
putilov_denis - stock.adobe.com
An introduction to LLM tokenization
Users interact with LLMs through natural language prompts, but under the hood these AI models are based on LLM tokenization. Expand your AI knowledge and skills with this tutorial.

Human interaction with AI and large language models (LLMs) is instigated using natural language prompts. However, the mechanism these systems use to process requests and responses is through tokens, a computational unit that represents a portion of unstructured data such as text in a document or the image in a graphic file.
Understanding the basics of what tokens are and how they're used is important for IT professionals to acquire the skills to become proficient in working with AI in general, and LLMs in particular.
In this article, we'll look at the basic theory behind tokens, how they're constructed and how they are processed by LLMs to return meaningful information to users -- known as LLM tokenization.
Constructing tokens from a natural language prompt
Tokens are numeric values that are derived from a natural language prompt according to the training algorithm, architecture and use case of a particular LLM. Token generation is not standardized; each LLM produces its own set of tokens for a particular language prompt.
Figure 1 below shows the prompt, "What is the weather in Los Angeles?" tokenized by the OpenAI and Mistral LLMs, as reported by the tokenization tool Lunary. Notice that the token values assigned to each word group differ for each LLM. This is to be expected, given that a particular LLM generates tokens according to its own processing logic. However, even though tokenization differs between LLMs, tokenization within a given LLM is consistent.
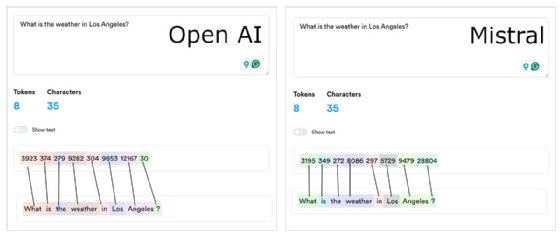
Figure 2 shows the tokenization of two natural language prompts: "What is the weather in Los Angeles?" and "What is the weather in Los Gatos?" The prompts are submitted to the OpenAI LLM. The only difference between the prompts is that the first has the characters "Angeles" and the second has the characters "Gatos."
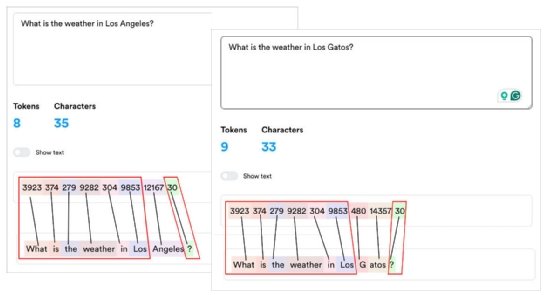
Notice the prompts' identical tokenization of the words "What is the weather in Los" and "?" This makes sense because OpenAI has standardized the token generation for those words. However, the tokens for the words "Angeles" and "Gatos" differ between prompts -- one token generated for the word "Angeles" but two tokens for the word "Gatos."
The reason for that difference is the special way the OpenAI LLM creates tokens. A particular model generates tokens for natural prompts according to its internal processing logic in a manner that accounts for its training algorithm and architecture, as well as the context and use case by which the prompt was submitted.
Tokens, embeddings and high-dimensional space
In the case of processing natural language prompts, LLMs convert words and phrases into tokens to generate embeddings, a vector representation that captures the semantic meaning of a phrase. These embeddings help the LLM's neural network understand the context and relationships between words, so the model can generate meaningful and contextually relevant responses using iterative token prediction.
An important point about embeddings is that they are numerical representations of words, phrases or even images and sounds, organized in a high-dimensional vector space in which similar tokens have similar vector representations. An LLM will iteratively apply sophisticated analysis methods such as neural network transformation and self-attention computation to embeddings in the vector space to construct the "next" token for a response to a natural language prompt.
High-dimensional vector space is an important concept to grasp when understanding how LLMs work, but it can be challenging for the uninitiated. Let's take a moment to explore high-dimensional vector space.
High-dimensional vector space
In programming, a vector is a dynamic array-like data structure that can store multiple elements of the same type. The term dimension in a vector space refers to the number of independent components that describe the space. For example, (2,6) is a two-dimensional vector.
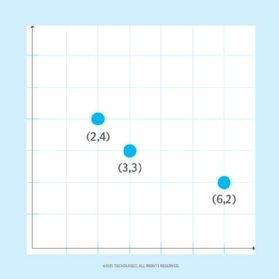
It's rather straightforward to graphically represent a two-dimensional vector space as shown in Figure 3 below. Each point in a two-dimensional space is a location determined by the intersection of a specific X coordinate and Y coordinate. One can also visualize the proximity of locations to one another in two-dimensional space. The location at (2,4) is closer to (3,3) than to the location at (6,2). Also, the distance between points can be determined mathematically.
Unlike a two-dimensional space in which proximity can be determined by the distance between two points, determining proximity in a four-dimensional space is a bit more complex. To visualize numeric elements in a four-dimensional space requires modification in how values are presented.
Figure 4 illustrates elements in a four-dimensional array. Each element represents an animal according to the parameters of age, length, type and sex. Age and length are represented as numbers. A geometric shape represents a type, and the color of the shape represents the sex of the animal.
As Figure 4 shows, proximity is not just a matter of spatial nearness of one shape to another. Other factors come into consideration based on the parameters that make up an element in the vector space.
For example, at the left of the drawing in Figure 4, two animals are "near" each other in terms of length, sex and weight as represented by the shape's color and type, even though their ages vary. The animals at the bottom of the graphic are "near" each other in terms of age and length, as represented by their coordinates on the XY axis, even though the sex and weights are different.
Thus, in a four-dimensional array, the notion of what it means for one data point to be "near" (or similar) to another depends on the parameters that define "nearness." What these parameters are describes the semantics of the relationship.

Again, the important thing to remember is that an LLM's vector space is high-dimensional, which means there are a lot of parameters associated with an element in that space. For example, the LLM Gemini Nano has 1.8 billion parameters, and Mistral 7B has 7.3 billion parameters.
The way the LLMs make sense of it all is to convert a natural language prompt into tokens and then process those tokens through a multilayer architecture. That architecture determines the semantics of the input and then applies the semantics and input to the parameters in the LLM's high-dimensional vector space. It's a complex undertaking that requires a good deal of understanding of neural networks and computational linguistics, and it gets more complex when processing data types such as audio and video.
Nevertheless, under it all, the pattern is essentially the same: convert the input into tokens, use semantic awareness acquired during the LLM's training to apply neural network and architecture logic, and process those tokens against the token data hosted in the LLM's multidimensional vector space to create a meaningful response.
Putting it all together
Large language models have made using AI commonplace. Working with AI is no longer a complex undertaking; for the most part, a user needs only submit a natural language prompt to an AI-enabled website or an AI-enabled device. The complexities are hidden within the internals of the particular LLM, and essential to it all is the LLM tokenization process.
Each LLM has its own way of generating tokens, and the way those tokens are converted to embedding and then processed within an LLM's vector space depends on the model's architecture and training.
Bob Reselman is a software developer, system architect and writer. His expertise ranges from software development technologies to techniques and culture.







