and/or form class. This ensures clean separation between components and allows Controller to monitor all requests. Hide web pages in WEB-INF directory and display them from their respective actions.
Configure caching
Browsers are not required to process cache control tags on the web pages, but they usually obey HTTP response header fields. Add <controller nocache="true"/> to your struts-config.xml file. Struts would modify each response header as follows:
response.setHeader("Pragma", "No-cache");
response.setHeader("Cache-Control", "no-cache");
response.setDateHeader("Expires", 1);
Corresponding HTTP header fields produced by Tomcat 4.0.6 looks like this:
"Pragma: No-cache"
"Cache-Control: no-cache"
"Expires: Thu, 01 Jan 1970 00:00:00 GMT"
Use better browsers
Despite efforts to prohibit caching some web browsers like Firefox just do not care. Caching works great with simple forwarding applications, preventing implicit resubmits. But caching a page which supposed to reflect current sever state breaks the user experience and introduces the double submit problem again.
Other browsers like Opera can resubmit POST request without confirmation message. This may invalidate state of an application which does not check for double submit, and a user would not even know about it.
Old Netscape Navigator works fine for me, but for some reason it freezes for several seconds when submitting a POST request on Tomcat server. Other browsers do not inhibit this strange behavior.
Internet Explorer does almost everything right, but is very annoying. When you resubmit POST request, it shows you a "Page expired" window first and a dialog box next before allowing to proceed. And if you decide not to, it loses your current page. But because your application would not have resubmit problems, your customers would not suffer much.
Why redirect works
It is interesting that PRG pattern exploits non-standard behavior of browsers and web servers. HTTP 1.1 defines several redirect response codes in 3xx range. Some of these codes require browser to use the same request type, some require to change POST to GET, some require to obtain user confirmation when request is redirected. Turns out that many of these requirements are not implemented by popular browsers. Instead, they have common de-facto behavior, like redirecting POST to GET without confirmation if received 302 code. This feature is used by PRG pattern.
This behavior is wrong for 302 ("Found") code, but is absolutely correct for 303 ("See Other") code. Still, few servers return 303 when redirect with GET method is required. HttpResponse.sendRedirect method does not allow to set response code, it always returns 302. It is possible to emulate sendRedirect(url) behavior using the following methods:
res.setStatus(res.SC_SEE_OTHER);
res.setHeader("Location",url);
where SC_SEE_OTHER is the proper 303 code, but sendRedirect provides some additional service like resolving relative addresses, so this is not a direct snap-in. The discrepancy between browser behavior and HTTP standard can be resolved, if 302 and 303 codes considered equal, and another code for proper 302 behavior were created.
In any case, I doubt that browser vendors will change implementation of 302 response code, because too many applications relay on it. The good thing is that modern browsers understand and correctly process 303 code, so if you want to be sure, return 303 instead of 302.
References
- "GET after POST" by Adam Vandenberg:
http://theflangynews.editthispage.com/stories/storyReader$1118 - "A Fast Introduction to Basic Servlet Programming" by Marty Hall:
https://www.informit.com/articles/article.asp?p=29817&seqNum=7 - "Redirect in response to POST transaction" by A.J.Flavell:
http://ppewww.ph.gla.ac.uk/~flavell/www/post-redirect.html - "Post/Redirect/Get pattern for web applications" by Michael Jouravlev:
https://www.theserverside.com/patterns/thread.tss?thread_id=20936 - "So, You Don't Want To Cache, Huh?" by Joe Burns:
http://www.htmlgoodies.com/beyond/nocache.html - RFC 1945, Hypertext Transfer Protocol -- HTTP/1.0 by T. Berners-Lee, R. Fielding, H. Frystyk:
http://www.ietf.org/rfc/rfc1945.txt - RFC 2616, Hypertext Transfer Protocol -- HTTP/1.1 by R. Fielding, J. Gettys, J. Mogul, H. Frystyk, L. Masinter, P. Leach, T. Berners-Lee:
https://www.w3.org/Protocols/rfc2616/rfc2616.html
About the Author
Michael Jouravlev - I hold MS in Computer Science from Moscow Aviation Institute (technical university), Moscow, Russia. I have more than 10 years of experience developing applications for MS-DOS, Windows and Java platform. I devoted last 5 years to server-side Java applications. Curently I am employed as a software engineer at International Lottery and Totalizator, Inc., www.ilts.com






