Introduction to the Spring Framework
Since the first version of this article was published in October, 2003, the Spring Framework has steadily grown in popularity. It has progressed through version 1.0 final to the present 1.2, and has been adopted in a wide range of industries and projects. In this article, I'll try to explain what Spring sets out to achieve, and how I believe it can help you to develop J2EE applications.
| Other Spring Articles |
| Spring Web Flow Spring Webwork 2 Integration Sending Velocity-based E-mail with Spring Tech Talk: Rod Johnson on The Spring Framework, AOP Tech Talk: Rod Johnson on J2EE Design, AOP, The Spring Framework |
Check out these updated Tutorials for Spring 3 and Hibernate 3.x
Since the first version of this article was published in October, 2003, the Spring Framework has steadily grown in popularity. It has progressed through version 1.0 final to the present 1.2, and has been adopted in a wide range of industries and projects. In this article, I'll try to explain what Spring sets out to achieve, and how I believe it can help you to develop J2EE applications.
Yet another framework?
You may be thinking "not another framework." Why should you read this article, or download the Spring Framework (if you haven't already), when there are so many J2EE frameworks, or when you could build your own framework? The sustained high level of interest in the community is one indication that Spring must offer something valuable; there are also numerous technical reasons.
I believe that Spring is unique, for several reasons:
- It addresses important areas that many other popular frameworks don't. Spring focuses around providing a way to manage your business objects.
- Spring is both comprehensive and modular. Spring has a layered architecture, meaning that you can choose to use just about any part of it in isolation, yet its architecture is internally consistent. So you get maximum value from your learning curve. You might choose to use Spring only to simplify use of JDBC, for example, or you might choose to use Spring to manage all your business objects. And it's easy to introduce Spring incrementally into existing projects.
- Spring is designed from the ground up to help you write code that's easy to test. Spring is an ideal framework for test driven projects.
- Spring is an increasingly important integration technology, its role recognized by several large vendors.
Spring is not necessarily one more framework dependency for your project. Spring is potentially a one-stop shop, addressing most infrastructure concerns of typical applications. It also goes places other frameworks don't.
An open source project since February 2003, Spring has a long heritage. The open source project started from infrastructure code published with my book, Expert One-on-One J2EE Design and Development, in late 2002. Expert One-on-One J2EE laid out the basic architectural thinking behind Spring. However, the architectural concepts go back to early 2000, and reflect my experience in developing infrastructure for a series of successful commercial projects.
Since January 2003, Spring has been hosted on SourceForge. There are now 20 developers, with the leading contributors devoted full-time to Spring development and support. The flourishing open source community has helped it evolve into far more than could have been achieved by any individual.
Architectural benefits of Spring
Before we get down to specifics, let's look at some of the benefits Spring can bring to a project:
- Spring can effectively organize your middle tier objects, whether or not you choose to use EJB. Spring takes care of plumbing that would be left up to you if you use only Struts or other frameworks geared to particular J2EE APIs. And while it is perhaps most valuable in the middle tier, Spring's configuration management services can be used in any architectural layer, in whatever runtime environment.
- Spring can eliminate the proliferation of Singletons seen on many projects. In my experience, this is a major problem, reducing testability and object orientation.
- Spring can eliminate the need to use a variety of custom properties file formats, by handling configuration in a consistent way throughout applications and projects. Ever wondered what magic property keys or system properties a particular class looks for, and had to read the Javadoc or even source code? With Spring you simply look at the class's JavaBean properties or constructor arguments. The use of Inversion of Control and Dependency Injection (discussed below) helps achieve this simplification.
- Spring can facilitate good programming practice by reducing the cost of programming to interfaces, rather than classes, almost to zero.
- Spring is designed so that applications built with it depend on as few of its APIs as possible. Most business objects in Spring applications have no dependency on Spring.
- Applications built using Spring are very easy to unit test.
- Spring can make the use of EJB an implementation choice, rather than the determinant of application architecture. You can choose to implement business interfaces as POJOs or local EJBs without affecting calling code.
- Spring helps you solve many problems without using EJB. Spring can provide an alternative to EJB that's appropriate for many applications. For example, Spring can use AOP to deliver declarative transaction management without using an EJB container; even without a JTA implementation, if you only need to work with a single database.
- Spring provides a consistent framework for data access, whether using JDBC or an O/R mapping product such as TopLink, Hibernate or a JDO implementation.
- Spring provides a consistent, simple programming model in many areas, making it an ideal architectural "glue." You can see this consistency in the Spring approach to JDBC, JMS, JavaMail, JNDI and many other important APIs.
Spring is essentially a technology dedicated to enabling you to build applications using POJOs. This desirable goal requires a sophisticated framework, which conceals much complexity from the developer.
Thus Spring really can enable you to implement the simplest possible solution to your problems. And that's worth a lot.
What does Spring do?
Spring provides a lot of functionality, so I'll quickly review each major area in turn.
Mission statement
Firstly, let's be clear on Spring's scope. Although Spring covers a lot of ground, we have a clear vision as to what it should and shouldn't address.
Spring's main aim is to make J2EE easier to use and promote good programming practice. It does this by enabling a POJO-based programming model that is applicable in a wide range of environments.
Spring does not reinvent the wheel. Thus you'll find no logging packages in Spring, no connection pools, no distributed transaction coordinator. All these things are provided by open source projects (such as Commons Logging, which we use for all our log output, or Commons DBCP), or by your application server. For the same reason, we don't provide an O/R mapping layer. There are good solutions to this problem such as TopLink, Hibernate and JDO.
Spring does aim to make existing technologies easier to use. For example, although we are not in the business of low-level transaction coordination, we do provide an abstraction layer over JTA or any other transaction strategy.
Spring doesn't directly compete with other open source projects unless we feel we can provide something new. For example, like many developers, we have never been happy with Struts, and felt that there was room for improvement in MVC web frameworks. (With Spring MVC adoption growing rapidly, it seems that many agree with us.) In some areas, such as its lightweight IoC container and AOP framework, Spring does have direct competition, but Spring was a pioneer in those areas.
Spring benefits from internal consistency. All the developers are singing from the same hymn sheet, the fundamental ideas remaining faithful to those of Expert One-on-One J2EE Design and Development. And we've been able to use some central concepts, such as Inversion of Control, across multiple areas.
Spring is portable between application servers. Of course ensuring portability is always a challenge, but we avoid anything platform-specific or non-standard in the developer's view, and support users on WebLogic, Tomcat, Resin, JBoss, Jetty, Geronimo, WebSphere and other application servers. Spring's non-invasive, POJO, approach enables us to take advantage of environment-specific features without sacrificing portability, as in the case of enhanced WebLogic transaction management functionality in Spring 1.2 that uses BEA proprietary APIs under the covers.
Inversion of control container
The core of Spring is the org.springframework.beans package, designed for working with JavaBeans. This package typically isn't used directly by users, but underpins much Spring functionality.
The next higher layer of abstraction is the bean factory. A Spring bean factory is a generic factory that enables objects to be retrieved by name, and which can manage relationships between objects.
Bean factories support two modes of object:
- Singleton: in this case, there's one shared instance of the object with a particular name, which will be retrieved on lookup. This is the default, and most often used, mode. It's ideal for stateless service objects.
- Prototype or non-singleton: in this case, each retrieval will result in the creation of an independent object. For example, this could be used to allow each caller to have its own distinct object reference.
Because the Spring container manages relationships between objects, it can add value where necessary through services such as transparent pooling for managed POJOs, and support for hot swapping, where the container introduces a level of indirection that allows the target of a reference to be swapped at runtime without affecting callers and without loss of thread safety. One of the beauties of Dependency Injection (discussed shortly) is that all this is possible transparently, with no API involved.
