
Getty Images
How to choose between REST vs. gRPC
Does your REST API and subsequent JSON or XML data create a bottleneck in your architecture? Perhaps it's time to consider gRPC instead of REST for your web services.

Despite REST's position as the de facto standard in web services development, it's not without some shortcomings. Data exchange formats can be bloated, and it lacks standards for API documentation and publication.
As an alternative for web service design, gRPC has features that improve performance, standardize interactions and make microservices-based development more predictable.
Let's examine the REST vs. gRPC debate and consider why development teams might consider this alternative.
REST's popularity
It's common in today's development world for one company to publish a public REST API and see it used in other third-party applications. For example, The New York Times and U.S. Department of Commerce publish widely used REST APIs that are also used externally.
However, despite this popularity, REST has problems in terms of standardization, performance overhead and streaming capabilities for web service clients. That's where gRPC comes in.
Developed by Google, gRPC, is an API protocol that's intended for applications that need to consume data quickly and continuously. While it's not as simple to use as REST, the potential benefits justify its learning curve.
How REST works
Representational State Transfer, REST, is an architectural style that uses HTTP as the standard communication protocol for working with resources defined in an API. You can think of a resource as an entity similar to an object as used in object-oriented programming.
Just as an object does, a RESTful resource has properties and behaviors. Most implementations of REST tend to focus more on the properties of a resource with little regard to RESTful behaviors. Implementations that describe a RESTful resource only in terms of properties are deemed to be RESTful.
REST APIs and HTTP
Under REST, a resource, or a collection of resources, is described by a URL. The following URL describes a collection of animal resources available at a fictitiously named API, at example.com.
https://api.example.com/animals
REST takes advantage of the HTTP specification to implement getting, adding, modifying and deleting a source in a particular domain by using the HTTP verbs GET, POST, PUT, PATCH and DELETE. Table 1 below shows the HTTP method used most often by developers.

RESTful resources
Thus, using the animal resources described above, if I want to get all the animals available in the API at api.mysimpleapi.com using the curl command-line utility, I would execute the following statement in a terminal window:
curl https://api.mysimpleapi.com/animals
If I want to add an animal to the API, I would make a POST request to the API using curl, like so:
curl -d ' {"species": "Dog", "breed": 'Poodle', "legs": 4 }' -H "Content-Type: application/json" -X POST https://api.mysimpleapi.com/animals
It's important to understand that the REST information exchange architecture uses HTTP as the way to make requests against a REST API. Developers can get, add, modify and delete data using the standard HTTP methods, GET, POST, PUT, PATCH and DELETE.
Web service data exchange formats
REST has been in play for decades. Over time a certain convention has emerged for defining URLs. Typically, the base URL for a resource describes the collection of resources, for example:
/animals/
This URL-based reference to a RESTful resource returns all the animals resources in a data exchange format such as JSON:
[
{ "id": 501, "species": "Dog", "breed": "Terrier", "legs": 4 },
{ "id": 502, "species": "Bird", "breed": "Robin", "legs": 2 },
]
The conventional format for getting a particular resource within the collection is to define the particular resource's unique identifier as the part of the URL definition, like so:
/animals/{id}
WHERE: {id} is the placeholder for the actual unique identifier
Thus, in order to get a particular animal using the example.com API, the URL is written as:
https://api.mysimpleapi.com/animals/501
The result of a GET request to the fictitious Animals API at the URL shown above will be:
{ "id": 501, "species": "Dog", "breed": "Terrier", "legs": 4 }
Figure 1 below illustrates the details for getting a particular resource.
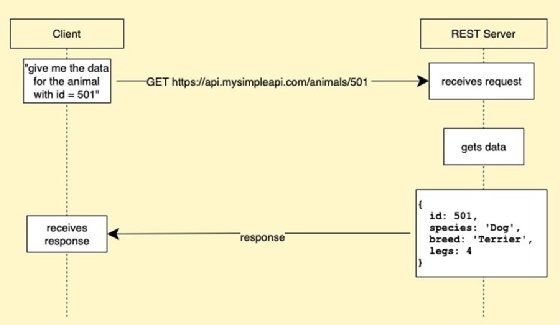
RESTful resource structures
Under REST, there is no requirement to specify the data exchange format before a resource is sent over the network. For better or worse, as long as a REST API emits data in an acceptable format such as JSON, YAML or XML, developers can define an API however they want.
Over the years, there has been a trend to formalize the way REST resources are defined. In the Specification First movement, for example, a developer specifies the API first using a specification format such as OpenAPI or API Blueprint. Then the developer will create the API based on that specification. While having a referenceable specification is good, it is not required.
A responsible developer will publish documentation describing each data structure of each resource in the API using one of the many popular documentation tools, such as SwaggerHub. (My airport codes API on SwaggerHub provides an example.) Sometimes a developer will publish a document describing the API as a Read.me file on a source code repository such as GitHub. This is good.
And then there are times when a developer will not document that API at all and let you figure it out. Such irresponsibility is rare. In those cases, the consumer can always query a REST API's URL on a trial-and-error basis to seek available information.
A developer can make a call to the API and the result will be in a well-known text format such as JSON or XML. No special deciphering is required. It's all text, all the time.
Using a text format, however, comes with overhead. Sending and receiving text over a network can be costly. Each character in a string of text is a byte, so the following JSON-based text string consumes 62 bytes of network data:
{ "id": 501, "species": "Dog", "breed": "Terrier", "legs": 4 }
This is not a big deal when an API is publishing a single resource, but what happens when an API is publishing millions of resources in a collection? The overhead can become significant. This is where gRPC comes to the rescue.
