Follow this Java screen scraper example to aggregate content
With enterprise applications, it's not unusual to aggregate content published on live sites. As such, it's a good idea to develop a level of familiarity with one of the popular Java screen scraper libraries.
In this step-by-step Java screen scraper tutorial, we'll take a look at a framework named JSoup. The JSoup library has been around for a while, and it really hasn't changed much in recent years. It remains a popular and reliable server-side option.
In this example, we will use JSoup to pull some information off the popular GitHub interview questions and answers article published on this site. Extracted information will include the author's name, the display title and a list of all of the embedded links within the page. Here's how to accomplish this.
Step 1: Link to the JSoup library
To work with JSoup, first, create a basic Maven project, and add the JSoup dependency:
<!-- Java screen scraper POM -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
Step 2: Parse a URL
With the Maven dependency added, the next step is to have JSoup parse the specified URL to generate a JSoup Document object. For this example, we will name the returned Document object pageToScrape.
The code can be placed in a microservice, a servlet, a RESTful web component or even a JavaServer Page, but for this example, we will keep things simple and use a class with a runnable main method.
public class JavaScreenScraper {
public static void main(String args[]) throws Exception {
String url = "https://www.theserverside.com/video/Tough-sample-Git-and-GitHub-interview-questions-and-answers";
Document pageToScrape = Jsoup.connect(url).get();
}
}
}
Step 3: Scrape the page title
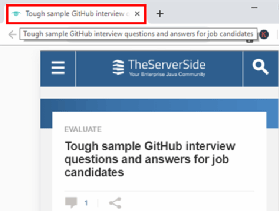
With the webpage now held as a Document object, it's possible to perform any number of inspections on the page. One inspection is to get the text displayed at the top of the browser when the page renders. You can achieve this with a call to the pageToScrape's title() method.
pageToScrape.title();
Step 4: Page scrape with CSS selectors
JSoup provides a few built-in methods, such as title() and body(). These enable developers to work with page elements. For more specific queries on the page, you'll need CSS selectors.
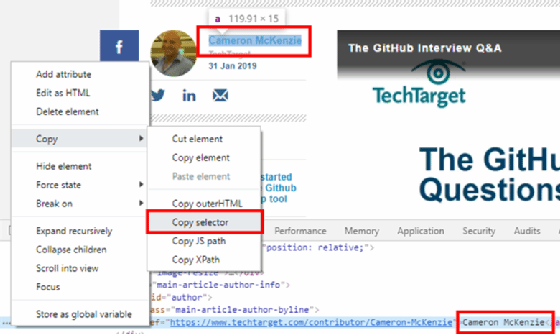
For example, the CSS selector for the spot where the author's name is displayed is:
#author > div > a
Given this information, you can have JSoup extract this element from the page with the selectFirst method. This returns an object of type Element representing the anchor tag. Invoke the text() method to obtain the text displayed by the anchor tag:
Element authorLink = pageToScrape.selectFirst("#author > div > a");
System.out.printf("The author: %s.\n", authorLink.text());
How to find a CSS selector
Every element on an HTML page can be identified through a CSS selector. However, it can be extremely frustrating to figure out what the selector is for a given element if one simply inspects the HTML source code. Fortunately, Google Chrome provides some great tools that help identify an element's CSS selector attribute.
To find an element's CSS selector value, simply right-click on the page element of interest, and choose Inspect. Then, left-click the three dots that appear adjacent to the HTML in the Elements tab. Finally, choose Copy > Copy selector, and the CSS selector of the element is added to your copy-and-paste clipboard.
Step 5: Multiple screen scraping results
If you're interested in more than one occurrence of an element on a page, you can use the Document object's generic select() method. Like the selectFirst() method, this derivation takes a CSS selector as an argument. However, instead of returning a single Element, it returns a collection of them.
For this Java screen scraper example, we will look at all of the anchor tags on the page and print the URL, or href attribute, of each of them. The code is:
Elements links = pageToScrape.select("a[href]");
for (Element link : links) {
System.out.print("\nLink: " + link.attr("href"));
}
When put together, the JavaScreenScraper class looks as follows:
package com.mcnz.design;
import org.jsoup.Jsoup;
/* Java screen scraper example code */
public class JavaScreenScraper {
public static void main(String args[]) throws Exception {
String url = "https://www.theserverside.com/video/Tough-sample-Git-and-GitHub-interview-questions-and-answers";
Document pageToScrape = Jsoup.connect(url).get();
System.out.printf("The title is: %s. \n", pageToScrape.title());
Element authorLink = pageToScrape.selectFirst("#author > div > a");
System.out.printf("The author: %s.\n", authorLink.text());
Elements links = pageToScrape.select("a[href]");
for (Element link : links) {
System.out.print("\nLink: " + link.attr("href"));
}
}
}
The Java screen scraper example code can then be run as a stand-alone Java class and generate the following output:
The title is: Tough sample GitHub interview questions and answers for job candidates.
The authors name is: Cameron McKenzie.
There have been 1 comments.
Link: https://www.theserverside.com/video/Tips-and-tricks-on-how-to-use-Jenkins-Git-Plugin
Link: https://www.theserverside.com/video/Tackle-these-10-sample-DevOps-interview-questions-and-answers
Link: https://www.theserverside.com/video/A-RESTful-APIs-tutorial-Learn-key-web-service-design-principles
The list of links goes on for over 100 iterations, so the output is truncated at three.
As you can see, it is fairly easy to aggregate data from active webpages with a Java screen scraper. There are a number of JavaScript libraries that perform a similar task, but if you want to process intensive applications, access to a server-side technology is preferred. If a Java screen scraper is what you need, give JSoup a try.
The source code for this example can be found on GitHub.