As org.springframework.beans.factory.BeanFactory is a simple interface, it can be implemented in different ways. The BeanDefinitionReader interface separates the metadata format from BeanFactory implementations themselves, so the generic BeanFactory implementations Spring provides can be used with different types of metadata. You could easily implement your own BeanFactory or BeanDefinitionReader, although few users find a need to. The most commonly used BeanFactory definitions are:
- XmlBeanFactory. This parses a simple, intuitive XML structure defining the classes and properties of named objects. We provide a DTD to make authoring easier.
- DefaultListableBeanFactory: This provides the ability to parse bean definitions in properties files, and create BeanFactories programmatically.
Each bean definition can be a POJO (defined by class name and JavaBean initialisation properties or constructor arguments), or a FactoryBean. The FactoryBean interface adds a level of indirection. Typically this is used to create proxied objects using AOP or other approaches: for example, proxies that add declarative transaction management. This is conceptually similar to EJB interception, but works out much simpler in practice, and is more powerful.
BeanFactories can optionally participate in a hierarchy, "inheriting" definitions from their ancestors. This enables the sharing of common configuration across a whole application, while individual resources such as controller servlets also have their own independent set of objects.
This motivation for the use of JavaBeans is described in Chapter 4 of Expert One-on-One J2EE Design and Development, which is available on the ServerSide as a free PDF (/articles/article.tss?l=RodJohnsonInterview).
Through its bean factory concept, Spring is an Inversion of Control container. (I don't much like the term container, as it conjures up visions of heavyweight containers such as EJB containers. A Spring BeanFactory is a container that can be created in a single line of code, and requires no special deployment steps.) Spring is most closely identified with a flavor of Inversion of Control known as Dependency Injection--a name coined by Martin Fowler, Rod Johnson and the PicoContainer team in late 2003.
The concept behind Inversion of Control is often expressed in the Hollywood Principle: "Don't call me, I'll call you." IoC moves the responsibility for making things happen into the framework, and away from application code. Whereas your code calls a traditional class library, an IoC framework calls your code. Lifecycle callbacks in many APIs, such as the setSessionContext() method for session EJBs, demonstrate this approach.
Dependency Injection is a form of IoC that removes explicit dependence on container APIs; ordinary Java methods are used to inject dependencies such as collaborating objects or configuration values into application object instances. Where configuration is concerned this means that while in traditional container architectures such as EJB, a component might call the container to say "where's object X, which I need to do my work", with Dependency Injection the container figures out that the component needs an X object, and provides it to it at runtime. The container does this figuring out based on method signatures (usually JavaBean properties or constructors) and, possibly, configuration data such as XML.
The two major flavors of Dependency Injection are Setter Injection (injection via JavaBean setters); and Constructor Injection (injection via constructor arguments). Spring provides sophisticated support for both, and even allows you to mix the two when configuring the one object.
As well as supporting all forms of Dependency Injection, Spring also provides a range of callback events, and an API for traditional lookup where necessary. However, we recommend a pure Dependency Injection approach in general.
Dependency Injection has several important benefits. For example:
- Because components don't need to look up collaborators at runtime, they're much simpler to write and maintain. In Spring's version of IoC, components express their dependency on other components via exposing JavaBean setter methods or through constructor arguments. The EJB equivalent would be a JNDI lookup, which requires the developer to write code that makes environmental assumptions.
- For the same reasons, application code is much easier to test. For example, JavaBean properties are simple, core Java and easy to test: simply write a self-contained JUnit test method that creates the object and sets the relevant properties.
- A good IoC implementation preserves strong typing. If you need to use a generic factory to look up collaborators, you have to cast the results to the desired type. This isn't a major problem, but it is inelegant. With IoC you express strongly typed dependencies in your code and the framework is responsible for type casts. This means that type mismatches will be raised as errors when the framework configures the application; you don't have to worry about class cast exceptions in your code.
- Dependencies are explicit. For example, if an application class tries to load a properties file or connect to a database on instantiation, the environmental assumptions may not be obvious without reading the code (complicating testing and reducing deployment flexibility). With a Dependency Injection approach, dependencies are explicit, and evident in constructor or JavaBean properties.
- Most business objects don't depend on IoC container APIs. This makes it easy to use legacy code, and easy to use objects either inside or outside the IoC container. For example, Spring users often configure the Jakarta Commons DBCP DataSource as a Spring bean: there's no need to write any custom code to do this. We say that an IoC container isn't invasive: using it won't invade your code with dependency on its APIs. Almost any POJO can become a component in a Spring bean factory. Existing JavaBeans or objects with multi-argument constructors work particularly well, but Spring also provides unique support for instantiating objects from static factory methods or even methods on other objects managed by the IoC container.
This last point deserves emphasis. Dependency Injection is unlike traditional container architectures, such as EJB, in this minimization of dependency of application code on container. This means that your business objects can potentially be run in different Dependency Injection frameworks - or outside any framework - without code changes.
In my experience and that of Spring users, it's hard to overemphasize the benefits that IoC--and, especially, Dependency Injection--brings to application code.
Dependency Injection is not a new concept, although it's only recently made prime time in the J2EE community. There are alternative DI containers: notably, PicoContainer and HiveMind. PicoContainer is particularly lightweight and emphasizes the expression of dependencies through constructors rather than JavaBean properties. It does not use metadata outside Java code, which limits its functionality in comparison with Spring. HiveMind is conceptually more similar to Spring (also aiming at more than just IoC), although it lacks the comprehensive scope of the Spring project or the same scale of user community. EJB 3.0 will provide a basic DI capability as well.
Spring BeanFactories are very lightweight. Users have successfully used them inside applets, as well as standalone Swing applications. (They also work fine within an EJB container.) There are no special deployment steps and no detectable startup time associated with the container itself (although certain objects configured by the container may of course take time to initialize). This ability to instantiate a container almost instantly in any tier of an application can be very valuable.
The Spring BeanFactory concept is used throughout Spring, and is a key reason that Spring is so internally consistent. Spring is also unique among IoC containers in that it uses IoC as a basic concept throughout a full-featured framework.
Most importantly for application developers, one or more BeanFactories provide a well-defined layer of business objects. This is analogous to, but much simpler (yet more powerful), than a layer of local session beans. Unlike EJBs, the objects in this layer can be interrelated, and their relationships managed by the owning factory. Having a well-defined layer of business objects is very important to a successful architecture.
A Spring ApplicationContext is a subinterface of BeanFactory, which provides support for:
- Message lookup, supporting internationalization
- An eventing mechanism, allowing application objects to publish and optionally register to be notified of events
- Automatic recognition of special application-specific or generic bean definitions that customize container behavior
- Portable file and resource access
XmlBeanFactory example
Spring users normally configure their applications in XML "bean definition" files. The root of a Spring XML bean definition document is a <beans> element. The <beans> element contains one or more <bean> definitions. We normally specify the class and properties of each bean definition. We must also specify the id, which will be the name that we'll use this bean with in our code.
Let's look at a simple example, which configures three application objects with relationships commonly seen in J2EE applications:
- A J2EE DataSource
- A DAO that uses the DataSource
- A business object that uses the DAO in the course of its work
In the following example, we use a BasicDataSource from the Jakarta Commons DBCP project. (ComboPooledDataSource from the C3PO project is also an excellent option.) BasicDataSource, like many other existing classes, can easily be used in a Spring bean factory, as it offers JavaBean-style configuration. The close method that needs to be called on shutdown can be registered via Spring's "destroy-method" attribute, to avoid the need for BasicDataSource to implement any Spring interface.
