Run Llama LLMs on your laptop with Hugging Face and Python
There are numerous ways to run large language models such as DeepSeek, Claude or Meta's Llama locally on your laptop, including Ollama and Modular's Max platform. But if you want to fully control the large language model experience, the best way is to integrate Python and Hugging Face APIs together.
How to run Llama in a Python app
To run any large language model (LLM) locally within a Python app, follow these steps:
- Create a Python environment with PyTorch, Hugging Face and the transformer's dependencies.
- Find the official webpage of the LLM on Hugging Face.
- Programmatically download all the required files from the Hugging Face repo.
- Create a pipeline that references the model and the transformers it uses.
- Query the pipeline and interact with the LLM.
Transformers, PyTorch and Hugging Face
This tutorial creates a virtual Python environment and installs the required PyTorch and Hugging Face dependencies with the following PIP installs:
pip3 install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/sh1/nightly/cpu
pip3 install huggingface_hub
pip3 install transformers
Find the LLM on Hugging Face
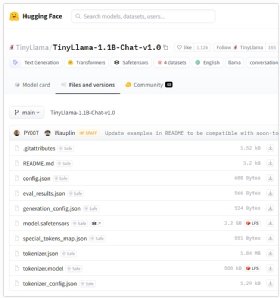
The Hugging Face Python API needs to know the name of the LLM to run, and you must specify the names of the various files to download. You can obtain them all on the official webpage of the LLM on the Hugging Face site.
Hugging Face, Python and Llama
With the dependencies installed and the required files identified, the last step is to simply code the Python program. The full code for the application is as follows:
from huggingface_hub import hf_hub_download
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
HUGGING_FACE_API_KEY = 'hf_ABCDEFGHIJKLYMNOPQURSTUVDSESYANELA'
huggingface_model = "TinyLlama/TinyLlama-1.1B-Chat-v1.0" # Replace with the actual model repo ID
required_files = [
"special_tokens_map.json",
"generation_config.json",
"tokenizer_config.json",
"model.safetensors",
"eval_results.json",
"tokenizer.model",
"tokenizer.json",
"config.json"
]
for filename in required_files:
download_location = hf_hub_download(
repo_id=huggingface_model,
filename=filename,
token=HUGGING_FACE_API_KEY
)
model = AutoModelForCausalLM.from_pretrained(huggingface_model) # Enable trust_remote_code for safetensors
tokenizer = AutoTokenizer.from_pretrained(huggingface_model)
text_generation_pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_length=1000
)
response = text_generation_pipeline("Tell me a good programming joke...")
print(response)
TinyLlama prompts and replies in Python
In this example, we just ask TinyLlama for a good programming joke. Admittedly the JSON response isn't particularly impressive, although this LLM isn't exactly known for its clever sense of humor. A factual query might have garnered a better response.
[{ 'generated_text':'Tell me a funny programming joke…\n\n A programmer accidentally deleted a file from his hard drive. He tried to recover it but it was gone.'}]And that's how easy it is to run LLMs locally and fully integrate them with your Python code.
Cameron McKenzie has been a Java EE software engineer for 20 years. His current specialties include Agile development; DevOps; Spring; and container-based technologies such as Docker, Swarm and Kubernetes.