Clustering Technologies: In Memory Session Replication in Tomcat 4
In this article we will cover one of the clustering technologies, HTTP session replication, that is used within the J2EE model. There is an example is provided of how session replication can be implemented using Tomcat in conjunction with JavaGroups, a communication protocol which can perform reliable multicast operations to transfer session state between nodes.
Introduction
Many of you have heard the term clustering. It is being thrown around as a buzzword by sales people, developers and just about anybody that deals with J2EE technology. For a lot of people it just remains a buzzword, while others dedicate large amounts of time trying to solve the puzzle.
In this article we will cover one of the clustering technologies, HTTP session replication, that is used within the J2EE model. In the second half of the article, an example is provided of how session replication can be implemented using Tomcat in conjunction with JavaGroups, a communication protocol which can perform reliable multicast operations to transfer session state between nodes. However, let us first begin with a general introduction to clustering.
Clustering - a general idea
A server cluster is a group of application servers that provide a set of shared services. These services could be a storefront that sells merchandise online, an online magazine, web based email or just about anything you see on the Internet today. In order for the service provider to provide the customer (user) with a high quality of service, the service provider can configure its applications in a cluster. Some of the benefits of configuring a cluster are: scalability through load balancing, high availability, and failover.
By using load balancing, the service provider can distribute service requests over a set of servers. This allows the service provider to distribute the load over multiple servers and therefore handle more requests than using a single server. The service provider can further increase the quality of service by adding a high availability algorithm to the cluster. This algorithm allows the load balancing to make sure the server it forwards the request to is available. With load balancing and high availability, we have insured service availability. Additionally, the service provider can add a failover mechanism to the cluster. The failover mechanism allows the cluster to switch/forward the request to another server in the cluster without a disruption in service. For the end user it would mean that service availability and the quality of service is increased.
Clustering in J2EE environments
To implement a cluster (with load balancing, high availability and failover) in a J2EE environment, there are several clustering technologies that have to be implemented. These include, but are not limited to, clustering of the HTTP session, the EJB components, the JMS service, the JNDI service, JDBC data sources and other data connectors.
Since clustering can be implemented at different levels of the J2EE environment, it also allows for many different configurations. One configuration can be an entire J2EE application server running on one server (machine), running more than one server to complete the cluster. Another one can be as shown below, in a completely decoupled J2EE environment where web servers, JSP/servlet engines and EJB servers are all running as separate applications on the same or separate servers.
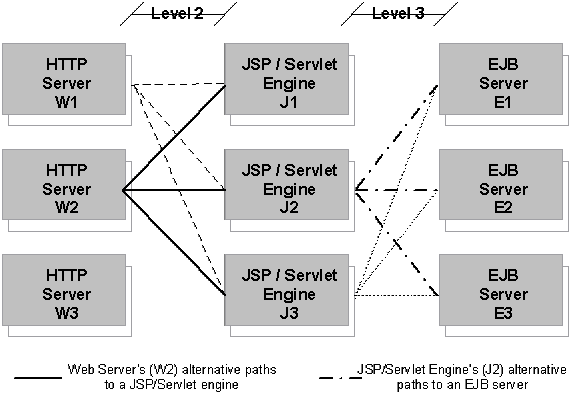
Figure 1. Decoupled clustered J2EE environment
In the decoupled environment there are several stages where load balancing/failover can take place. The first stage is from the client browser to the actual web server, level 1, the second stage is from the web server to the JSP/servlet engine, level 2 in the picture, and so on all the way down to the actual data source if you have any. In this article we will focus on one of the technologies in clustering called session replication. This technology enables stateless load balancing and transparent failover between the web server and the JSP/servlet engine. The article will show an implementation of how this can be done in Tomcat 4.
Introduction to session replication
Session replication is the term that is used when your current service state is being replicated across multiple application instances. Session replication occurs when we replicate the information that is stored in your HttpSession from, in our case, one servlet engine instance to another. This could be data like the items that you have in your shopping cart. It could also be the information that you are entering on an insurance application. Whatever is being stored in your session has to be replicated in order for the service to fail over without a disruption.
If session replication was not in place and the machine that you were connected to crashed, your request would be switched to a working machine, but you would have to start over. If you were on the twelfth page of an insurance application when this happened, you would most likely go to another service provider for your insurance needs. So now that you understand why clustering technology is essential to some of today's web service providers, let's dig into the technical details of an actual implementation.