<beans> <bean id="myDataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close"> <property name="driverClassName" value="com.mysql.jdbc.Driver" /> <property name="url" value="jdbc:mysql://localhost:3306/mydb" /> <property name="username" value="someone" /> </bean>
All the properties of BasicDataSource we're interested in are Strings, so we specify their values with the "value" attribute. (This shortcut was introduced in Spring 1.2. It's a convenient alternative to the <value> subelement, which is usable even for values that are problematic in XML attributes.) Spring uses the standard JavaBean PropertyEditor mechanism to convert String representations to other types if necessary.
Now we define the DAO, which has a bean reference to the DataSource. Relationships between beans are specified using the "ref" attribute or <ref> element:
<bean id="exampleDataAccessObject" class="example.ExampleDataAccessObject"> <property name="dataSource" ref="myDataSource" /> </bean>
The business object has a reference to the DAO, and an int property (exampleParam). In this case, I've used the subelement syntax familiar to those who've used Spring prior to 1.2:
<bean id="exampleBusinessObject" class="example.ExampleBusinessObject"> <property name="dataAccessObject"><ref bean="exampleDataAccessObject"/></property> <property name="exampleParam"><value>10</value></property> </bean> </beans>
Relationships between objects are normally set explicitly in configuration, as in this example. We consider this to be a Good Thing in most cases. However, Spring also provides what we call "autowire" support, where it figures out the dependencies between beans. The limitation with this - as with PicoContainer - is that if there are multiple beans of a particular type it's impossible to work out which instance a dependency of that type should be resolved to. On the positive side, unsatisfied dependencies can be caught when the factory is initialized. (Spring also offers an optional dependency check for explicit configuration, which can achieve this goal.)
We could use the autowire feature as follows in the above example, if we didn't want to code these relationships explicitly:
<bean id="exampleBusinessObject" class="example.ExampleBusinessObject" autowire="byType"> <property name="exampleParam" value="10" /> </bean>
With this usage, Spring will work out that the dataSource property of exampleBusinessObject should be set to the implementation of DataSource it finds in the present BeanFactory. It's an error if there is none, or more than one, bean of the required type in the present BeanFactory. We still need to set the exampleParam property, as it's not a reference.
Autowire support has the advantage of reducing the volume of configuration. It also means that the container can learn about application structure using reflection, so if you add an additional constructor argument of JavaBean property, it may be successfully populated without any need to change configuration. The tradeoffs around autowiring need to be evaluated carefully.
Externalizing relationships from Java code has an enormous benefit over hard coding it, as it's possible to change the XML file without changing a line of Java code. For example, we could simply change the myDataSource bean definition to refer to a different bean class to use an alternative connection pool, or a test data source. We could use Spring's JNDI location FactoryBean to get a datasource from an application server in a single alternative XML stanza, as follows. There would be no impact on Java code or any other bean definitions.
<bean id="myDataSource" class="org.springframework.jndi.JndiObjectFactoryBean"> <property name="jndiName" value="jdbc/myDataSource" /> </bean>
Now let's look at the Java code for the example business object. Note that there are no Spring dependencies in the code listing below. Unlike an EJB container, a Spring BeanFactory is not invasive: you don't normally need to code awareness of it into application objects.
public class ExampleBusinessObject implements MyBusinessObject { private ExampleDataAccessObject dao; private int exampleParam; public void setDataAccessObject(ExampleDataAccessObject dao) { this.dao = dao; } public void setExampleParam(int exampleParam) { this.exampleParam = exampleParam; } public void myBusinessMethod() { // do stuff using dao } }
Note the property setters, which correspond to the XML references in the bean definition document. These are invoked by Spring before the object is used.
Such application beans do not need to depend on Spring: They don't need to implement any Spring interfaces or extend Spring classes: they just need to observe JavaBeans naming convention. Reusing one outside of a Spring application context is easy, for example in a test environment. Just instantiate it with its default constructor, and set its properties manually, via setDataSource() and setExampleParam() calls. So long as you have a no-args constructor, you're free to define other constructors taking multiple properties if you want to support programmatic construction in a single line of code.
Note that the JavaBean properties are not declared on the business interface callers will work with. They're an implementation detail. We can easily "plug in" different implementing classes that have different bean properties without affecting connected objects or calling code.
Of course Spring XML bean factories have many more capabilities than described here, but this should give you a feel for the basic approach. As well as simple properties, and properties for which you have a JavaBeans PropertyEditor, Spring can handle lists, maps and java.util.Properties. Other advanced container capabilities include:
- Inner beans, in which a property element contains an anonymous bean definition not visible at top-level scope
- Post processors: special bean definitions that customize container behavior
- Method Injection, a form of IoC in which the container implements an abstract method or overrides a concrete method to inject a dependency. This is a more rarely used form of Dependency Injection than Setter or Constructor Injection. However, it can be useful to avoid an explicit container dependency when looking up a new object instance for each invocation, or to allow configuration to vary over time--for example, with the method implementation being backed by a SQL query in one environment and a fil system read in another.
Bean factories and application contexts are often associated with a scope defined by the J2EE server or web container, such as:
- The Servlet context. In the Spring MVC framework, an application context is defined for each web application containing common objects. Spring provides the ability to instantiate such a context through a listener or servlet without dependence on the Spring MVC framework, so it can also be used in Struts, WebWork or other web frameworks.
- A Servlet: Each controller servlet in the Spring MVC framework has its own application context, derived from the root (application-wide) application context. It's also easy to accomplish this with Struts or another MVC framework.
- EJB: Spring provides convenience superclasses for EJB that simplify EJB authoring and provide a BeanFactory loaded from an XML document in the EJB Jar file.
These hooks provided by the J2EE specification generally avoid the need to use a Singleton to bootstrap a bean factory.
However, it's trivial to instantiate a BeanFactory programmatically if we wish. For example, we could create the bean factory and get a reference to the business object defined above in the following three lines of code:
XmlBeanFactory bf = new XmlBeanFactory(new ClassPathResource("myFile.xml", getClass())); MyBusinessObject mbo = (MyBusinessObject) bf.getBean("exampleBusinessObject");
This code will work outside an application server: it doesn't even depend on J2EE, as the Spring IoC container is pure Java. The Spring Rich project (a framework for simplifying the development of Swing applications using Spring) demonstrates how Spring can be used outside a J2EE environment, as do Spring's integration testing features, discussed later in this article. Dependency Injection and the related functionality is too general and valuable to be confined to a J2EE, or server-side, environment.
JDBC abstraction and data access exception hierarchy
Data access is another area in which Spring shines.
JDBC offers fairly good abstraction from the underlying database, but is a painful API to use. Some of the problems include:
- The need for verbose error handling to ensure that ResultSets, Statements and (most importantly) Connections are closed after use. This means that correct use of JDBC can quickly result in a lot of code. It's also a common source of errors. Connection leaks can quickly bring applications down under load.
- The relatively uninformative SQLException. JDBC does not offer an exception hierarchy, but throws SQLException in response to all errors. Finding out what actually went wrong - for example, was the problem a deadlock or invalid SQL? - involves examining the SQLState value and error code. The meaning of these values varies between databases.
Spring addresses these problems in two ways:
- By providing APIs that move tedious and error-prone exception handling out of application code into the framework. The framework takes care of all exception handling; application code can concentrate on issuing the appropriate SQL and extracting results.
- By providing a meaningful exception hierarchy for your application code to work with in place of SQLException. When Spring first obtains a connection from a DataSource it examines the metadata to determine the database product. It uses this knowledge to map SQLExceptions to the correct exception in its own hierarchy descended from org.springframework.dao.DataAccessException. Thus your code can work with meaningful exceptions, and need not worry about proprietary SQLState or error codes. Spring's data access exceptions are not JDBC-specific, so your DAOs are not necessarily tied to JDBC because of the exceptions they may throw.