How gRPC works
The gRPC is intended to allow for fast, efficient communication between a source and target. It's based on the Remote Procedure Call (RPC) architecture, through which a source makes a call to a predefined procedure on the target, typically an endpoint.
Both the procedure and the messages sent to a procedure are defined in a specification file. In gRPC, the specification file uses the extension .proto.
The following code shows an example of the specification file, animal.proto. The listing defines a method, GetAnimal() as well as two messages, AnimalRequest and Animal.
Both messages are used in the specification for the method GetAnimal(. A caller using the method GetAnimal() provides an animal id by way of the AnimalRequest message. The method GetAnimal() returns an animal according to the id in the format of an Animal message.
package animalpackage;
syntax = "proto3";
service AnimalCatalog {
// Sends a greeting
rpc GetAnimal (AnimalRequest) returns (Animal) {}
}
// defines a request for an animal
message AnimalRequest {
int32 id = 1;
}
// defines a animal
message Animal {
int32 id = 1;
string species = 2;
string breed = 3;
int32 legs = 4;
}
The essential dynamic of gRPC centers on a source call to a procedure on a target -- with a predefined message -- and receiving a response from that procedure.
Understanding protocol buffers serialization under gRPC
Along with a simplified method invocation syntax, gRPC also allows for improved performance because it makes the data exchange efficient. The main way gRPC handles this simplification is the Protocol Buffers binary serialization format.
Client applications supporting gRPC encode data into bytes of data according to the Protocol Buffers encoding logic, which encodes the message into a binary format. The client sends the data to servers that understand data is exchanged through Protocol Buffers.
After the server processes the request, it will encode a response according to the Protocol Buffers serialization format and send those bytes back to the client. The client then receives and decodes the server's response.
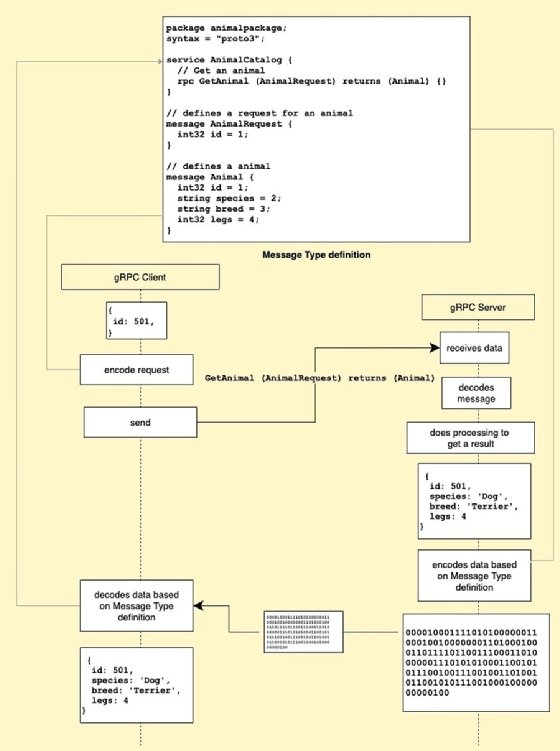
For example, a REST animal resource with this information would be 62 bytes in size and would look like this:
{ id: 501, species: 'Dog', breed: 'Terrier', legs: 4 }
The same JSON string encoded with Protocol Buffers results in a byte array that looks like this and would be only nine bytes in size:
08 f5 03 12 03 44 6f 67 1a 07 54 65 72 72 69 65 72 20 04
Despite the simplified format and smaller size, gRPC isn't appropriate for every circumstance.
REST vs. gRPC
Both REST and gRPC have their place in the IT landscape.
In terms of ease of use, REST wins hands down. When developers use a REST API, it's essentially the same as calling a webpage. To create a REST API, the only tool developers need is an integrated development environment in which they create and launch a web server. As far as consuming a REST API, a developer can use a free tool such as Postman or cURL to configure and execute HTTP calls to an endpoint.
However, REST is bulky and stateless. A REST response sends a lot of data over the network, and most of it has to do with data structure instead of the actual data itself.
In REST, developers can't create a connection to a target and then have the target continuously return data over that connection. Developers must periodically make a call to the API to get that data.
On the other hand, gRPC is designed to support continuous streaming. It uses the HTTP/2 protocol, which has streaming support built in. With HTTP/2, developers can establish a connection to a gRPC-enabled server and then have that server continuously send serialized data in Protocol Buffers back to the client.
The downside of gRPC is that developers need to know a lot of concepts and operations to use it. For example, both the client and the server need to know the .proto file specification. Both use that information to perform encoding and decoding with Protocol Buffers. Unlike REST, developers can't execute a call by entering a URL in a tool and receive back a result in JSON.
There's a lot of encoding and decoding that needs to happen on both the client and server to work with the Protocol Buffers serialization. This encoding and decoding consumes computing resources but results in a lightning-fast data exchange. Understand that you'll need to do a lot more work to make that data meaningful for consumption, whereas under REST, what you see is what you get.
Should you use REST or gRPC?
REST was a transformational architecture when it first appeared more than two decades ago. It standardized data exchange and made it easier for developers to get the data they needed in a well-known, reliable manner. Without REST, what's called the API economy might not be possible.
Even so, REST had a drawback for microservices developers that craved speed. The bulk of REST responses can be a burden on the network. Put enough text in a REST message, and things can get slow -- fast.
For those with a need for speed, there's gRPC. The drawback is that you need to know a lot to use it. An IT shop will need to determine if the rewards are enough to justify the effort that gRPC requires.
Neither architecture can be everything to everyone. The IT industry is so big that there isn't a one-size-fits-all data exchange technology that combines speed and ease of use. Until that time comes, learn the essentials of REST and gRPC to find the right match for your shop.