When a session is replicated between two or more instances, it involves some sort of IO to transfer the data between one instance to the other. One type of replication is to use a database and persistently store a session's state. Then simply have all Tomcat instances read their session information from the database. This configuration works, but not very well. The time to read/write to/from a database is not fast enough so that when a load balanced request comes in, all data may not yet be replicated. A second solution would be to use a shared file system to store session information.
Both of the solutions above introduce problems in terms of speed and dependencies on external IO sources such as the database and the file system. These are also much harder to configure and maintain for system administrators.
A better alternative is to set up your Tomcat servers to use a technique called in-memory-session-replication.
When replicating session information, the system is first and foremost replicating session attributes. These are the data objects that you as a servlet/JSP developer store when you call HttpSession.setAttribute(name,value). In order for the replication to work correctly, any attribute value that you store in the session has to implement the java.io.Serializable interface.
When a session is replicated, the system also has to replicate other stateful session information such as the last time the session was accessed so that it doesn't expire in another cluster node, user login state, session invalidation/expiration. When a new server joins the cluster, the system has to be able to replicate the entire session state from one server to another.
One of the underlying fundamentals of session replication is the communication between the different servers in the cluster. In the example below, I have used a group communication protocol written entirely in Java, called JavaGroups, to perform reliable multicast operations to transfer session state between nodes. JavaGroups is a communication protocol based on the idea of virtual synchrony and probabilistic broadcasting.
Unlike regular multicast protocols, JavaGroups has a highly configurable protocol stack to meet any kind of network/application needs that you might have. A few examples of the different layers in the JavaGroups protocol stack are:
- Fragmentation. This allows you to avoid sending large messages over the wire. The FRAG layer will fragment your large messages into a desired size.
- Ordering. This guarantees that your messages are received in the order they were sent.
- Guaranteed Message delivery. This ensures that no messages are lost.
- Unicast Message. This gives you the ability to send a message to only one node in the cluster.
JavaGroups also has the notion of group membership where you can always know who the members in your group are, and communicate with individual members over the same channel as you do your multicasting (see bullet 4 above).
Since a detailed look at JavaGroups is out of the scope of this document, we will now continue with the configuration of session replication using JavaGroups and Tomcat.
I've built a simple in memory session replication plugin for the latest build of the Tomcat 4 servlet engine, a.k.a. Catalina. In order for me to go through how session replication is actually achieved I will first set you up with a running example.
Installation and Configuration
Binary code download
You will need the following binaries:
Step By Step Installation
When configuring Tomcat for session replication, you will need two instances of Tomcat running. You can either have the instances running on the same machine (different ports), different machines (same ports) or different machines (different ports). Read the Tomcat documentation on how to install and configure your Tomcat servers.
Once you have your instances installed and configured:
- Install and configure Tomcat, you will need two instances running. (I installed mine on localhost:8080 and localhost:8088)
- Install (copy) the cluster binaries (javagroups.jar, tomcat-javagroups.jar) into <TOMCAT_HOME>/server/lib/
- Open the <TOMCAT_HOME>/conf/server.xml file with an editor of your choice Inside your <Context> configuration, you want to paste the following code (if there currently is one
configured, make sure you comment it out): <Manager className="org.apache.catalina.session.InMemoryReplicationManager" protocolStack="UDP(mcast_addr=228.1.2.3;mcast_port=45566;ip_ttl=32) :PING(timeout=3000;num_initial_members=6):FD(timeout=5000): VERIFY_SUSPECT(timeout=1500):pbcast.STABLE (desired_avg_gossip=10000):pbcast.NAKACK(gc_lag=10;retransmit_timeout=3000): UNICAST(timeout=5000;min_wait_time=2000):MERGE2:FRAG:pbcast.GMS (join_timeout=5000;join_retry_timeout=2000;shun=false;print_local_addr=false)"> </Manager>
You can also leave out the protocolStack parameter and you will get the default stack, which is the one that is above.
- Perform the same configuration for all your Tomcat instances. It is important that your protocol stack is identically configured for all instances.
- Restart your Tomcat servers, (if you are running two instances on the same machine, make sure you start them sequentially in order for the JavaGroups to establish group membership properly)
Testing the installation
Supposedly you are now replicating all session information between your servers, but you want to verify this visually. What I did was to setup Apache in front of my Tomcat servers, (I have two instances on the same machine), using mod_proxy. I simply put the following lines in httpd.conf
ProxyRequests On ProxyPass /examples1 http://localhost:8080/examples ProxyPassReverse /examples1 http://localhost:8080/examples ProxyPass /examples2 http://localhost:8088/examples ProxyPassReverse /examples2 http://localhost:8088/examples
Using this Apache configuration, you can simply toggle the browser between http://localhost/examples1/servlet/SessionExample and http://localhost/examples2/servlet/SessionExample. You will see that the two Tomcat servers have identical session information.