The following UML class diagram illustrates a part of this data access exception hierarchy, indicating its sophistication. Note that none of the exceptions shown here is JDBC-specific. There are JDBC-specific subclasses of some of these exceptions, but calling code is generally abstracted wholly away from dependence on JDBC: an essential if you wish to use truly API-agnostic DAO interfaces to hide your persistence strategy.
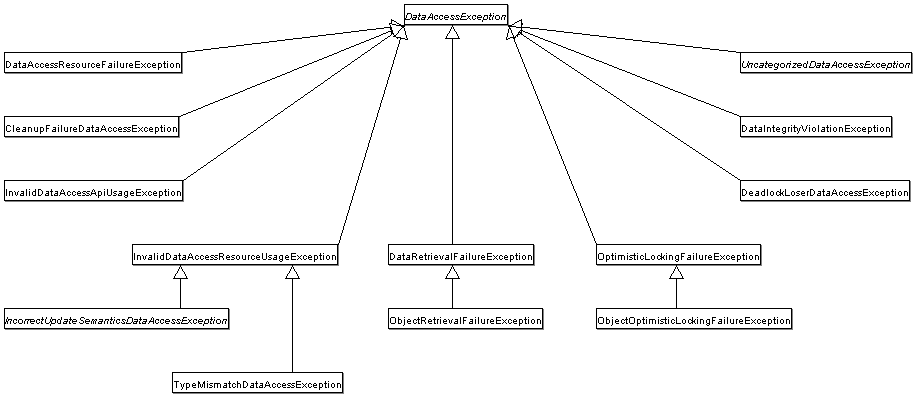
|
Spring provides two levels of JDBC abstraction API. The first, in the org.springframework.jdbc.core package, uses callbacks to move control - and hence error handling and connection acquisition and release - from application code inside the framework. This is a different type of Inversion of Control, but equally valuable to that used for configuration management.
Spring uses a similar callback approach to address several other APIs that involve special steps to acquire and cleanup resources, such as JDO (acquiring and relinquishing a PersistenceManager), transaction management (using JTA) and JNDI. Spring classes that perform such callbacks are called templates.
For example, the Spring JdbcTemplate object can be used to perform a SQL query and save the results in a list as follows:
JdbcTemplate template = new JdbcTemplate(dataSource); List names = template.query("SELECT USER.NAME FROM USER", new RowMapper() { public Object mapRow(ResultSet rs, int rowNum) throws SQLException; return rs.getString(1); } });
The mapRow callback method will be invoked for each row of the ResultSet.
Note that application code within the callback is free to throw SQLException: Spring will catch any exceptions and rethrow them in its own hierarchy. The application developer can choose which exceptions, if any, to catch and handle.
The JdbcTemplate provides many methods to support different scenarios including prepared statements and batch updates. Simple tasks like running SQL functions can be accomplished without a callback, as follows. The example also illustrates the use of bind variables:
int youngUserCount = template.queryForInt("SELECT COUNT(0) FROM USER WHERE USER.AGE < ?", new Object[] { new Integer(25) });
The Spring JDBC abstraction has a very low performance overhead beyond standard JDBC, even when working with huge result sets. (In one project in 2004, we profiled the performance of a financial application performing up to 1.2 million inserts per transaction. The overhead of Spring JDBC was minimal, and the use of Spring facilitated the tuning of batch sizes and other parameters.)
The higher level JDBC abstraction is in the org.springframework.jdbc.object package. This is built on the core JDBC callback functionality, but provides an API in which an RDBMS operation - whether query, update or stored procedure - is modelled as a Java object. This API was partly inspired by the JDO query API, which I found intuitive and highly usable.
A query object to return User objects might look like this:
class UserQuery extends MappingSqlQuery { public UserQuery(DataSource datasource) { super(datasource, "SELECT * FROM PUB_USER_ADDRESS WHERE USER_ID = ?"); declareParameter(new SqlParameter(Types.NUMERIC)); compile(); } // Map a result set row to a Java object protected Object mapRow(ResultSet rs, int rownum) throws SQLException { User user = new User(); user.setId(rs.getLong("USER_ID")); user.setForename(rs.getString("FORENAME")); return user; } public User findUser(long id) { // Use superclass convenience method to provide strong typing return (User) findObject(id); } }
This class can be used as follows:
User user = userQuery.findUser(25);
Such objects are often inner classes inside DAOs. They are threadsafe, unless the subclass does something unusual.
Another important class in the org.springframework.jdbc.object package is the StoredProcedure class. Spring enables a stored procedure to be proxied by a Java class with a single business method. If you like, you can define an interface that the stored procedure implements, meaning that you can free your application code from depending on the use of a stored procedure at all.
The Spring data access exception hierarchy is based on unchecked (runtime) exceptions. Having worked with Spring on several projects I'm more and more convinced that this was the right decision.
Data access exceptions not usually recoverable. For example, if we can't connect to the database, a particular business object is unlikely to be able to work around the problem. One potential exception is optimistic locking violations, but not all applications use optimistic locking. It's usually bad to be forced to write code to catch fatal exceptions that can't be sensibly handled. Letting them propagate to top-level handlers like the servlet or EJB container is usually more appropriate. All Spring data access exceptions are subclasses of DataAccessException, so if we do choose to catch all Spring data access exceptions, we can easily do so.
Note that if we do want to recover from an unchecked data access exception, we can still do so. We can write code to handle only the recoverable condition. For example, if we consider that only an optimistic locking violation is recoverable, we can write code in a Spring DAO as follows:
try { // do work } catch (OptimisticLockingFailureException ex) { // I'm interested in this }
If Spring data access exceptions were checked, we'd need to write the following code. Note that we could choose to write this anyway:
try { // do work } catch (OptimisticLockingFailureException ex) { // I'm interested in this } catch (DataAccessException ex) { // Fatal; just rethrow it }
One potential objection to the first example - that the compiler can't enforce handling the potentially recoverable exception - applies also to the second. Because we're forced to catch the base exception (DataAccessException), the compiler won't enforce a check for a subclass (OptimisticLockingFailureException). So the compiler would force us to write code to handle an unrecoverable problem, but provide no help in forcing us to deal with the recoverable problem.
Spring's use of unchecked data access exceptions is consistent with that of many - probably most - successful persistence frameworks. (Indeed, it was partly inspired by JDO.) JDBC is one of the few data access APIs to use checked exceptions. TopLink and JDO, for example, use unchecked exceptions exclusively. Hibernate switched from checked to unchecked exceptions in version 3.
Spring JDBC can help you in several ways:
- You'll never need to write a finally block again to use JDBC
- Connection leaks will be a thing of the past
- You'll need to write less code overall, and that code will be clearly focused on the necessary SQL
- You'll never need to dig through your RDBMS documentation to work out what obscure error code it returns for a bad column name. Your application won't be dependent on RDBMS-specific error handling code.
- Whatever persistence technology use, you'll find it easy to implement the DAO pattern without business logic depending on any particular data access API.
- You'll benefit from improved portability (compared to raw JDBC) in advanced areas such as BLOB handling and invoking stored procedures that return result sets.
In practice we find that all this amounts to substantial productivity gains and fewer bugs. I used to loathe writing JDBC code; now I find that I can focus on the SQL I want to execute, rather than the incidentals of JDBC resource management.
Spring's JDBC abstraction can be used standalone if desired - you are not forced to use the other parts of Spring.
O/R mapping integration
Of course often you want to use O/R mapping, rather than use relational data access. Your overall application framework must support this also. Thus Spring integrates out of the box with Hibernate (versions 2 and 3), JDO (versions 1 and 2), TopLink and other ORM products. Its data access architecture allows it to integrate with any underlying data access technology. Spring and Hibernate are a particularly popular combination.
Why would you use an ORM product plus Spring, instead of the ORM product directly? Spring adds significant value in the following areas:
- Session management. Spring offers efficient, easy, and safe handling of units of work such as Hibernate or TopLink Sessions. Related code using the ORM tool alone generally needs to use the same "Session" object for efficiency and proper transaction handling. Spring can transparently create and bind a session to the current thread, using either a declarative, AOP method interceptor approach, or by using an explicit, "template" wrapper class at the Java code level. Thus Spring solves many of the usage issues that affect many users of ORM technology.
- Resource management. Spring application contexts can handle the location and configuration of Hibernate SessionFactories, JDBC datasources, and other related resources. This makes these values easy to manage and change.
- Integrated transaction management. Spring allows you to wrap your ORM code with either a declarative, AOP method interceptor, or an explicit 'template' wrapper class at the Java code level. In either case, transaction semantics are handled for you, and proper transaction handling (rollback, etc.) in case of exceptions is taken care of. As we discuss later, you also get the benefit of being able to use and swap various transaction managers, without your ORM-related code being affected. As an added benefit, JDBC-related code can fully integrate transactionally with ORM code, in the case of most supported ORM tools. This is useful for handling functionality not amenable to ORM.
- Exception wrapping, as described above. Spring can wrap exceptions from the ORM layer, converting them from proprietary (possibly checked) exceptions, to a set of abstracted runtime exceptions. This allows you to handle most persistence exceptions, which are non-recoverable, only in the appropriate layers, without annoying boilerplate catches/throws, and exception declarations. You can still trap and handle exceptions anywhere you need to. Remember that JDBC exceptions (including DB specific dialects) are also converted to the same hierarchy, meaning that you can perform some operations with JDBC within a consistent programming model.
- To avoid vendor lock-in. ORM solutions have different performance other characterics, and there is no perfect one size fits all solution. Alternatively, you may find that certain functionality is just not suited to an implemention using your ORM tool. Thus it makes sense to decouple your architecture from the tool-specific implementations of your data access object interfaces. If you may ever need to switch to another implementation for reasons of functionality, performance, or any other concerns, using Spring now can make the eventual switch much easier. Spring's abstraction of your ORM tool's Transactions and Exceptions, along with its IoC approach which allow you to easily swap in mapper/DAO objects implementing data-access functionality, make it easy to isolate all ORM-specific code in one area of your application, without sacrificing any of the power of your ORM tool. The PetClinic sample application shipped with Spring demonstrates the portability benefits that Spring offers, through providing variants that use JDBC, Hibernate, TopLink and Apache OJB to implement the persistence layer.
- Ease of testing. Spring's inversion of control approach makes it easy to swap the implementations and locations of resources such as Hibernate session factories, datasources, transaction managers, and mapper object implementations (if needed). This makes it much easier to isolate and test each piece of persistence-related code in isolation.
Above all, Spring facilitates a mix-and-match approach to data access. Despite the claims of some ORM vendors, ORM is not the solution to all problems, although it is a valuable productivity win in many cases. Spring enables a consistent architecture, and transaction strategy, even if you mix and match persistence approaches, even without using JTA.
In cases where ORM is not ideally suited, Spring's simplified JDBC is not the only option: the "mapped statement" approach provided by iBATIS SQL Maps is worth a look. It provides a high level of control over SQL, while still automating the creation of mapped objects from query results. Spring integrates with SQL Maps out of the box. Spring's PetStore sample application illustrates iBATIS integration. Transaction management
Abstracting a data access API is not enough; we also need to consider transaction management. JTA is the obvious solution, but it's a cumbersome API to use directly, and as a result many J2EE developers used to feel that EJB CMT is the only rational option for transaction management. Spring has changed that.
Spring provides its own abstraction for transaction management. Spring uses this to deliver:
- Programmatic transaction management via a callback template analogous to the JdbcTemplate, which is much easier to use than straight JTA
- Declarative transaction management analogous to EJB CMT, but without the need for an EJB container. Actually, as we'll see, Spring's declarative transaction management capability is a semantically compatible superset of EJB CMT, with some unique and important benefits.
Spring's transaction abstraction is unique in that it's not tied to JTA or any other transaction management technology. Spring uses the concept of a transaction strategy that decouples application code from the underlying transaction infrastructure (such as JDBC).
Why should you care about this? Isn't JTA the best answer for all transaction management? If you're writing an application that uses only a single database, you don't need the complexity of JTA. You're not interested in XA transactions or two phase commit. You may not even need a high-end application server that provides these things. But, on the other hand, you don't want to have to rewrite your code should you ever have to work with multiple data sources.
Imagine you decide to avoid the overhead of JTA by using JDBC or Hibernate transactions directly. If you ever need to work with multiple data sources, you'll have to rip out all that transaction management code and replace it with JTA transactions. This isn't very attractive and led most writers on J2EE, including myself, to recommend using global JTA transactions exclusively, effectively ruling out using a simple web container such as Tomcat for transactional applications. Using the Spring transaction abstraction, however, you only have to reconfigure Spring to use a JTA, rather than JDBC or Hibernate, transaction strategy and you're done. This is a configuration change, not a code change. Thus, Spring enables you to write applications that can scale down as well as up.
AOP
Since 2003 there has been much interest in applying AOP solutions to those enterprise concerns, such as transaction management, which have traditionally been addressed by EJB.
The first goal of Spring's AOP support is to provide J2EE services to POJOs. Spring AOP is portable between application servers, so there's no risk of vendor lock in. It works in either web or EJB container, and has been used successfully in WebLogic, Tomcat, JBoss, Resin, Jetty, Orion and many other application servers and web containers.
Spring AOP supports method interception. Key AOP concepts supported include:
- Interception: Custom behaviour can be inserted before or after method invocations against any interface or class. This is similar to "around advice" in AspectJ terminology.
- Introduction: Specifying that an advice should cause an object to implement additional interfaces. This can amount to mixin inheritance.
- Static and dynamic pointcuts: Specifying the points in program execution at which interception should take place. Static pointcuts concern method signatures; dynamic pointcuts may also consider method arguments at the point where they are evaluated. Pointcuts are defined separately from interceptors, enabling a standard interceptor to be applied in different applications and code contexts.
Spring supports both stateful (one instance per advised object) and stateless interceptors (one instance for all advice).
Spring does not support field interception. This is a deliberate design decision. I have always felt that field interception violates encapsulation. I prefer to think of AOP as complementing, rather than conflicting with, OOP. In five or ten years time we will probably have travelled a lot farther on the AOP learning curve and feel comfortable giving AOP a seat at the top table of application design. (At that point language-based solutions such as AspectJ may be far more attractive than they are today.)
Spring implements AOP using dynamic proxies (where an interface exists) or CGLIB byte code generation at runtime (which enables proxying of classes). Both these approaches work in any application server, or in a standalone environment.
Spring was the first AOP framework to implement the AOP Alliance interfaces (www.sourceforge.net/projects/aopalliance). These represent an attempt to define interfaces allowing interoperability of interceptors between AOP frameworks.
Spring integrates with AspectJ, providing the ability to seamlessly include AspectJ aspects into Spring applications . Since Spring 1.1 it has been possible to dependency inject AspectJ aspects using the Spring IoC container, just like any Java class. Thus AspectJ aspects can depend on any Spring-managed objects. The integration with the forthcoming AspectJ 5 release is still more exciting, with AspectJ set to provide the ability to dependency inject any POJO using Spring, based on an annotation-driven pointcut.