You can also test to see if your login state gets replicated by using these urls:
http://localhost/examples1/jsp/security/protected/index.jsp
http://localhost/examples2/jsp/security/protected/index.jsp
If it doesn't work, try multicasting on your machine. Set your classpath to include javagroups.jar and follow the instructions in the JavaGroups manual.
Note! In a real world scenario, this is not how you would do load balancing. . Since Tomcat is an Apache project, you can actually set up Apache to do the load balancing and failover for you. An example of how to configure this is given in Pascal Forget's article Apache 1.3.23 + Tomcat 4.0.2 + Load Balancing.
How in memory session replication works
Let's consider the following cluster configuration and reveal how a clustered HTTP request is processed.
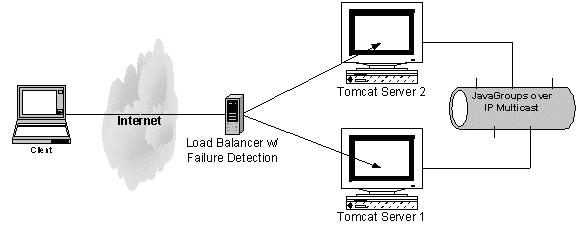
Figure 2. High level overview of a Clustered Tomcat configuration
The initial implementation of the in memory session replication supports the following actions (cluster messages):
- Creation of sessions - when a session is created, the session gets replicated
- Attributes added to the session - the session values get replicated to the other nodes in the cluster
- Attributes removed from the session - the value will get removed from the replicas too
- Session expiration - if a session expires from a node, it will expire everywhere in the cluster
- Last access timestamp update - the session will not expire in the other nodes in the cluster
- Setting the user principal to the session - enabling login state to be replicated
- Complete replication of all sessions - used when a new node joins the cluster
Let's take an example:
Pre requisites:We have two Tomcat servers running, configured to be running in the same cluster. We call these instances TC1 and TC2.
An HTTP request comes in and a load balancer (such as an Apache server) redirects the request to TC1. A session is created in the JSP/servlet. This results in TC1 broadcasting a <session-created-action> message to the other nodes in the cluster, in this case, TC2. TC2 will create a new session and replace the new session id with the one sent by the message. Both TC1 and TC2 have the "same" session in memory.
The JSP/servlet adds an attribute to the session, which results in TC1 broadcasting an
When a third Tomcat instance TC3 is started up on the network, it joins the cluster and requests a list of sessions that are active in the cluster. TC3 sends a <get-all-sessions> message to one of the cluster nodes and requests all sessions. The node responds to TC3 with the information requested.
Post requisites:At this point in time, we have three Tomcat instances in the cluster. Nodes can join the cluster or crash (leave the cluster) at any time. All the nodes in the cluster will have the same session information with the lag time it takes to replicate the data across the network.
When developing the session replication I used JavaGroups as my communication protocol. This is because JavaGroups is highly configurable for all types of network conditions, as mentioned earlier in this article. And trust me, being one of the developers on the JavaGroups project did not influence the choice at all. I created an InMemoryReplicationManager class that extends the standard session manager class in Tomcat. The InMemoryReplicationManager starts a JavaGroups channel, also known as a JChannel when the InMemoryReplicationManager.start() method is called. The JChannel is used to communicate with the other nodes in the cluster. The JChannel has two methods: send(Message) and Object receive(). These two methods are used to send and receive messages within the cluster.
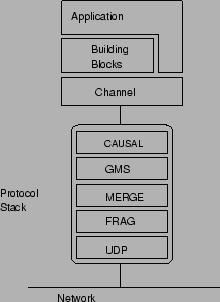
Figure 3. JavaGroups internal layout
The JChannel creates the protocol stack upon creation (InMemoryReplicationManager.start()). It then connects the channel and establishes a group membership, ie, becomes a node in the cluster. When a method is called on the session such as setAttribute(), removeAttribute() on the session, or createSession on the manager, the InMemoryReplication manager broadcasts a message to the other nodes in the cluster to notify them of the state change. The same message also contains data so that the nodes can replicate the state. When a new Tomcat instance is started, it will first replicate all the sessions into its own memory so that it can handle requests in the cluster. To do this, the newly started instance contacts the JavaGroups coordinator (the TC instance that coordinates the group membership, cluster nodes). The coordinator responds with the session information that the new node needs to setup all the sessions in memory before it can handle requests.
Source Code
To implement this functionality, I reused as much as I could from the current session framework. Tomcat/Catalina is a very modular system and is very configurable, and allowed for me to develop a "plug-in" like functionality to enable session replication. I only added four classes and I didn't change one single line of code in the Catalina source tree:
- org.apache.catalina.session.InMemoryReplicationManager extends org.apache.catalina.session.StandardManager
- org.apache.catalina.session.ReplicatedSession extends org.apache.catalina.session.StandardSession
- org.apache.catalina.session.SessionMessage- message used to broadcast session events in the cluster
- org.apache.catalina.session.SerializablePrincipal - a serializable object to wrap a security principal
If you want, you can also download the source code
Conclusion
Although HTTP session replication is only a very small part of J2EE and system clustering, it is potentially one of the most important features that will allow service providers to implement failover without a disruption of the web service. So what does this mean if you are in a technology organization planning to use session replication? Simply put, "nothing". Although I have to be honest, that is not completely true. Session replication will work as long as you store objects that implement the java.io.Serializable interface; however, in most cases you will not get the effect you want. It could be that your application needs some class to have certain class variables (static variables) set, and as you know, class variables do not get serialized by the Java VM. Problems like this could be very hard to debug and can sometimes turn clustering into a complete nightmare.
Here are a few hints that could save you hours of headache and nagging from your boss.
- Always keep your clustered Tomcat instances identically configured
Having different configurations in your cluster can often lead to consequences you can't even imagine. The various configurations of Tomcat usually cause it to behave differently. If you are using session replication, you will want all your instances to behave identically.
- Your session state is all you need
If you want your applications to be able to fail over successfully, then make sure that the session is the only thing that you need to determine the state of in the current request. Storing request data in decentrialized sources such as temporary files, class variables, or other sources will cause your Tomcat instances to be inconsistent.
- Keep your clusters small
Session replication means a lot of network IO. You will want to reduce this IO as much as you can. If you have 18 Tomcat instances, it is better to create 6, maybe even 9 clusters (2-3nodes/cluster) than to create two clusters (9nodes/cluster). The more nodes you have in each cluster, the more data that has to be sent over the wire. Having too many nodes in your cluster can make your cluster to become the bottleneck in your application.
- Be aware of what you store in your session
If you remember from our list of session messages, almost any session modification causes a session message to be sent to the other nodes in the cluster, which means an increase network IO. So avoid storing temporary variables that only last during the request in your session. As much as you can, use the request to store state during a request. See request.setAttribute(), request.getAttribute(). Also, avoid storing large objects in the session. Storing a one megabyte file in a session can cause a serious delay in cluster communication. Although the JavaGroups layer will handle this message and deliver it, any other communication will be halted during the delivery of that message if you have enabled ordering of your messages.
- Design with clustering in mind
Clustering means less bang for the buck in terms of hardware resources and perfomance. Adding a third server to a two-server cluster configuration means that the two original servers have to accommodate for every new session that is being created on the newly added server. For example, having three nodes in a cluster as opposed to two means that each Tomcat instance stores 50% more session data in memory (assuming an equal session load between instances) and the number of replication messages being sent between the instances in the cluster increases. If you design with this in mind you will not only get great cluster performance, but you will also get excellent application performance in a non-clustered environment.
Having the knowledge of what a J2EE cluster is and how it works will not only make you a better programmer or software development manager; it is also an essential part of software development in today's web services environments. Good luck clustering!
References
The JavaGroups Project
Sun.com, a developer's notebook
From BEA, on clustering
JavaSoft, J2EE
Installing Apache as a loadbalancer for Tomcat
About the author
Filip Hanik is one of the developers on the JavaGroups project and has also contributed his knowledge of the Tomcat 3.x internal architecture to a Tomcat book. You can contact him at [email protected] or reach him on the JavaGroups development mailing list.
Note: It is important for me to let you know that this code is not part of the current Tomcat 4.0.x releases, and is at this point not supported by the Tomcat developers. I'm currently working on a proposal that would allow Tomcat to be configured with different messaging systems, so keep checking back.