Because Spring advises objects at instance, rather than class loader, level, it is possible to use multiple instances of the same class with different advice, or use unadvised instances along with advised instances.
Perhaps the commonest use of Spring AOP is for declarative transaction management. This builds on the transaction abstraction described above, and can deliver declarative transaction management on any POJO. Depending on the transaction strategy, the underlying mechanism can be JTA, JDBC, Hibernate or any other API offering transaction management.
The following are the key differences from EJB CMT:
- Transaction management can be applied to any POJO. We recommend that business objects implement interfaces, but this is a matter of good programming practice, and is not enforced by the framework.
- Programmatic rollback can be achieved within a transactional POJO through using the Spring transaction API. We provide static methods for this, using ThreadLocal variables, so you don't need to propagate a context object such as an EJBContext to ensure rollback.
- You can define rollback rules declaratively. Whereas EJB will not automatically roll back a transaction on an uncaught application exception (only on unchecked exceptions, other types of Throwable and "system" exceptions), application developers often want a transaction to roll back on any exception. Spring transaction management allows you to specify declaratively which exceptions and subclasses should cause automatic rollback. Default behaviour is as with EJB, but you can specify automatic rollback on checked, as well as unchecked exceptions. This has the important benefit of minimizing the need for programmatic rollback, which creates a dependence on the Spring transaction API (as EJB programmatic rollback does on the EJBContext).
- Because the underlying Spring transaction abstraction supports savepoints if they are supported by the underlying transaction infrastructure, Spring's declarative transaction management can support nested transactions, in addition to the propagation modes specified by EJB CMT (which Spring supports with identical semantics to EJB). Thus, for example, if you have doing JDBC operations on Oracle, you can use declarative nested transactions using Spring.
- Transaction management is not tied to JTA. As explained above, Spring transaction management can work with different transaction strategies.
It's also possible to use Spring AOP to implement application-specific aspects. Whether or not you choose to do this depends on your level of comfort with AOP concepts, rather than Spring's capabilities, but it can be very useful. Successful examples we've seen include:
- Custom security interception, where the complexity of security checks required is beyond the capability of the standard J2EE security infrastructure. (Of course, before rolling your own security infrastructure, you should check the capabilities of Acegi Security for Spring, a powerful, flexible security framework that integrates with Spring using AOP, and reflects Spring's architectural approach.
- Debugging and profiling aspects for use during development
- Aspects that apply consistent exception handling policies in a single place
- Interceptors that send emails to alert administrators or users of unusual scenarios
Application-specific aspects can be a powerful way of removing the need for boilerplate code across many methods.
Spring AOP integrates transparently with the Spring BeanFactory concept. Code obtaining an object from a Spring BeanFactory doesn't need to know whether or not it is advised. As with any object, the contract will be defined by the interfaces the object implements.
The following XML stanza illustrates how to define an AOP proxy:
<bean id="myTest" class="org.springframework.aop.framework.ProxyFactoryBean">
<property name="proxyInterfaces">
<value>org.springframework.beans.ITestBean</value>
</property>
<property name="interceptorNames">
<list>
<value>txInterceptor</value>
<value>target</value>
</list>
</property>
</bean>
Note that the class of the bean definition is always the AOP framework's ProxyFactoryBean, although the type of the bean as used in references or returned by the BeanFactory getBean() method will depend on the proxy interfaces. (Multiple proxy methods are supported.) The "interceptorNames" property of the ProxyFactoryBean takes a list of String. (Bean names must be used rather than bean references, as new instances of stateful interceptors may need to be created if the proxy is a "prototype", rather than a singleton bean definition.) The names in this list can be interceptors or pointcuts (interceptors and information about when they should apply). The "target" value in the list above automatically creates an "invoker interceptor" wrapping the target object. It is the name of a bean in the factory that implements the proxy interface. The myTest bean in this example can be used like any other bean in the bean factory. For example, other objects can reference it via <ref> elements and these references will be set by Spring IoC.
There are a number of ways to set up proxying more concisely, if you don't need the full power of the AOP framework, such as using Java 5.0 annotations to drive transactional proxying without XML metadata, or the ability to use a single piece of XML to apply a consistent proxying strategy to many beans defined in a Spring factory.
It's also possible to construct AOP proxies programmatically without using a BeanFactory, although this is more rarely used:
TestBean target = new TestBean(); DebugInterceptor di = new DebugInterceptor(); MyInterceptor mi = new MyInterceptor(); ProxyFactory factory = new ProxyFactory(target); factory.addInterceptor(0, di); factory.addInterceptor(1, mi); // An "invoker interceptor" is automatically added to wrap the target ITestBean tb = (ITestBean) factory.getProxy();
We believe that it's generally best to externalize the wiring of applications from Java code, and AOP is no exception.
The use of AOP as an alternative to EJB (version 2 or above) for delivering enterprise services is growing in importance. Spring has successfully demonstrated the value proposition.
MVC web framework
Spring includes a powerful and highly configurable MVC web framework.
Spring's MVC model is most similar to that of Struts, although it is not derived from Struts. A Spring Controller is similar to a Struts Action in that it is a multithreaded service object, with a single instance executing on behalf of all clients. However, we believe that Spring MVC has some significant advantages over Struts. For example:
- Spring provides a very clean division between controllers, JavaBean models, and views.
- Spring's MVC is very flexible. Unlike Struts, which forces your Action and Form objects into concrete inheritance (thus taking away your single shot at concrete inheritance in Java), Spring MVC is entirely based on interfaces. Furthermore, just about every part of the Spring MVC framework is configurable via plugging in your own interface. Of course we also provide convenience classes as an implementation option.
- Spring, like WebWork, provides interceptors as well as controllers, making it easy to factor out behavior common to the handling of many requests.
- Spring MVC is truly view-agnostic. You don't get pushed to use JSP if you don't want to; you can use Velocity, XLST or other view technologies. If you want to use a custom view mechanism - for example, your own templating language - you can easily implement the Spring View interface to integrate it.
- Spring Controllers are configured via IoC like any other objects. This makes them easy to test, and beautifully integrated with other objects managed by Spring.
- Spring MVC web tiers are typically easier to test than Struts web tiers, due to the avoidance of forced concrete inheritance and explicit dependence of controllers on the dispatcher servlet.
- The web tier becomes a thin layer on top of a business object layer. This encourages good practice. Struts and other dedicated web frameworks leave you on your own in implementing your business objects; Spring provides an integrated framework for all tiers of your application.
As in Struts 1.1 and above, you can have as many dispatcher servlets as you need in a Spring MVC application.
The following example shows how a simple Spring Controller can access business objects defined in the same application context. This controller performs a Google search in its handleRequest() method:
public class GoogleSearchController implements Controller { private IGoogleSearchPort google; private String googleKey; public void setGoogle(IGoogleSearchPort google) { this.google = google; } public void setGoogleKey(String googleKey) { this.googleKey = googleKey; } public ModelAndView handleRequest( HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { String query = request.getParameter("query"); GoogleSearchResult result = // Google property definitions omitted... // Use google business object google.doGoogleSearch(this.googleKey, query, start, maxResults, filter, restrict, safeSearch, lr, ie, oe); return new ModelAndView("googleResults", "result", result); } }
In the prototype this code is taken from, IGoogleSearchPort is a GLUE web services proxy, returned by a Spring FactoryBean. However, Spring IoC isolates this controller from the underlying web services library. The interface could equally be implemented by a plain Java object, test stub, mock object, or EJB proxy, as discussed below. This controller contains no resource lookup; nothing except code necessary to support its web interaction.
Spring also provides support for data binding, forms, wizards and more complex workflow. A forthcoming article in this series will discuss Spring MVC in detail.
If your requirements are really complex, you should consider Spring Web Flow, a powerful framework that provides a higher level of abstraction for web flows than any traditional web MVC framework, and was discussed in a recent TSS article by its architect, Keith Donald.
A good introduction to the Spring MVC framework is Thomas Risberg's Spring MVC tutorial (http://www.springframework.org/docs/MVC-step-by-step/Spring-MVC-step-by-step.html). See also "Web MVC with the Spring Framework" (http://www.springframework.org/docs/web_mvc.html).
If you're happy with your favourite MVC framework, Spring's layered infrastructure allows you to use the rest of Spring without our MVC layer. We have Spring users who use Spring for middle tier management and data access but use Struts, WebWork, Tapestry or JSF in the web tier.
Implementing EJBs
If you choose to use EJB, Spring can provide important benefits in both EJB implementation and client-side access to EJBs.
It's now widely regarded as a best practice to refactor business logic into POJOs behind EJB facades. (Among other things, this makes it much easier to unit test business logic, as EJBs depend heavily on the container and are hard to test in isolation.) Spring provides convenient superclasses for session beans and message driven beans that make this very easy, by automatically loading a BeanFactory based on an XML document included in the EJB Jar file.
This means that a stateless session EJB might obtain and use a collaborator like this:
import org.springframework.ejb.support.AbstractStatelessSessionBean; public class MyEJB extends AbstractStatelessSessionBean implements MyBusinessInterface { private MyPOJO myPOJO; protected void onEjbCreate() { this.myPOJO = getBeanFactory().getBean("myPOJO"); } public void myBusinessMethod() { this.myPOJO.invokeMethod(); } }
Assuming that MyPOJO is an interface, the implementing class - and any configuration it requires, such as primitive properties and further collaborators - is hidden in the XML bean factory definition.
We tell Spring where to load the XML document via an environment variable definition named ejb/BeanFactoryPath in the standard ejb-jar.xml deployment descriptor, as follows:
<session> <ejb-name>myComponent</ejb-name> <local-home>com.test.ejb.myEjbBeanLocalHome</local-home> <local>com.mycom.MyComponentLocal</local> <ejb-class>com.mycom.MyComponentEJB</ejb-class> <session-type>Stateless</session-type> <transaction-type>Container</transaction-type> <env-entry> <env-entry-name>ejb/BeanFactoryPath</env-entry-name> <env-entry-type>java.lang.String</env-entry-type> <env-entry-value>/myComponent-ejb-beans.xml</env-entry-value></env-entry> </env-entry> </session>
The myComponent-ejb-beans.xml file will be loaded from the classpath: in this case, in the root of the EJB Jar file. Each EJB can specify its own XML document, so this mechanism can be used multiple times per EJB Jar file.
The Spring superclasses implement EJB lifecycle methods such as setSessionContext() and ejbCreate(), leaving the application developer to optionally implement the Spring onEjbCreate() method.
When EJB 3.0 is available in public draft, we will offer support for the use of the Spring IoC container to provide richer Dependency Injection semantics in that environment. We will also integrate the JSR-220 O/R mapping API with Spring as a supported data access API.
Using EJBs
Spring also makes it much easier to use, as well as implement EJBs. Many EJB applications use the Service Locator and Business Delegate patterns. These are better than spraying JNDI lookups throughout client code, but their usual implementations have significant disadvantages. For example:
- Typically code using EJBs depends on Service Locator or Business Delegate singletons, making it hard to test.
- In the case of the Service Locator pattern used without a Business Delegate, application code still ends up having to invoke the create() method on an EJB home, and deal with the resulting exceptions. Thus it remains tied to the EJB API and the complexity of the EJB programming model.
- Implementing the Business Delegate pattern typically results in significant code duplication, where we have to write numerous methods that simply call the same method on the EJB.
For these and other reasons, traditional EJB access, as demonstrated in applications such as the Sun Adventure Builder and OTN J2EE Virtual Shopping Mall, can reduce productivity and result in significant complexity.
Spring steps beyond this by introducing codeless business delegates. With Spring you'll never need to write another Service Locator, another JNDI lookup, or duplicate methods in a hand-coded Business Delegate unless you're adding real value.
For example, imagine that we have a web controller that uses a local EJB. We'll follow best practice and use the EJB Business Methods Interface pattern, so that the EJB's local interface extends a non EJB-specific business methods interface. (One of the main reasons to do this is to ensure that synchronization between method signatures in local interface and bean implementation class is automatic.) Let's call this business methods interface MyComponent. Of course we'll also need to implement the local home interface and provide a bean implementation class that implements SessionBean and the MyComponent business methods interface.
With Spring EJB access, the only Java coding we'll need to do to hook up our web tier controller to the EJB implementation is to expose a setter method of type MyComponent on our controller. This will save the reference as an instance variable like this:
private MyComponent myComponent; public void setMyComponent(MyComponent myComponent) { this.myComponent = myComponent; }
We can subsequently use this instance variable in any business method.
Spring does the rest of the work automatically, via XML bean definition entries like this. LocalStatelessSessionProxyFactoryBean is a generic factory bean that can be used for any EJB. The object it creates can be cast by Spring to the MyComponent type automatically.
<bean id="myComponent" class="org.springframework.ejb.access.LocalStatelessSessionProxyFactoryBean"> <property name="jndiName" value="myComponent" /> <property name="businessInterface" value="com.mycom.MyComponent" /> </bean> <bean id="myController" class = "com.mycom.myController" > <property name="myComponent" ref="myComponent" /> </bean>
There's a lot of magic happening behind the scenes, courtesy of the Spring AOP framework, although you aren't forced to work with AOP concepts to enjoy the results. The "myComponent" bean definition creates a proxy for the EJB, which implements the business method interface. The EJB local home is cached on startup, so there's normally only a single JNDI lookup. (There is also support for retry on failure, so an EJB redeployment won't cause the client to fail.) Each time the EJB is invoked, the proxy invokes the create() method on the local EJB and invokes the corresponding business method on the EJB.
The myController bean definition sets the myController property of the controller class to this proxy.
This EJB access mechanism delivers huge simplification of application code:
- The web tier code has no dependence on the use of EJB. If we want to replace this EJB reference with a POJO or a mock object or other test stub, we could simply change the myComponent bean definition without changing a line of Java code
- We haven't had to write a single line of JNDI lookup or other EJB plumbing code as part of our application.
We can also apply the same approach to remote EJBs, via the similar org.springframework.ejb.access.SimpleRemoteStatelessSessionProxyFactoryBean factory bean. However, it's trickier to conceal the RemoteExceptions on the business methods interface of a remote EJB. (Spring does let you do this, if you wish to provide a client-side service interface that matches the EJB remote interface but without the "throws RemoteException" clause in the method signatures.)
Testing
As you've probably gathered, I and the other Spring developers are firm believers in the importance of comprehensive unit testing. We believe that it's essential that frameworks are thoroughly unit tested, and that a prime goal of framework design should be to make applications built on the framework easy to unit test.
Spring itself has an excellent unit test suite. We've found the benefits of test first development to be very real on this project. For example, it has made working as an internationally distributed team extremely efficient, and users comment that CVS snapshots tend to be stable and safe to use.
We believe that applications built on Spring are very easy to test, for the following reasons:
- IoC facilitates unit testing
- Applications don't contain plumbing code directly using J2EE services such as JNDI, which is typically hard to test
- Spring bean factories or contexts can be set up outside a container
The ability to set up a Spring bean factory outside a container offers interesting options for the development process. In several web application projects using Spring, work has started by defining the business interfaces and integration testing their implementation outside a web container. Only after business functionality is substantially complete is a thin layer added to provide a web interface.
Since Spring 1.1.1, Spring has provided powerful and unique support for a form of integration testing outside the deployed environment. This is not intended as a substitute for unit testing or testing against the deployed environment. However, it can significantly improve productivity.
The org.springframework.test package provides valuable superclasses for integration tests using a Spring container, but not dependent on an application server or other deployed environment. Such tests can run in JUnit--even in an IDE--without any special deployment step. They will be slower to run than unit tests, but much faster to run than Cactus tests or remote tests relying on deployment to an application server. Typically it is possible to run hundreds of tests hitting a development database--usually not an embedded database, but the product used in production--within seconds, rather than minutes or hours. Such tests can quickly verify correct wiring of your Spring contexts, and data access using JDBC or ORM tool, such as correctness of SQL statements. For example, you can test your DAO implementation classes.
The enabling functionality in the org.springframework.test package includes:
- The ability to populate JUnit test cases via Dependency Injection. This makes it possible to reuse Spring XML configuration when testing, and eliminates the need for custom setup code for tests.
- The ability to cache container configuration between test cases, which greatly increases performance where slow-to-initialize resources such as JDBC connection pools or Hibernate SessionFactories are concerned.
- Infrastructure to create a transaction around each test method and roll it back at the conclusion of the test by default. This makes it possible for tests to perform any kind of data access without worrying about the effect on the environments of other tests. In my experience across several complex projects using this functionality, the productivity and speed gain of such a rollback-based approach is very significant.
Who's using Spring?
There are many production applications using Spring. Users include investment and retail banking organizations, well-known dotcoms, global consultancies, academic institutions, government departments, defence contractors, several airlines, and scientific research organizations (including CERN).
Many users use all parts of Spring, but some use components in isolation. For example, a number of users begin by using our JDBC or other data access functionality.
Roadmap
Since the first version of this article, in October 2003, Spring has progressed through its 1.0 final release (March 2004) through version 1.l (September 2004) to 1.2 final (May 2005). We believe in a philosophy of "release early, release often," so maintenance releases and minor enhancements are typically released every 4-6 weeks.
Since that time enhancements include:
- The introduction of a remoting framework supporting multiple protocols including RMI and various web services protocols
- Support for Method Injection and other IoC container enhancements such as the ability to manage objects obtained from calls to static or instance factory methods
- Integration with more data access technologies, including TopLink and Hibernate 3 as well as Hibernate 2 in the recent 1.2 release
- Support for declarative transaction management configured by Java 5.0 annotations (1.2), eliminating the need for XML metadata to identify transactional methods
- Support for JMX management of Spring-managed objects (1.2).
- Integration with Jasper Reports, the Quartz scheduler and AspectJ
- Integration with JSF as a web layer technology
We intend to continue with rapid innovation and enhancement. The next major release will be 1.3 (final release expected Q3, 2005). Planned enhancements include:
- XML configuration enhancements (planned for release 1.3), which will allow custom XML tags to extend the basic Spring configuration format by defining one or more objects in a single, validated tag. This not only has the potential to simplify typical configurations significantly and reduce configuration errors, but will be ideal for developers of third-party products that are based on Spring.
- Integration of Spring Web Flow into the Spring core (planned for release 1.3)
- Support for dynamic reconfiguration of running applications
- Support for the writing of application objects in languages other than Java, such as Groovy, Jython or other scripting languages running on the Java platform. Such objects will benefit from the full services of the Spring IoC container and will allow dynamic reloading when the script changes, without affecting objects that were given references to them by the IoC container.
As an agile project, Spring is primarily driven by user requirements. So we don't develop features that no one has a use for, and we listen carefully to our user community.
Spring Modules is an associated project, led by Rob Harrop of Interface21, which extends the reach of the Spring platform to areas that are not necessarily integral to the Spring core, while still valuable to many users. This project also serves as an incubator, so some of this functionality will probably eventually migrate into the Spring core. Spring Modules presently includes areas such as integration with the Lucene search engine and OSWorkflow workflow engine, a declarative, AOP-based caching solution, and integration with the Commons Validator framework.
Interestingly, although the first version of this article was published six months before the release of Spring 1.0 final, almost all the code and configuration examples would still work unchanged in today's 1.2 release. We are proud of our excellent record on backward compatibility. This demonstrates the ability of Dependency Injection and AOP to deliver a non-invasive API, and also indicates the seriousness with which we take our responsibility to the community to provide a stable framework to run vital applications.
Summary
Spring is a powerful framework that solves many common problems in J2EE. Many Spring features are also usable in a wide range of Java environments, beyond classic J2EE.
Spring provides a consistent way of managing business objects and encourages good practices such as programming to interfaces, rather than classes. The architectural basis of Spring is an Inversion of Control container based around the use of JavaBean properties. However, this is only part of the overall picture: Spring is unique in that it uses its IoC container as the basic building block in a comprehensive solution that addresses all architectural tiers.
Spring provides a unique data access abstraction, including a simple and productive JDBC framework that greatly improves productivity and reduces the likelihood of errors. Spring's data access architecture also integrates with TopLink, Hibernate, JDO and other O/R mapping solutions.
Spring also provides a unique transaction management abstraction, which enables a consistent programming model over a variety of underlying transaction technologies, such as JTA or JDBC.
Spring provides an AOP framework written in standard Java, which provides declarative transaction management and other enterprise services to be applied to POJOs or - if you wish - the ability to implement your own custom aspects. This framework is powerful enough to enable many applications to dispense with the complexity of EJB, while enjoying key services traditionally associated with EJB.
Spring also provides a powerful and flexible MVC web framework that is integrated into the overall IoC container.
More information
See the following resources for more information about Spring:
- A more recent discussion of the Spring framework by Spring guru and author of Spring Roo in Action, Ken Rimple, is now available
- Interface21 offers a Core Spring training course - http://www.springframework.com/training.
- Expert One-on-One J2EE Design and Development (Rod Johnson, Wrox, 2002). Although Spring has evolved and improved significantly since the book's publication, it's still an excellent place to go to understand Spring's motivation.
- J2EE without EJB (Rod Johnson with Juergen Hoeller, Wrox, 2004). Sequel to J2EE Design and Development that discusses the rationale for Spring and the lightweight container architecture it enables.
- The Spring Reference Manual. The printable form is over 240 pages as of Spring 1.2. Spring also ships with several sample applications that illustrate best practice and can be used as templates for your own applications.
- Pro Spring: In-depth Spring coverage by core developer Rob Harrop.
- Spring: A Developer's Notebook : Introduction to Spring by Bruce Tate and Justin Gehtland.
- Spring Framework home page: http://www.springframework.org/. This includes Javadoc and several tutorials.
- Forums and downloads on Sourceforge.
- Spring-developer mailing list.
We pride ourselves on excellent response rates and a helpful attitude to queries on the forms and mailing lists. We hope to welcome you into our community soon!
About the Author
Rod Johnson has almost ten years experience as a Java developer and architect and has worked with J2EE since the platform emerged. He is the author of the best-selling Expert One-on-One J2EE Design and Development (Wrox, 2002), and J2EE without EJB (Wrox, 2004, with Juergen Hoeller) and has contributed to several other books on J2EE. Rod serves on two Java specification committees and is a regular conference speaker. He is CEO of Interface21, an international consultancy that leads Spring Framework development and offers expert services on the Spring Framework and J2EE in general.
Recommended Books for Learning Spring
Spring in Action ~ Craig Walls
Spring Recipes: A Problem-Solution Approach ~ Gary Mak
Professional Java Development with the Spring Framework ~ Rod Johnson PhD
Pro Java EE Spring Patterns: Best Practices and Design Strategies ~ Dhrubojyoti Kayal






